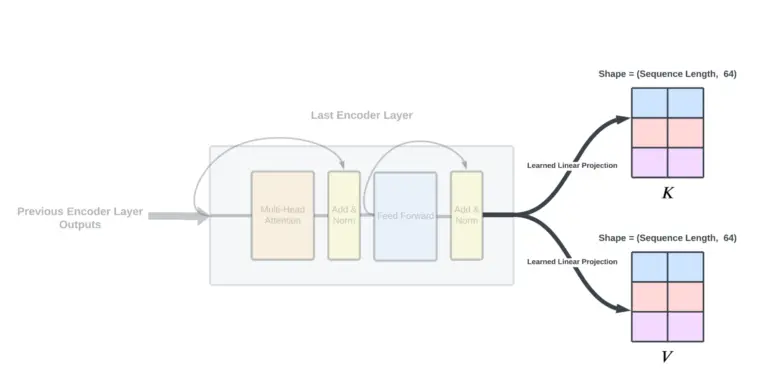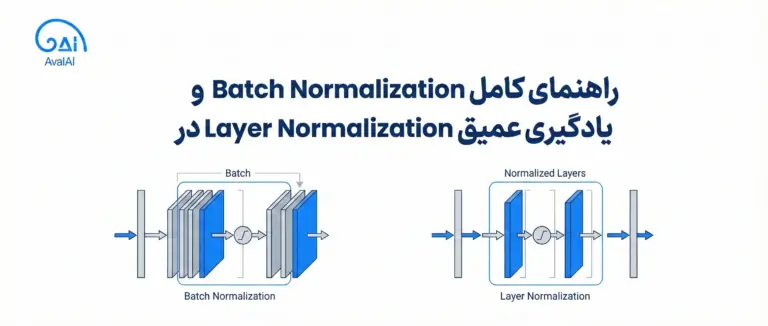
پیشبینی جهتهای تحقیقاتی آینده هوش مصنوعی (AI) با استفاده از تکنیکهای یادگیری ماشین میتواند پیشرفت علم را تسریع کند. تعداد انتشارات علمی در زمینه AI به طور تصاعدی در حال رشد است و پیگیری پیشرفت برای محققان انسانی چالش برانگیز است.
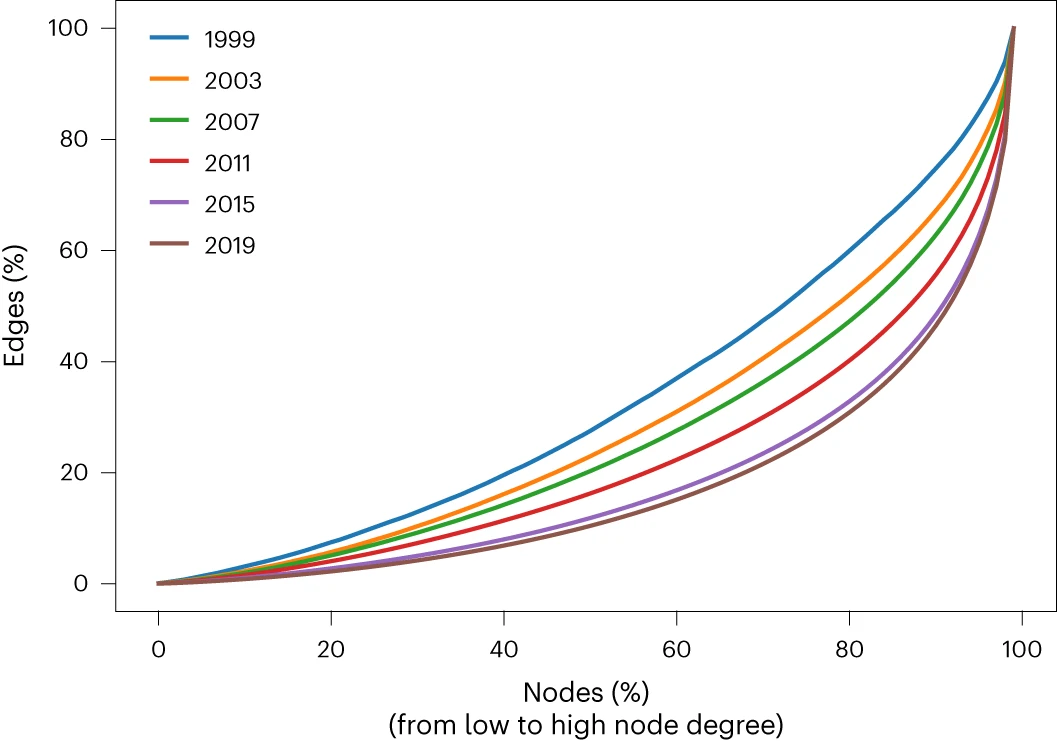
در این مقاله، ما یک معیار مبتنی بر نمودار مبتنی بر داده های دنیای واقعی را معرفی می کنیم – معیار Science4Cast، که هدف آن پیش بینی وضعیت آینده یک شبکه معنایی در حال تکامل AI است. ما از بیش از 143000 مقاله تحقیقاتی استفاده می کنیم و یک شبکه با بیش از 64000 گره مفهومی ایجاد می کنیم.
ما چندین روش متنوع را برای مقابله با این کار ارائه می دهیم، از روش های آماری خالص تا روش های یادگیری خالص.
این نتایج نشان دهنده پتانسیل بزرگی است که می تواند برای رویکردهای صرفاً یادگیری ماشین بدون دانش انسانها توسعه پیدا کند. در نهایت، پیشبینی بهتر جهتهای تحقیقاتی جدید در آینده، جزء حیاتی ابزارهای پیشنهادی تحقیقاتی پیشرفتهتر خواهد بود.
یادگیری ماشین
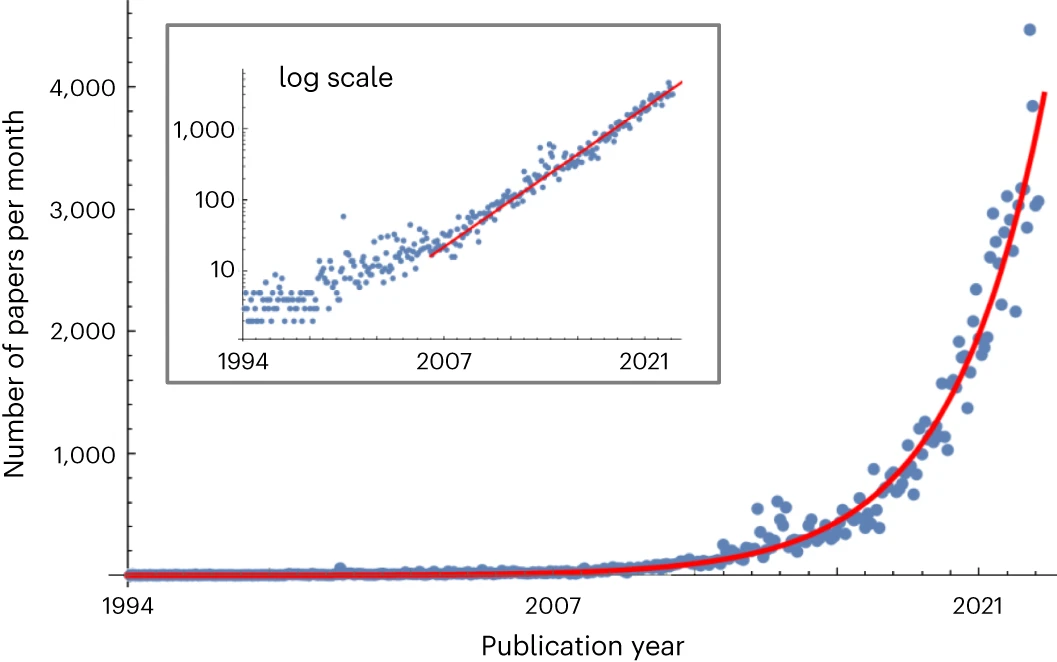
حجم ادبیات علمی به سرعت در حال افزایش است. این امر به ویژه در زمینه هوش مصنوعی و یادگیری ماشینی صادق است، جایی که تعداد مقالات هر ماه دو برابر می شود. این رشد سریع، سازماندهی و کشف ارتباطات جدید را دشوار می کند.
ما یک برنامه کامپیوتری را تصور می کنیم که می تواند به طور خودکار ادبیات زبانی هوش مصنوعی را پردازش کند. این برنامه می تواند ایده های پژوهشی جدیدی را شناسایی کند که فراتر از دانش فردی و مرزهای بین رشته ای است. این برنامه می تواند بهره وری محققان هوش مصنوعی را بهبود بخشد، راه های جدیدی برای تحقیق باز کند و به پیشرفت در این زمینه کمک کند.
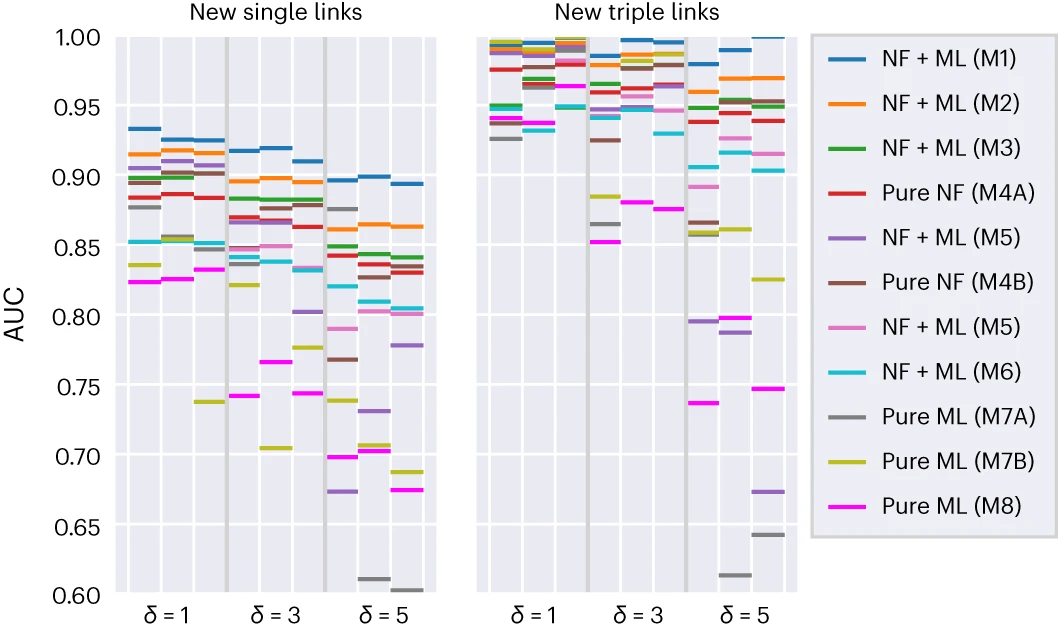
ما روشها را بر اساس عملکرد آنها رتبهبندی کردیم. مدل M1 بهترین عملکرد را داشت، در حالی که مدل M8 کمتاثیرترین بود. مدلهای M4 و M7 به دو زیرمدل تقسیم شدند که بر روی ویژگیها یا انتخاب تعبیه تمرکز داشتند.
مدل M1:
این مدل از تقویت گرادیان مبتنی بر درخت و شبکههای عصبی گراف استفاده میکند. برای ثبت مرکزیتهای گره، مجاورت و تکامل زمانی، از مهندسی ویژگیهای گسترده استفاده میشود.
یک ماشین تقویت گرادیان نور (LightGBM) با نظمدهی شدید برای مبارزه با بیشبرازش استفاده میشود. این به این دلیل است که مدلهای پیشبینی پیوند معمولاً با کمبود مثالهای مثبت مواجه میشوند.
یک شبکه عصبی گراف آگاه از زمان، نمایش گرههای پویا را یاد میگیرد. این به مدل کمک میکند تا روندهای زمانی را در شبکه معنایی درک کند.
مدل M2:
این مدل از ویژگیهای گره و لبه برای پیشبینی احتمالات تشکیل پیوند استفاده میکند. ویژگیهای گره محبوبیت را اندازهگیری میکنند و ویژگیهای لبه شباهت را اندازهگیری میکنند.
یک پرسپترون چند لایه با فعالسازی واحد خطی اصلاحشده (ReLU) برای یادگیری استفاده میشود. این فعالسازی به مدل کمک میکند تا از نواحی غیرخطی در دادهها یاد بگیرد.
برای حل مشکل شروع سرد، از انتساب ویژگی استفاده میشود. این به مدل کمک میکند تا حتی زمانی که دادههای آموزشی کمی وجود دارد، عملکرد خوبی داشته باشد.
مدل M3:
این مدل ویژگیهای گره دستساز را در چند عکس فوری ثبت میکند. سپس از یک حافظه کوتاهمدت بلند مدت (LSTM) برای یادگیری وابستگیهای زمانی استفاده میکند.
ویژگیها به گونهای انتخاب میشوند که در عین داشتن هزینه محاسباتی بسیار آموزنده باشند. پیکربندی نهایی از مرکزیت درجه، درجه همسایگان و همسایگان مشترک به عنوان ویژگی استفاده میکند.
LSTM از شبکههای عصبی کاملاً متصل بهتر عمل میکند. این به این دلیل است که LSTM میتواند وابستگیهای طولانیمدت در دادهها را درک کند.
مدل M4:
این مدل از دو روش آماری ساده، پیوست ترجیحی و همسایگان مشترک استفاده می کند.
- پیوست ترجیحی بر اساس درجات گره است. این بدان معناست که احتمال تشکیل پیوند بین دو گره بیشتر است اگر هر دو گره درجه بالایی داشته باشند.
- همسایگان مشترک به تعداد همسایه های مشترک متکی هستند. این بدان معناست که احتمال تشکیل پیوند بین دو گره بیشتر است اگر آنها تعداد زیادی همسایه مشترک داشته باشند.
هر دو روش از نظر محاسباتی ارزان هستند و با برخی از مدلهای مبتنی بر یادگیری عملکرد رقابتی دارند.
مدل M5:
این مدل از ویژگیهای نمودار مرتبه اول و تحلیل مؤلفههای اصلی (PCA) استفاده می کند.
- ویژگیهای نمودار مرتبه اول ویژگیهایی هستند که مستقیماً از شبکه معنایی استخراج میشوند. این ویژگیها شامل درجه گره، درجه همسایگان و همسایگان مشترک هستند.
- PCA یک روش آماری است که میتواند تعداد زیادی ویژگی را به تعداد کمتری از ویژگیهای اصلی کاهش دهد. این به مدل کمک میکند تا از دادههای آموزشی به طور موثرتری استفاده کند.
یک طبقهبندی جنگل تصادفی روی مجموعه داده متعادل آموزش داده شده است تا پیوندهای جدید را پیشبینی کند.
مدل M6:
این مدل از 15 ویژگی دست ساز استفاده می کند.
- این ویژگیها شامل ویژگیهای گره، ویژگیهای لبه و ویژگیهای وابستگی زمانی هستند.
یک شبکه عصبی چهار لایه برای پیشبینی احتمال تشکیل پیوند بین جفت گره ها استفاده می شود.
مدل M7:
این مدل از تعبیههای گره خودکار استفاده می کند.
- تعبیههای گره یک نمایش معنایی از گرهها هستند.
تعبیهها به یک شبکه عصبی با دو لایه پنهان برای پیشبینی پیوند وارد میشوند.
مدل M8:
این مدل از ترانسفورماتورها برای یادگیری ویژگیها استفاده می کند.
- ترانسفورماتورها یک نوع شبکه عصبی هستند که میتوانند از وابستگیهای طولانیمدت در دادهها یاد بگیرند.
تعبیههای Node2vec برای عکسهای فوری مختلف از ماتریس مجاورت تولید میشوند. سپس یک مدل ترانسفورماتور برای یادگیری ویژگیها از این تعبیهها استفاده میشود. یک شبکه دو لایه ReLU برای طبقه بندی استفاده می شود.
در این مقاله، ما چندین روش مختلف برای پیشبینی پیوندهای جدید در یک شبکه معنایی را بررسی کردیم. نتایج نشان داد که روشهای ترکیبی که از ویژگیهای دستساز و مدلهای یادگیری ماشین استفاده میکنند، بالاترین عملکرد را دارند.
این یافتهها نشان میدهد که پیشبینی پیوندهای جدید در شبکههای معنایی یک کار چالش برانگیز است که به ترکیبی از دانش و هوش مصنوعی نیاز دارد.
در آینده، تحقیقات بیشتری برای بهبود دقت و کارایی مدلهای پیشبینی پیوند انجام خواهد شد. این تحقیقات ممکن است شامل موارد زیر باشد:
- توسعه روشهای جدید برای استخراج ویژگیهای معنایی از شبکههای معنایی
- بهبود مدلهای یادگیری ماشین برای یادگیری از دادههای شبکه معنایی
- توسعه روشهای جدید برای ارزیابی عملکرد مدلهای پیشبینی پیوند
این تحقیقات میتواند منجر به توسعه ابزارهای جدیدی شود که به کاربران کمک میکنند تا روندهای جدید در شبکههای معنایی را شناسایی کنند و فرصتهای جدیدی را برای همکاری و نوآوری ایجاد کنند.
هوش مصنوعی و یادگیری ماشین: تعاریف و مفاهیم
هوش مصنوعی به سیستمهایی اطلاق میشود که قادر به انجام وظایفی هستند که به طور معمول نیاز به هوش انسانی دارند، مانند تشخیص گفتار، تصمیمگیری، و ترجمه زبان. یادگیری ماشین یکی از زیرمجموعههای هوش مصنوعی است که به سیستمها اجازه میدهد از دادهها یاد بگیرند و عملکرد خود را بدون نیاز به برنامهریزی صریح بهبود بخشند.
نقش یادگیری ماشین در پیشبینی آینده هوش مصنوعی
یادگیری ماشین به عنوان یکی از ابزارهای کلیدی در توسعه هوش مصنوعی، نقش مهمی در پیشبینی آینده این فناوری دارد. با استفاده از الگوریتمهای پیچیده و تحلیل دادههای بزرگ، یادگیری ماشین میتواند الگوها و روندهای پنهان را شناسایی کند و پیشبینیهای دقیقی ارائه دهد.
تحلیل دادهها و پیشبینی روندها
یکی از کاربردهای اصلی یادگیری ماشین در پیشبینی آینده هوش مصنوعی، تحلیل دادهها و شناسایی روندها است. با تحلیل دادههای گذشته و مقایسه آنها با دادههای جدید، الگوریتمهای یادگیری ماشین میتوانند پیشبینیهایی در مورد تغییرات آینده ارائه دهند. به عنوان مثال، این فناوری میتواند در پیشبینی روندهای بازار سهام، تغییرات آب و هوا، و حتی تغییرات چهره افراد در آینده مورد استفاده قرار گیرد.
بهبود فرآیندهای تصمیمگیری
یادگیری ماشین میتواند به بهبود فرآیندهای تصمیمگیری کمک کند. با استفاده از الگوریتمهای یادگیری ماشین، سیستمها میتوانند تصمیمات بهتری بگیرند و عملکرد خود را بهبود بخشند. این امر میتواند در حوزههای مختلفی از جمله پزشکی، مالی، و صنعت مورد استفاده قرار گیرد.
تاثیرات یادگیری ماشین بر هوش مصنوعی آینده
تاثیرات بسیار گسترده و عمیق است. این فناوری میتواند به توسعه سیستمهای هوشمندتر و کارآمدتر کمک کند و امکانات جدیدی را فراهم آورد.
توسعه سیستمهای خودکار
یکی از تاثیرات مهم یادگیری ماشین بر هوش مصنوعی آینده، توسعه سیستمهای خودکار است. این سیستمها میتوانند وظایف مختلفی را به صورت خودکار انجام دهند و نیاز به دخالت انسانی را کاهش دهند. به عنوان مثال، خودروهای خودران یکی از نمونههای بارز این سیستمها هستند که با استفاده از یادگیری ماشین قادر به رانندگی خودکار هستند.
بهبود سیستمهای تشخیص
یادگیری ماشین میتواند به بهبود سیستمهای تشخیص کمک کند. این سیستمها میتوانند در تشخیص بیماریها، تشخیص چهره، و حتی تشخیص تقلب در معاملات مالی مورد استفاده قرار گیرند. با استفاده از الگوریتمهای پیشرفته یادگیری ماشین، دقت و کارایی این سیستمها بهبود مییابد.
افزایش امنیت و حریم خصوصی
یادگیری ماشین میتواند به افزایش امنیت و حریم خصوصی کمک کند. با تحلیل دادهها و شناسایی الگوهای مشکوک، این فناوری میتواند به شناسایی تهدیدات امنیتی و حفاظت از اطلاعات شخصی کمک کند. به عنوان مثال، سیستمهای امنیتی مبتنی بر یادگیری ماشین میتوانند حملات سایبری را شناسایی و از آنها جلوگیری کنند.
نتیجهگیری
پیشبینی آینده هوش مصنوعی با استفاده از یادگیری ماشین نشان میدهد که این فناوریها نقش بسیار مهمی در توسعه و تحول آینده خواهند داشت. با تحلیل دادهها، بهبود فرآیندهای تصمیمگیری، و توسعه سیستمهای خودکار، یادگیری ماشین میتواند به توسعه هوش مصنوعی کمک کند و امکانات جدیدی را فراهم آورد. تاثیرات یادگیری ماشین بر هوش مصنوعی آینده بسیار گسترده و عمیق است و میتواند به بهبود زندگی انسانها و افزایش کارایی سیستمها کمک کند.