مدل ترنسفورمر یا مدل انتقالی، یک مدل یادگیری عمیق است که از مکانیزم توجه استفاده میکند و در سال ۲۰۱۷ برای اولین بار معرفی شد. این مدل بهطور معمول در تحقیقات پردازش زبان طبیعی (NLP) مورد استفاده قرار میگیرد. در این توضیحات، تلاش شده است که به طور ساده مفهوم مدل ترنسفورمر را شرح داده شود.
مدل ترنسفورمر
مدل ترنسفورمر یک معماری شبکه عصبی است که برای پردازش زبان طبیعی (NLP) طراحی شده است. این مدل از مکانیزم توجه (Attention Mechanism) استفاده میکند تا ارتباط بین واحدهای مختلف ورودی را به طور مستقیم مدلسازی کند. این امر به ترانسفورمرها امکان میدهد تا بدون نیاز به یک حافظه طولانی مدت، ترتیب واحدهای ورودی را درک کنند.
ترانسفورمرها در طیف وسیعی از وظایف NLP، از جمله ترجمه ماشینی، خلاصهسازی متن، پرسش و پاسخ و تولید متن، عملکرد بسیار خوبی داشتهاند.
ساختار مدل ترنسفورمر
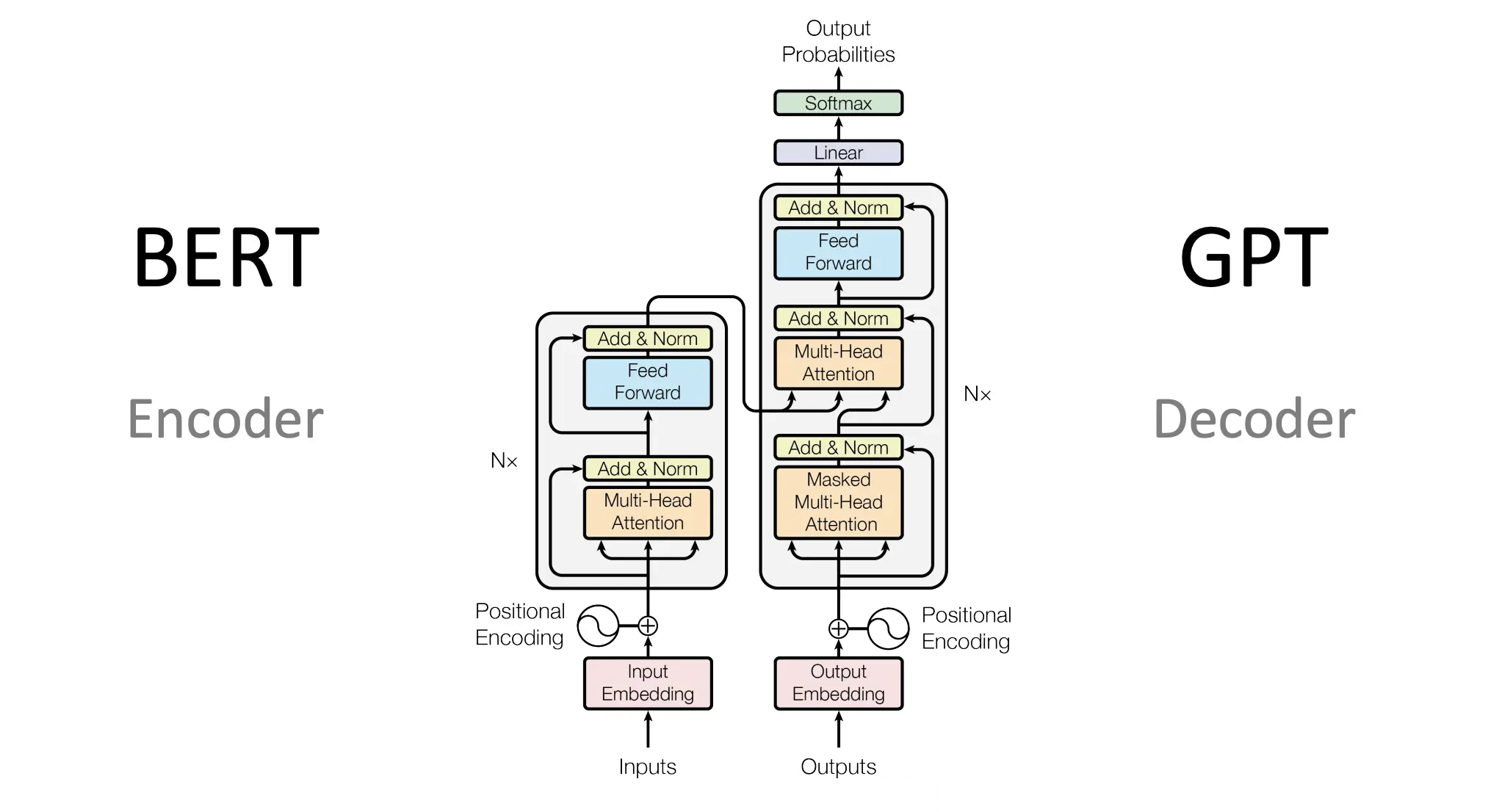
ترانسفورمر از دو بخش اصلی تشکیل شده است: رمزگذار (Encoder) و رمزگشا (Decoder)
رمزگذار (Encoder)
رمزگذار وظیفه تبدیل ورودی به یک کد داخلی را بر عهده دارد. این کد داخلی میتواند برای اهداف مختلفی مورد استفاده قرار گیرد، مانند ترجمه زبان، خلاصهنویسی متن، یا پاسخ به سوالات.
رمزگذار از یک شبکه عصبی پیچیده تشکیل شده است که از چندین لایه تشکیل شده است. هر لایه از یک آرایه از واحدهای پردازشی تشکیل شده است که به آنها نورون گفته میشود. نورونها با یکدیگر ارتباط برقرار میکنند و اطلاعات را از یکدیگر دریافت میکنند.
عملکرد رمزگذار به این صورت است که هر لایه از واحدهای پردازشی، ورودی دریافت شده از لایه قبلی را پردازش میکند و یک خروجی تولید میکند. این خروجی سپس به لایه بعدی منتقل میشود. این فرآیند تا زمانی که به آخرین لایه رمزگذار ادامه مییابد.
آخرین لایه رمزگذار کد داخلی را تولید میکند. این کد داخلی یک نمایش خلاصه شده از ورودی است.
رمزگشا (Decoder)
رمزگشا وظیفه تبدیل کد داخلی به خروجی را بر عهده دارد. خروجی میتواند یک متن، یک زبان، یا یک پاسخ به سوال باشد.
رمزگشا نیز از یک شبکه عصبی پیچیده تشکیل شده است که از چندین لایه تشکیل شده است. هر لایه از یک آرایه از واحدهای پردازشی تشکیل شده است.
عملکرد رمزگشا به این صورت است که اولین لایه کد داخلی را دریافت میکند و یک خروجی تولید میکند. این خروجی سپس به لایه بعدی منتقل میشود. این فرآیند تا زمانی که به آخرین لایه رمزگشا ادامه مییابد.
آخرین لایه رمزگشا خروجی نهایی را تولید میکند.
ارتباط بین رمزگذار و رمزگشا
رمزگذار و رمزگشا از طریق یک کد میانی با یکدیگر ارتباط برقرار میکنند. این کد میانی یک نمایش خلاصه شده از ورودی است.
رمزگذار کد میانی را تولید میکند و آن را به رمزگشا منتقل میکند. رمزگشا از کد میانی برای تولید خروجی استفاده میکند.
یک مثال ساده
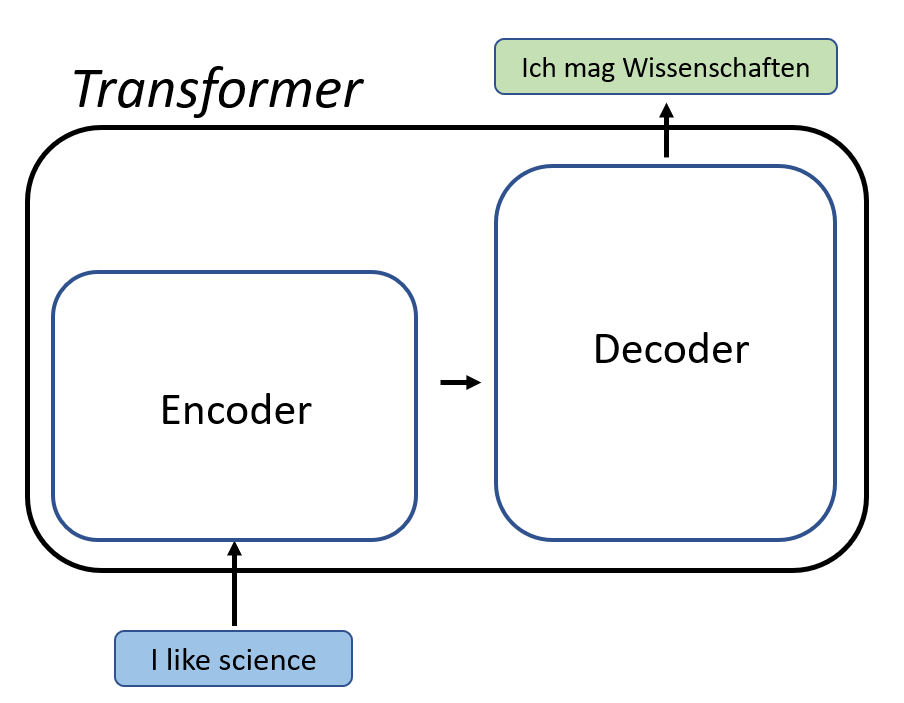
فرض کنید میخواهید از یک مدل ترنسفورماتور برای ترجمه یک جمله از انگلیسی به فرانسوی استفاده کنید.
- رمزگذار جمله انگلیسی را به یک نمایش برداری از توکنها تبدیل میکند.
- رمزگشا از نمایش برداری رمزگذار برای تولید ترجمه فرانسوی جمله استفاده میکند.
- در طول این فرآیند، رمزگذار و رمزگشا از مکانیزم توجه برای تمرکز بر کلمات مرتبط در هر دو زبان استفاده میکنند.
الگوریتم آموزش ترانسفورمر
ترانسفورمر با استفاده از یک الگوریتم یادگیری ماشین به نام یادگیری نظارتی آموزش مییابد. در یادگیری نظارتی، یک مجموعه داده از ورودیها و خروجیهای صحیح به مدل داده میشود. مدل سپس سعی میکند الگوریتمی را بیاموزد که بتواند از ورودیها، خروجیهای صحیح را تولید کند.
ترانسفورمرها از مجموعه دادهای شامل ورودیها و خروجیهای صحیح برای یک کار خاص آموزش میبینند. برای مثال، در ترجمه زبان، مجموعه داده شامل جفتهایی از جملههای منبع و جملههای هدف است.
ترانسفورمر با استفاده از یک الگوریتم به نام backpropagation آموزش مییابد. این الگوریتم خطا را در خروجی مدل اندازهگیری میکند و سپس تغییراتی را در وزنهای مدل ایجاد میکند تا خطا کاهش یابد.
این فرآیند تا زمانی که خطا به سطح قابل قبولی برسد ادامه مییابد.
جزئیات ساختار یک مدل ترنسفورمر
در پردازش زبانهای طبیعی، اولین قدم تبدیل کلمات ورودی به بردارهای معنایی است. این کار را الگوریتمهای تعبیه کلمات (Word Embedding) انجام میدهند.
در مدل ترنسفورمر، تعبیه کلمات فقط در اولین انکودر صورت میگیرد. سایر انکودرها، بردارهای خروجی انکودر قبلی را دریافت میکنند. اندازه این بردارها معمولاً 512 بیت است.
بعد از تعبیه، هر کلمه بهطور موازی از دو زیرلایه انکودر عبور میکند. این زیرلایهها عبارتند از:
- لایه Self-Attention: این لایه به مدل کمک میکند تا ارتباط بین کلمات مختلف در یک جمله را درک کند.
- لایه شبکه عصبی پیشخور: این لایه به مدل کمک میکند تا ویژگیهای مهم کلمات را استخراج کند.
در مدل ترنسفورمر، ترتیب کلمات ورودی با استفاده از انکودینگ موقعیتی (Positional Encoding) مدنظر قرار میگیرد. انکودینگ موقعیتی یک بردار اضافی است که به هر بردار تعبیهی کلمه اضافه میشود. این بردار اطلاعات مربوط به موقعیت کلمه در جمله را ذخیره میکند.
مجموعه زیرلایههای یک انکودر
یک انکودر در مدل ترنسفورمر از دو زیرلایه تشکیل شده است:
- لایه Self-Attention: این لایه به مدل کمک میکند تا ارتباط بین کلمات مختلف در یک جمله را درک کند.
- لایه شبکه عصبی پیشخور: این لایه به مدل کمک میکند تا ویژگیهای مهم کلمات را استخراج کند.
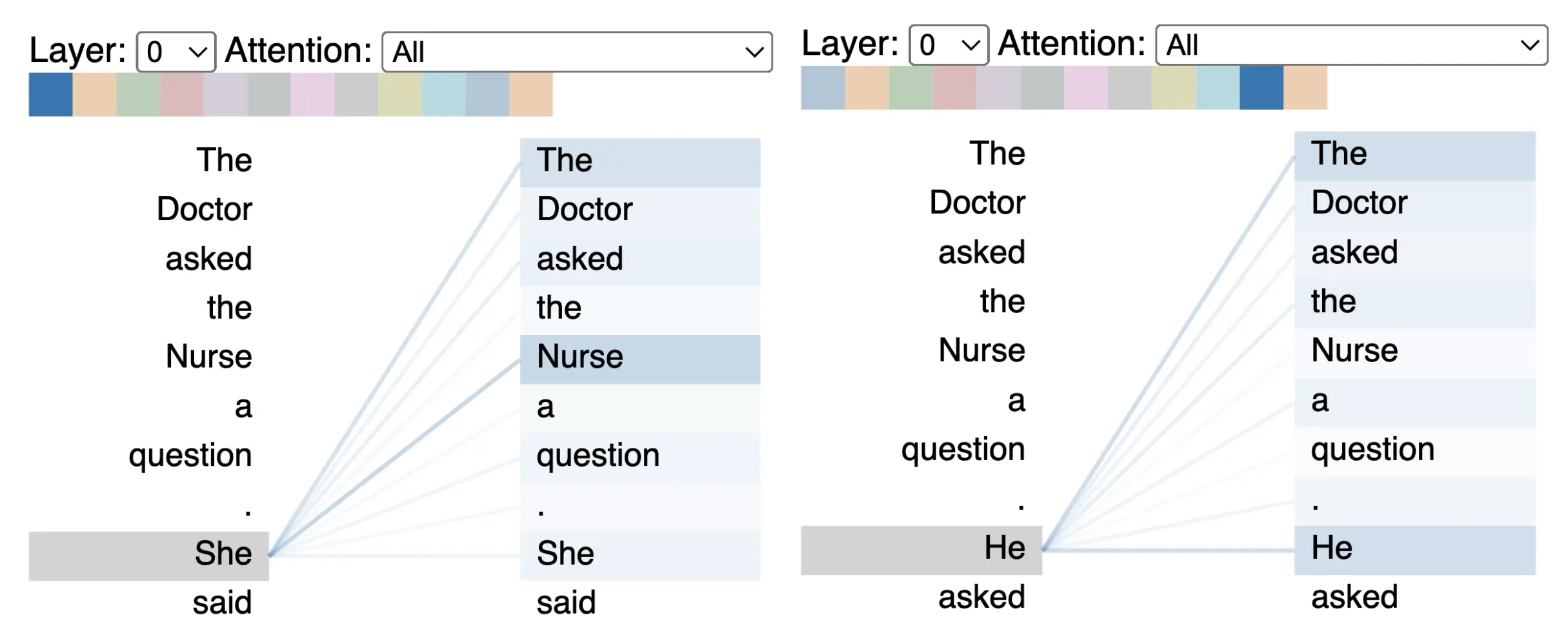
لایه Self-Attention
لایه Self-Attention یکی از اجزای کلیدی مدلهای ترنسفورماتور است. این لایه به مدل اجازه میدهد تا روابط بین اجزای مختلف یک دنباله ورودی را درک کند، خواه آن دنباله کلمات در یک جمله، کد کامپیوتری یا هر نوع داده ترتیبی دیگری باشد.
فرآیند Self-Attention را میتوان به سه مرحله اصلی تقسیم کرد:
ایجاد بردارهای پرس و جو، کلید و مقدار (Query, Key, Value)
- هر عنصر در دنباله ورودی به سه بردار جداگانه تبدیل میشود: بردار پرس و جو (Query), بردار کلید (Key) و بردار مقدار (Value).
- این تبدیل با ضرب کردن بردار ورودی در ماتریسهای وزندار جداگانه انجام میشود.
محاسبه امتیاز توجه (Attention Score)
- برای هر عنصر در دنباله ورودی، امتیاز توجهی برای هر عنصر دیگر در دنباله محاسبه میشود.
- این امتیاز توجه نشان دهنده میزان مرتبط بودن آن عنصر با عنصر فعلی است.
- امتیاز توجه با محاسبه حاصلضرب داخلی بردار پرس و جو (Query) برای عنصر فعلی با بردار کلید (Key) برای هر عنصر دیگر در دنباله به دست میآید.
ایجاد خروجی با وزندهی
- برای هر عنصر در دنباله ورودی، یک بردار خروجی ایجاد میشود.
- این بردار خروجی با جمع کردن بردارهای مقدار (Value) برای همه عناصر دیگر در دنباله وزن دهی میشود.
- وزن دهی بر اساس امتیاز توجه محاسبه شده در مرحله قبل انجام میشود، به طوری که عناصر مرتبط با امتیاز توجه بالاتر، تاثیر بیشتری بر خروجی داشته باشند.
لایه شبکه عصبی پیشخور
در شبکههای عصبی پیشخور (Feedforward Neural Networks – FNNs) ، لایهها بلوکهای سازنده اصلی هستند. هر لایه شامل تعدادی گره یا نورون مصنوعی است که با وزنها به یکدیگر متصل شدهاند. اطلاعات از طریق شبکه از یک لایه به لایه دیگر به صورت جهتی (به جلو) و بدون هیچ حلقه بازگشتی (برخلاف شبکههای عصبی بازگشتی) منتقل میشود.
اجزای اصلی یک لایه در شبکه عصبی پیشخور
- نورونها: واحدهای پردازش بنیادی شبکه هستند. هر نورون ورودیهایی را از طریق اتصالات وزنی دریافت میکند، آنها را با یک تابع فعالسازی (activation function) پردازش میکند و یک خروجی را تولید میکند.
- اتصالات: وزنهایی را نشان میدهند که قدرت سیگنال بین نورونها را تعیین میکنند. اتصالات میتوانند مثبت یا منفی باشند و نشاندهنده اثر تحریککننده یا مهاری یک نورون بر نورون دیگر باشند.
- تابع فعالسازی: مشخص میکند که چگونه نورون به ورودیهای خود پاسخ میدهد. توابع فعالسازی متداول شامل تابع سیگموئید، تابع ReLU و تابع Tanh میباشند.
انواع لایههای شبکه عصبی پیشخور
- لایه ورودی: دادههای خام را از دنیای واقعی دریافت میکند و به مقادیر عددی تبدیل میکند که میتوانند توسط شبکه پردازش شوند.
- لایههای پنهان: بین لایه ورودی و لایه خروجی قرار دارند و وظیفهی استخراج ویژگیهای پیچیده از دادهها را بر عهده دارند.
- لایه خروجی: نتایج نهایی شبکه را تولید میکند. تعداد و نوع لایههای پنهان در معماری شبکه عصبی پیشخور بسته به پیچیدگی وظیفه و میزان داده در دسترس متغیر است.
نحوه عملکرد لایهها در شبکه عصبی پیشخور
- ورودی: دادهها به لایه ورودی وارد میشوند و به مقادیر عددی تبدیل میشوند.
- محاسبه خروجی: هر نورون در یک لایه، مجموع مقادیر وزنی ورودیهای خود را محاسبه میکند و سپس آن را از طریق تابع فعالسازی عبور میدهد.
- انتقال به لایه بعدی: خروجی هر نورون به عنوان ورودی نورونهای لایه بعدی عمل میکند.
- تکرار: مراحل 2 و 3 تا زمانی که دادهها به لایه خروجی برسند، تکرار میشوند.
- خروجی نهایی: لایه خروجی مقادیر نهایی شبکه را تولید میکند که نشاندهنده پیشبینی یا طبقهبندی مورد نظر برای داده ورودی است.
انکودینگ موقعیتی (Positional Encoding) در مدلهای ترنسفورمر
در مدلهای ترنسفورماتور، انکودینگ موقعیتی تکنیکی است که به مدل کمک میکند تا ترتیب کلمات در یک جمله یا توکنها در یک دنباله را درک کند.
در مدلهای زبانی سنتی، مانند مدلهای Bag-of-Words models،ترتیب کلمات در نظر گرفته نمیشود. این امر میتواند منجر به ابهام و عدم دقت در هنگام پردازش زبان طبیعی شود. به عنوان مثال، جمله “گربه موش را گرفت” معنای متفاوتی با جمله “موش گربه را گرفت” دارد.
مدلهای ترنسفورماتور با استفاده از مکانیزم توجه (Attention mechanism) میتوانند به روابط بین کلمات در یک جمله توجه کنند. با این حال، مکانیزم توجه به تنهایی برای درک ترتیب دقیق کلمات کافی نیست.
انکودینگ موقعیتی چگونه کار میکند؟
انکودینگ موقعیتی به هر کلمه یا توکن در دنباله ورودی یک بردار اضافی به نام بردار موقعیتی (positional vector) اختصاص میدهد. این بردار موقعیتی اطلاعاتی در مورد موقعیت کلمه در دنباله را به مدل ارائه میدهد.
دو روش رایج برای اعمال انکودینگ موقعیتی وجود دارد:
- انکودینگ موقعیتی مطلق (Absolute Positional Encoding): در این روش، به هر کلمه یا توکن در دنباله، یک بردار موقعیتی منحصر به فرد اختصاص داده میشود که به موقعیت مطلق آن در دنباله بستگی دارد.
- انکودینگ موقعیتی نسبی (Relative Positional Encoding): در این روش، به جای استفاده از موقعیت مطلق هر کلمه، از تفاوت موقعیت آن با سایر کلمات در دنباله استفاده میشود. این امر به مدل اجازه میدهد تا ترتیب کلمات را بدون نیاز به دانستن موقعیت مطلق آنها در دنباله یاد بگیرد.
نحوهی کار با مدل ترنسفورمر
1. ورودی را به بردارهای معنایی تبدیل کنید
اولین قدم در کار مدل ترنسفورمر، تبدیل ورودی به بردارهای معنایی است. این کار را الگوریتمهای تعبیه کلمات (Word Embedding) انجام میدهند.
در مدل ترنسفورمر، تعبیه کلمات فقط در اولین انکودر صورت میگیرد. سایر انکودرها، بردارهای خروجی انکودر قبلی را دریافت میکنند. اندازه این بردارها معمولاً 512 بیت است.
2. ارتباط بین کلمات را درک کنید
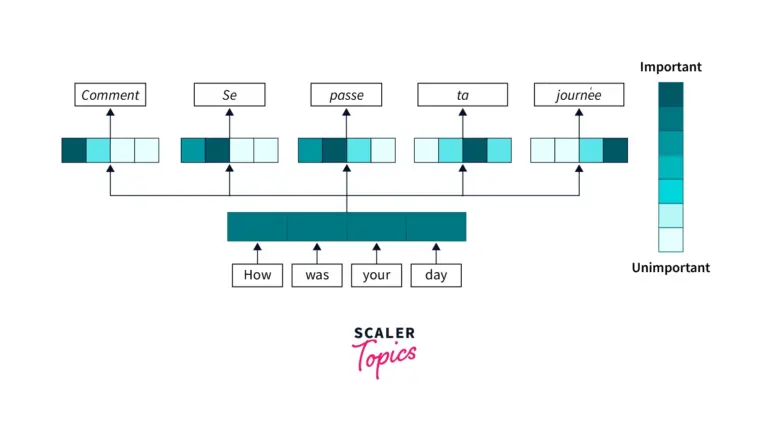
پس از تعبیه، مدل ترنسفورمر به ارتباط بین کلمات در یک جمله توجه میکند. این کار را با استفاده از یک مکانیسم توجه به نام Self-Attention انجام میدهد.
لایه Self-Attention به مدل کمک میکند تا وزنهای مختلفی را به هر کلمه در جمله اختصاص دهد. این وزنها بر اساس اهمیت هر کلمه در جمله تعیین میشوند.
3. ویژگیهای مهم کلمات را استخراج کنید
پس از توجه به ارتباط بین کلمات، مدل ترنسفورمر ویژگیهای مهم کلمات را استخراج میکند. این کار را با استفاده از یک شبکه عصبی معمولی به نام لایه شبکه عصبی پیشخور انجام میدهد.
لایه شبکه عصبی پیشخور معمولاً از چند لایه مخفی تشکیل شده است. این لایهها ویژگیهای مهم کلمات را استخراج میکنند.
4. خروجی را تولید کنید
در مرحله آخر، مدل ترنسفورمر خروجی را تولید میکند. این خروجی میتواند یک جمله، یک پاراگراف، یا یک سند کامل باشد.
خروجی مدل ترنسفورمر با استفاده از یک مکانیسم توجه به نام Attention تولید میشود.
لایه Attention به مدل کمک میکند تا به اهمیت هر کلمه در جمله توجه کند. این کار به مدل کمک میکند تا خروجی دقیقتری تولید کند.
مزایای مدلهای ترنسفورمر
کارایی
مدلهای ترنسفورمر به طور ذاتی موازی هستند، به این معنی که میتوانند محاسبات را به طور همزمان روی چندین واحد پردازشی انجام دهند. این امر آنها را به طور قابل توجهی سریعتر از مدلهای بازگشتی سنتی مانند شبکههای عصبی بازگشتی (RNN) میکند، که محاسبات را به صورت گام به گام انجام میدهند.
دقت
ترنسفورمرها در طیف گستردهای از وظایف پردازش زبان طبیعی (NLP) به نتایج پیشرفتهای دست یافتهاند. به عنوان مثال، آنها در ترجمه ماشینی، خلاصهسازی متن و پاسخ به سوال به طور قابل توجهی از مدلهای قبلی پیشی گرفتهاند.
قابلیت تعمیم
معماری ترنسفورمر به گونهای طراحی شده است که به طور کلی قابل انطباق باشد. با تغییرات جزئی، میتوان از آن برای طیف گستردهای از وظایف NLP استفاده کرد. این امر ترنسفورمرها را به ابزاری قدرتمند و همهکاره برای تحقیقات NLP تبدیل میکند.
قابلیت تفسیر
در مقایسه با سایر مدلهای یادگیری عمیق، ترنسفورمرها شفافتر هستند و درک نحوه عملکرد آنها آسانتر است. این امر آنها را برای محققان و توسعهدهندگانی که به دنبال درک بهتر مدلهای یادگیری ماشینی هستند که استفاده میکنند، جذابتر میکند.
معایب مدلهای ترنسفورمر
پیچیدگی
معماری ترنسفورمر میتواند پیچیده باشد، که میتواند پیادهسازی و آموزش آنها را دشوارتر کند.
نیاز به داده
مدلهای ترنسفورمر برای آموزش به حجم زیادی داده نیاز دارند. این امر میتواند آنها را برای استفاده در برنامههایی که دسترسی به مجموعه دادههای بزرگ ندارند، غیرقابل استفاده کند.
محاسبات پرهزینه
آموزش مدلهای ترنسفورمر میتواند از نظر محاسباتی پرهزینه باشد، به خصوص برای مدلهای بزرگ و پیچیده. این امر میتواند آنها را برای استفاده در برنامههایی که منابع محاسباتی محدودی دارند، غیرقابل استفاده کند.
حساسیت به نویز
ترنسفورمرها میتوانند نسبت به نویز در دادهها حساس باشند. این امر میتواند بر دقت آنها به خصوص در وظایفی که با دادههای پر سر و صدا سروکار دارند تأثیر بگذارد.