علم داده یا دیتا ساینس، زمینهای است که با بهرهگیری از ابزارها و تکنیکهای مدرن، به بررسی حجم گستردهای از دادهها میپردازد. هدف این حوزه از مطالعات، شناسایی الگوهای پنهان در دادهها، استخراج اطلاعات معنادار و استفاده از آنها در تصمیمگیریهای تجاری است. علم داده از الگوریتمهای پیچیده یادگیری ماشین برای ساخت مدلهای پیشبینی بهرهمند میشود. این دادههای مورد استفاده میتوانند از منابع مختلف و فرمهای گوناگون باشند.
در زمان حاضر، با افزایش چشمگیر تولید دادهها، علم داده به عنوان یک بخش اساسی و حیاتی در هر صنعت بهشمار میآید. علم داده یکی از موضوعات پرطرفدار و بحثبرانگیز در حوزههای مختلف صنایع است. محبوبیت این حوزه به طول سالها رشد کرده و شرکتها بهمنظور بهبود تجارت و ارتقاء رضایت مشتریان، به اجرای تکنیکهای Data Science پرداختهاند.
در این مقاله، با مفهوم علم داده و اهمیت آن در صنعت و زندگی روزمره آشنا خواهیم شد؛ همچنین، وظایف یک محقق داده و چگونگی استفاده از علم داده در چند حوزه کاربردی خاص را بررسی خواهیم نمود.
علم داده یا دیتاساینس (Data Science) چیست ؟
علم داده یا دیتا ساینس (Data Science) به عنوان یک حوزه مطالعاتی، از روشها، فرآیندها، الگوریتمها و سیستمهای علمی برای استخراج دانش و بینش از دادههای ساختاریافته و غیرساختاریافته بهره میبرد. سپس این دانش و بینش حاصل، در طیف گستردهای از زمینههای کاربردی به کار میرود.
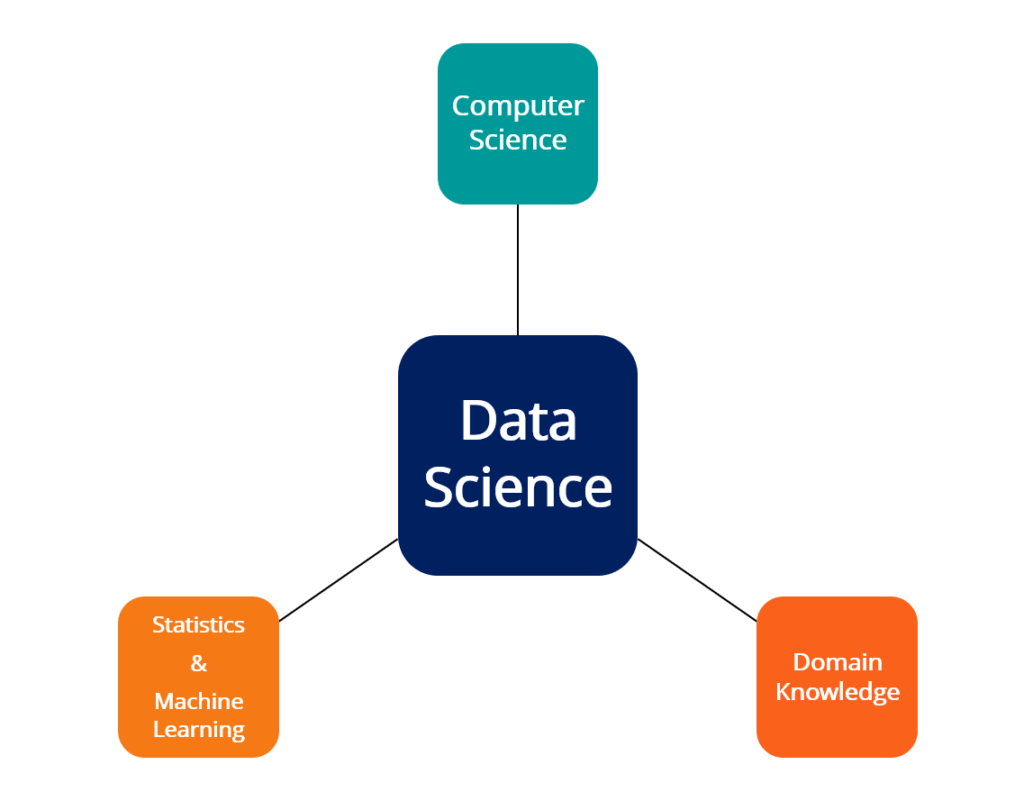
Data Science، ترکیبی از عناصر مختلف از جمله آمار، تجزیه و تحلیل داده، انفورماتیک و روشهای مرتبط است که برای درک و تجزیه و تحلیل پدیدههای واقعی با استفاده از داده بهره میجوید. این حوزه از تکنیکهای متنوعی در زمینههای ریاضیات، آمار، علوم کامپیوتر و علوم اطلاعات بهره میبرد.
از آنجایی که مفهوم دیتا ساینس تبیین شد، سؤال ممکن است ایجاد شود که یک محقق دیتا ساینس به طور دقیق چه کارهایی انجام میدهد؟ در ادامه، به معرفی وظایف یک محقق داده میپردازیم.
مزایا و کاربردهای علم داده
مزیت اصلی علم داده در توانمندسازی و تسهیل تصمیمگیری است. سازمانهایی که در این حوزه سرمایهگذاری میکنند، از شواهد قابل سنجش و مبتنی بر داده برای تصمیمگیریهای تجاری خود بهرهمند میشوند. تصمیمگیریهای دادهمحور میتواند منجر به افزایش سود، بهبود بهرهوری عملیاتی، کارایی کسبوکار، و جریانهای کاری گردد.
در سازمانهایی که با ارباب رجوع سر و کار دارند، دیتاساینس به شناسایی و جلب مخاطبان هدف کمک میکند. این دانش همچنین میتواند به سازمانها در استخدام نیروهایشان کمک کند. علم داده با پردازش داخلی کاربردها و آزمونهای احراز صلاحیت دادهمحور، میتواند به واحد منابع انسانی سازمانها در انجام انتخابهای صحیحتر و سریعتر در طول فرآیند استخدام کمک کند.
مزایای دیتاساینس بستگی به اهداف شرکت و صنعت مربوط به آن دارد. برای مثال، دپارتمانهای فروش و بازاریابی میتوانند دادههای مشتریان را برای بهبود نرخ جذب مشتری و اجرای کمپینهای فرد به فرد کاوش کنند. موسسات بانکی، دادههای خود را جهت ارتقا وظیفه شناسایی کلاهبرداری کاوش میکنند. سرویسهای استریم مانند “نتفلیکس” از دادهها برای شناسایی علایق کاربران و تولید محتوای بهینه بر اساس آنها استفاده میکنند.
همچنین، در نتفلیکس از الگوریتمهای مبتنی بر پایگاه داده جهت ساخت توصیههای شخصیسازی شده متناسب با عقاید کاربران استفاده شده است. شرکتهای حملونقل مانند FedEx، DHL و UPS از علم داده برای کشف بهترین مسیرها، زمانها و نوع حملونقل کالا استفاده میکنند. با وجود کاربردهای متعدد علم داده، این زمینه در کسبوکار هنوز نوظهور است، زیرا شناسایی و تحلیل حجم انبوهی از دادههای ساختار نیافته میتواند برای شرکتها بسیار پیچیده، گرانقیمت و زمانبر باشد.
مفاهیم مرتبط با علم داده
در بخش قبل، رویکردهای تجزیه و تحلیل داده را مشاهده کردیم. Data Science نیز از این رویکردها استفاده میکند، اما با این تفاوت که هدف آن پیشبینی آینده و تصمیمگیری بر اساس آن است. علم داده از چهار مفهوم زیر برای رسیدن به این هدف استفاده میکند:
- تحلیلهای علت و معلولی پیش بینی کننده (Predictive causal analytics): این مفهوم به دنبال یافتن رابطه علت و معلولی بین متغیرها است تا بتوان از آن برای پیشبینی آینده استفاده کرد.
- تجزیه و تحلیل تجویزی (Prescriptive analytics): این مفهوم به دنبال یافتن بهترین راهحل برای یک مشکل است. که از مدلسازی و شبیهسازی استفاده میشود.
- پیشبینی با استفاده از یادگیری ماشین (Machine learning for making predictions): این مفهوم از الگوریتمهای یادگیری ماشین برای پیشبینی آینده استفاده میکند.
- کشف الگو با استفاده از یادگیری ماشین (Machine learning for pattern discovery): این مفهوم از الگوریتمهای یادگیری ماشین برای شناسایی الگوهای پنهان در دادهها استفاده میکند.
تحلیلهای علت و معلولی پیش بینی کننده
تحلیلهای علت و معلولی پیش بینی کننده به دنبال یافتن رابطه علت و معلولی بین متغیرها است. برای این کار، از روشهای آماری و مدلسازی استفاده میشود. این روشها میتوانند برای پیشبینی آینده نیز استفاده شوند.
برای مثال، فرض کنید میخواهیم پیشبینی کنیم که قیمت سهام یک شرکت در آینده چه خواهد شد. برای این کار، میتوانیم از دادههای تاریخی قیمت سهام این شرکت و سایر متغیرهای مرتبط مانند وضعیت اقتصادی، عملکرد شرکت و غیره استفاده کنیم. با استفاده از روشهای آماری، میتوانیم رابطه علت و معلولی بین این متغیرها را پیدا کنیم. سپس، با استفاده از این رابطه، میتوانیم قیمت سهام شرکت را در آینده پیشبینی کنیم.
تجزیه و تحلیل تجویزی
تجزیه و تحلیل تجویزی به دنبال یافتن بهترین راهحل برای یک مشکل است و در این روش از مدلسازی و شبیهسازی استفاده میشود.
برای مثال، فرض کنید میخواهیم یک کمپین تبلیغاتی برای یک محصول جدید راهاندازی کنیم. برای این کار، میتوانیم از مدلسازی استفاده کنیم تا تأثیرات مختلف عوامل مختلف بر موفقیت کمپین را بررسی کنیم. سپس، با استفاده از این نتایج، میتوانیم بهترین استراتژی برای کمپین تبلیغاتی را تعیین کنیم.
پیشبینی با استفاده از یادگیری ماشین
پیشبینی با استفاده از یادگیری ماشین به دنبال پیشبینی آینده با استفاده از الگوریتمهای یادگیری ماشین است.
برای مثال، فرض کنید میخواهیم میزان فروش یک محصول در آینده را پیشبینی کنیم. برای این کار، میتوانیم از الگوریتمهای یادگیری ماشین مانند رگرسیون خطی یا درخت تصمیمگیری استفاده کنیم. این الگوریتمها با استفاده از دادههای تاریخی، میتوانند رابطه بین متغیرهای مختلف را یاد بگیرند و سپس، از این رابطه برای پیشبینی آینده استفاده کنند.
کشف الگو با استفاده از یادگیری ماشین
کشف الگو با استفاده از یادگیری ماشین به دنبال شناسایی الگوهای پنهان در دادهها با استفاده از الگوریتمهای یادگیری ماشین است.
برای مثال، فرض کنید میخواهیم رفتار کاربران یک وبسایت را بررسی کنیم. برای این کار، میتوانیم از الگوریتمهای یادگیری ماشین مانند خوشهبندی استفاده کنیم. این الگوریتمها میتوانند کاربران را بر اساس رفتارشان در گروههای مختلف قرار دهند. سپس، با بررسی این گروهها، میتوانیم اطلاعات ارزشمندی در مورد رفتار کاربران به دست بیاوریم.
اینها چهار مفهوم اصلی مرتبط با دیتاساینس هستند که برای تصمیمگیری و پیشبینی آینده استفاده میشوند.
مسیر یادگیری علم داده
اگر به دنبال پیشرفت حرفهای در زمینه علم داده هستید، در این بخش به تفکیک مراحل لازم برای تبدیل شدن به یک دانشمند داده خواهیم پرداخت. دانشمند داده، مفاهیم مهندسی نرمافزار، آمار، و دنیای کسب و کار را ترکیب میکند تا دادهها را برای استخراج بینشهای ارزشمند بررسی کند.
در این برنامه، چند گام مهم برای یادگیری مهارتهای لازم برای تبدیل شدن به یک دانشمند داده فهرست شدهاند. این مراحل بر اساس پیچیدگیهای مختلف، منحنی یادگیری خود را دارند. بنابراین، یادگیری و تسلط بر هر مرحله نیازمند زمانهای مختلفی است. بهتر است این گامها را با توجه به شرایط خود پیش ببرید، و امکان دارد برخی از مراحل را همزمان ادامه دهید تا به سرعت به پیشرفت برسید.
گام ۱: یادگیری زبان برنامهنویسی
یکی از نخستین قدمها در این مسیر یادگیری زبان برنامهنویسی است. هر دانشمند داده باید در یکی از زبانهای برنامهنویسی تخصص پیدا کند تا بتواند وظایف مختلف Data Science را انجام دهد. دو زبان معروف در این حوزه Python و R هستند. اگر تازهکار هستید، یادگیری Python برای علم داده نسبت به سایر زبانها به شدت توصیه میشود.
دلایل یادگیری Python برای علم داده
- سادگی سینتکس و سهولت استفاده
- تعداد زیادی کتابخانه منبع باز و اسناد آنلاین برای اجرای وظایف مختلف علم داده
موضوعات برنامهنویسی برای علم داده
- مفاهیم اولیه برنامهنویسی، مانند انواع دادهها، متغیرها، توابع، و حلقهها
- مفاهیم خاص علم داده، مانند آرایهها، دادههای ساختاریافته و نامتقارن، و تجزیه و تحلیل دادهها
- کتابخانههای Python برای علم داده، مانند NumPy، SciPy، Pandas، و Matplotlib
گام ۲: یادگیری آمار
آمار یکی از پایههای دیتاساینس است. دانشمندان داده باید با مفاهیم آماری مانند توزیعهای احتمالی، آزمون فرضیه، و یادگیری ماشین آشنا باشند.
موضوعات آماری برای علم داده
- مفاهیم اولیه آمار، مانند توزیعهای احتمالی، آمار توصیفی، و آمار استنباطی
- مفاهیم خاص علم داده، مانند یادگیری ماشین، یادگیری عمیق، و تجزیه و تحلیل دادهها
گام ۳: یادگیری مفاهیم کسب و کار
دانشمندان داده باید با مفاهیم کسب و کار مانند تجزیه و تحلیل کسب و کار، بازاریابی، و اقتصاد آشنا باشند. این دانش به آنها کمک میکند تا نتایج تحلیلهای خود را به زبانی قابل درک برای کسب و کارها ارائه دهند.
موضوعات کسب و کار برای علم داده
- مفاهیم اولیه کسب و کار، مانند تجزیه و تحلیل کسب و کار، بازاریابی، و اقتصاد
- مفاهیم خاص علم داده، مانند کاربرد علم داده در کسب و کار
گام ۴: کسب تجربه عملی
یکی از مهمترین مراحل برای تبدیل شدن به یک دانشمند داده، کسب تجربه عملی است. این تجربه میتواند از طریق مشارکت در پروژههای واقعی، کارآموزی، یا شرکت در مسابقات علمی داده به دست آید.
نحوه کسب تجربه عملی
- مشارکت در پروژههای واقعی
- کارآموزی در یک شرکت یا سازمان
- شرکت در مسابقات علمی داده
گام ۵: ساخت رزومه و شبکهسازی
پس از کسب مهارتها و تجربه لازم، نوبت به ساخت رزومه و شبکهسازی میرسد. رزومه شما باید مهارتها و تجربههای شما را بهطور خلاصه و مختصر بیان کند. شبکهسازی نیز به شما کمک میکند تا با افراد فعال در این حوزه آشنا شوید و فرصتهای شغلی را پیدا کنید.
نحوه ساخت رزومه برای علم داده
- برجسته کردن مهارتها و تجربههای مرتبط با علم داده
- استفاده از زبانی واضح و مختصر
- بهروزرسانی منظم رزومه
نحوه شبکهسازی برای علم داده
- شرکت در رویدادهای مرتبط با علم داده
- ارتباط با افراد فعال در این حوزه در شبکههای اجتماعی
- حضور در انجمنهای علمی داده
یادگیری علم داده یک مسیر طولانی و چالشبرانگیز است، اما در نهایت میتواند به شما کمک کند تا شغلی پردرآمد و پرمخاطب در حوزه فناوری اطلاعات داشته باشید.
کتابخانههای پایتون برای علم داده
پایتون یک زبان برنامهنویسی محبوب برای علم داده است. یکی از دلایل محبوبیت آن، کتابخانههای متعددی است که برای اجرای هر نوع تسک مرتبط با علم داده فراهم میکند.
در این مقاله، برخی از رایجترین کتابخانههای پایتون برای علم داده را معرفی میکنیم.
NumPy
NumPy مخفف عبارت Numerical Python است. این کتابخانه روشها و توابع مختلفی را برای مدیریت و پردازش آرایههای بزرگ، ماتریسها و جبر خطی ارائه میدهد.
NumPy برای انجام عملیات ریاضی و آماری بر روی دادههای بزرگ ضروری است. به عنوان مثال، میتوانید از NumPy برای محاسبه میانگین، انحراف استاندارد، کوواریانس و سایر آمارهای توصیفی استفاده کنید.
Pandas
Pandas محبوبترین کتابخانه پایتون برای علم داده است. این کتابخانه بسیاری از توابع داخلی مفید را برای انجام دستکاری و تجزیه و تحلیل دادهها بر روی مقادیر زیادی از دادههای ساخت یافته ارائه میدهد.
Pandas برای انجام عملیات پیچیدهتر بر روی دادهها مانند تجزیه و تحلیل سری زمانی، تحلیل دادههای ناهمگن و تجسم دادهها ضروری است.
Matplotlib
یک کتابخانه تجسم دادهها است که روشها و عملکردهایی را برای تجسم دادهها به شکل نمودارهای مختلف ارائه میکند. که برای ایجاد نمودارهای جذاب و مفید برای نمایش دادهها ضروری است.
Seaborn
یک کتابخانه تجسم دادهها است که بسیاری از توابع داخلی را برای روشهای تجسم داده مختلف مانند هیستوگرام، نمودار میلهای، نقشه حرارتی، نمودار چگالی و غیره فراهم میکند.
همچنین استفاده از Matplotlib را آسانتر میکند و ارقام زیباییشناختی جذابتری را ارائه میدهد.
SciPy
کتابخانهای است که انواع مختلفی از روشها و توابع برای اجرای مفاهیم آماری و ریاضی مورد نیاز در علم داده را در اختیار شما قرار میدهد و برای انجام تحلیلهای آماری پیچیده مانند آزمون فرضیه، خوشهبندی، کاهش ابعاد و غیره ضروری است.
Scikit-Learn
یک کتابخانه یادگیری ماشین است که پیادهسازی ساده، بهینه و سازگار را برای طیف وسیعی از تکنیکهای یادگیری ماشین ارائه میکند. و برای ساخت مدلهای یادگیری ماشین برای پیشبینی، طبقهبندی و سایر کاربردهای یادگیری ماشین ضروری است.
کتابخانههای پایتون برای دیتاساینس ابزارهای قدرتمندی هستند که میتوانند به شما در انجام انواع تسکهای علم داده کمک کنند.
با یادگیری نحوه استفاده از این کتابخانهها، میتوانید مهارتهای خود را به عنوان یک دانشمند داده بهبود بخشید.
چند نکته برای یادگیری کتابخانههای پایتون برای علم داده:
۱.شروع با کتابخانههای اساسی مانند NumPy، Pandas و Matplotlib.
۲.برای یادگیری نحوه استفاده از این کتابخانهها، از آموزشهای آنلاین و منابع موجود استفاده کنید.
۳.تمرین کنید، تمرین کنید، تمرین کنید!
آمار و ریاضیات جزء ابزارهای بنیادی علم داده و هر الگوریتم یادگیری ماشین (Machine Learning) از این اصول بهره میبرد. برای یک دانشمند داده، درک دقیق از مفاهیم آماری و ریاضی مهم است. توجه داشته باشید که برای یادگیری علم داده، شما نیازی به تخصص عمیق در ریاضیات ندارید، بلکه آشنایی با برخی اصول اساسی کافی است تا نحوه کارکرد الگوریتمهای این زمینه را بهتر درک کنید.
در مورد یادگیری ماشین و یادگیری عمیق به عمق موضوع پی ببرید. زمانی که درک جامعتری از مفاهیم گفتهشده در بالا پیدا کردید، میتوانید به مطالعه و درک الگوریتمهای یادگیری ماشین بپردازید.
مفاهیمی که در علم داده بسیار پرکاربرد هستند عبارتند از :
- یادگیری نظارت شده (Supervised Learning): الگوریتمهایی که الگوهای دادهها را بر اساس متغیر هدفی که در اختیارشان قرار میگیرد، یاد میگیرند. این موارد شامل تکنیکهای رگرسیون و طبقهبندی است. مثالهایی از این الگوریتمها عبارتند از رگرسیون خطی، رگرسیون لجستیک، درخت تصمیم، جنگل تصادفی، XGBoost، Naive Bayes، KNN و غیره.
- یادگیری بدون نظارت (Unsupervised Learning): الگوریتمهایی که زمانی استفاده میشوند که هیچ متغیر هدفی در دسترس نباشد. مثالهایی از این دسته عبارتند از K-Means Clustering، PCA، Association Mining و غیره.
- یادگیری عمیق (Deep Learning): این زیرشاخه در حوزه یادگیری ماشین از شبکههای عصبی برای مدلسازی دادهها استفاده میکند. شبکههای عصبی، مدلهای ریاضی هستند که از ساختار مغز انسان الهام میگیرند. یادگیری عمیق به دانشمندان داده این امکان را میدهد که دادههای پیچیده مانند تصاویر و متون را پردازش و مدل کنند.
چرا علم داده اهمیت دارد؟
علم داده اهمیت دارد زیرا به ما کمک میکند تا نیازهای دقیق مشتریان خود را از دادههای متنوع و حجیم، از جمله سابقه خرید، سن، و درآمد، بهتر درک کنیم. این دانش به ما امکان میدهد تا مدلهای بهتر و کارآمدتری را آموزش دهیم و محصولات خود را با دقت بیشتری به مشتریان پیشنهاد دهیم.
در گذشته، دادهها اغلب در سیستمهای سنتی ساختاردار بودند. اما امروزه، اکثر دادهها بدون ساختار یا نیمهساختارشده هستند. این دادهها از منابع متنوعی مانند گزارشهای مالی، فایلهای متنی، فرمهای چندرسانهای، حسگرها و ابزارهای مشابه جمعآوری میشوند. ابزارهای ساده ناکارآمد در پردازش این حجم زیاد و تنوع داده هستند. بنابراین، نیاز به علم داده و ابزارها و الگوریتمهای تحلیلی پیشرفتهتر برای پردازش، تجزیه و تحلیل و استخراج اطلاعات معنادار از داده وجود دارد.
به عنوان مثال، در حوزه پیشبینی آب و هوا، از دادههای کشتیها، هواپیماها، رادارها، و ماهوارهها برای ساخت مدل و تجزیه و تحلیل استفاده میشود. علم داده به پیشبینی وقوع زلزله یا سیل نیز کمک میکند، که این اطلاعات امکان اقدامات پیشگیرانه و نجات زندگیهای بسیاری را فراهم میکند.
کاربردهای علم داده
علم داده یک رشتهی میانرشتهای است که از آمار، ریاضیات، علوم کامپیوتر و سایر حوزهها برای استخراج دانش و بینش از دادهها استفاده میکند. کاربردهای علم داده در حال حاضر در طیف گستردهای از صنایع و زمینهها دیده میشود.
در اینجا به برخی از کاربردهای مهم دیتاساینس میپردازیم :
۱.تشخیص ناهنجاری: دیتاساینس میتواند برای شناسایی الگوهای غیرعادی در دادهها استفاده شود. این امر میتواند برای شناسایی کلاهبرداری، بیماری و سایر مسائل مهم مفید باشد.
۲.طبقهبندی: دیتاساینس میتواند برای طبقهبندی دادهها بر اساس ویژگیهای آنها استفاده شود. این امر میتواند برای سازماندهی دادهها، شناسایی الگوها و تصمیمگیری مفید باشد.
۳.پیشبینی: دیتاساینس میتواند برای پیشبینی نتایج آینده بر اساس دادههای تاریخی استفاده شود. این امر میتواند برای برنامهریزی، تصمیمگیری و کاهش ریسک مفید باشد.
۴.تشخیص الگو: دیتاساینس میتواند برای شناسایی الگوهای پنهان در دادهها استفاده شود. این امر میتواند برای درک بهتر جهان و تصمیمگیری مفید باشد.
۵.تشخیص چهره، صدا و متن: دیتاساینس میتواند برای شناسایی افراد، تشخیص صداها و تفسیر متن استفاده شود. این امر میتواند برای امنیت، خدمات مشتری و سایر کاربردها مفید باشد.
۶.توصیه: دیتاساینسمیتواند برای توصیه محصولات، خدمات و سایر موارد بر اساس ترجیحات کاربر استفاده شود. این امر میتواند برای بهبود تجربه کاربر و افزایش فروش مفید باشد.
۷.رگرسیون: دیتاساینس میتواند برای پیشبینی مقادیر عددی بر اساس دادههای تاریخی استفاده شود. این امر میتواند برای پیشبینی قیمتها، تقاضا و سایر مقادیر مفید باشد.
۸.بهینهسازی: دیتاساینس میتواند برای یافتن بهترین راهحل برای یک مشکل استفاده شود. این امر میتواند برای بهبود کارایی، کاهش هزینهها و سایر اهداف مفید باشد.
اینها تنها برخی از کاربردهای بسیاری هستند که علم داده در حال حاضر در آنها مورد استفاده قرار میگیرد. با افزایش تولید دادهها، انتظار میرود که کاربردهای علم داده نیز گسترش یابد.
دانشمند داده کیست؟
دانشمند داده فردی است که در فرآیندهای جمعآوری، سازماندهی، و تحلیل دادهها تخصص دارد و اطلاعات موجود در آنها را به گونهای استخراج میکند که دیگران بتوانند آن را درک کنند. این فرد مسئول تشخیص الگوهای پنهان در حجم زیادی از دادهها است و اغلب برای بهبود فرآیندهای تصمیمگیری در کسب و کارها و سازمانها از الگوریتمهای پیشرفته و مدلهای یادگیری ماشین استفاده میکند. دانشمندان داده دانش عمیقی از ریاضی و آمار و همچنین تجربه در استفاده از زبانهای برنامهنویسی مانند R، Python و SQL دارند.
وظایف و مسئولیتهای یک دانشمند داده بسته به زمینهی کاری او متفاوت است. با این حال، برخی از وظایف مشترک دانشمندان داده عبارتند از:
- جمعآوری و سازماندهی دادهها
- تجزیه و تحلیل دادهها با استفاده از آمار و ریاضیات
- توسعهی مدلهای یادگیری ماشین
- ارائهی گزارشها و توصیههای مبتنی بر داده
برای تبدیل شدن به یک دانشمند داده، به مدرک کارشناسی یا کارشناسی ارشد در رشتههای مرتبط مانند آمار، ریاضیات، علوم کامپیوتر، یا مهندسی نیاز دارید. همچنین، داشتن تجربهی کاری در زمینهی علم داده مفید است.
دانشمندان داده نقش مهمی در دنیای امروز ایفا میکنند. آنها از دادهها برای بهبود تصمیمگیری، حل مشکلات، و ایجاد نوآوری استفاده میکنند. با افزایش تولید دادهها، انتظار داریم که تقاضا برای دانشمندان داده نیز در آینده افزایش یابد.
بازار کار علم داده در ایران: فرصتها و چالشها
بازار کار علم داده در داخل کشور در حال حاضر در مرحله رشد و توسعه قرار دارد. اگرچه در مقایسه با کشورهای پیشرو در این حوزه، هنوز در ابتدای راه هستیم، اما نشانههای روشنی از پویایی و پتانسیل بالای این بازار به چشم میخورد.
در کشورمان، تقاضا برای متخصصان علم داده در صنایع مختلفی از جمله موارد زیر رو به افزایش است:
- فناوری اطلاعات و ارتباطات (ICT): شرکتهای فعال در زمینه نرمافزار، سختافزار، اینترنت، و مخابرات در استخدام متخصصان علم داده در ایران پیشگام هستند.
- بانکداری و مالی: بانکها، بیمهها، و سایر مؤسسات مالی به طور فزایندهای از علم داده برای تحلیل ریسک، شناسایی تقلب، بهبود خدمات مشتریان، و توسعه محصولات جدید استفاده میکنند.
- خردهفروشی و تجارت الکترونیک: فروشگاههای آنلاین و آفلاین برای تحلیل رفتار مشتریان، شخصیسازی تجربه خرید، مدیریت زنجیره تامین، و بهینهسازی قیمتگذاری به علم داده روی آوردهاند.
- صنعت نفت و گاز: شرکتهای نفتی و گازی برای بهینهسازی فرآیندهای اکتشاف، استخراج، و پالایش، کاهش هزینهها، و بهبود بهرهوری از علم داده بهره میبرند.
- بهداشت و درمان: بیمارستانها، مراکز درمانی، و شرکتهای داروسازی برای بهبود تشخیص و درمان بیماریها، توسعه داروهای جدید، و مدیریت منابع به علم داده نیازمندند.
- بازاریابی و تبلیغات: شرکتهای تبلیغاتی و بازاریابی برای تحلیل کمپینهای تبلیغاتی، هدفگذاری دقیقتر مخاطبان، و بهبود نرخ تبدیل از علم داده بهره میگیرند.
مهارتها و مدارک مورد نیاز برای ورود به بازار کار علم داده ایران
برای موفقیت در بازار کار علم داده ایران، متخصصان به ترکیبی از مهارتهای فنی و نرم نیاز دارند. برخی از مهمترین مهارتها و مدارک مورد نیاز عبارتند از:
- مهارتهای فنی:
- برنامهنویسی: تسلط به زبانهای برنامهنویسی مانند پایتون و R که به طور گسترده در علم داده استفاده میشوند، ضروری است.
- یادگیری ماشین: آشنایی با الگوریتمهای یادگیری ماشین، روشهای مدلسازی، و تکنیکهای ارزیابی مدلها بسیار مهم است.
- آمار و احتمالات: درک قوی از مفاهیم آماری و احتمالات برای تحلیل دادهها و تفسیر نتایج ضروری است.
- بانکهای اطلاعاتی و SQL: توانایی کار با بانکهای اطلاعاتی و زبان SQL برای استخراج و مدیریت دادهها لازم است.
- تجسم دادهها: مهارت در استفاده از ابزارهای تجسم دادهها برای ارائه یافتهها به صورت قابل فهم و جذاب حائز اهمیت است.
- پردازش زبان طبیعی (NLP): برای کار با دادههای متنی، آشنایی با NLP و تکنیکهای آن مورد نیاز است (به خصوص در برخی صنایع).
- کلانداده (Big Data): برای کار با حجم بالای دادهها، آشنایی با فناوریهای کلانداده مانند Hadoop و Spark مفید خواهد بود (به خصوص در شرکتهای بزرگ).
- مهارتهای نرم:
- حل مسئله: توانایی شناسایی مسائل و ارائه راهکارهای مبتنی بر داده برای حل آنها.
- تفکر تحلیلی: توانایی تجزیه و تحلیل دادهها و استخراج بینشهای ارزشمند.
- مهارتهای ارتباطی: توانایی برقراری ارتباط موثر با همکاران و ارائه یافتهها به ذینفعان غیرفنی.
- کار تیمی: توانایی کار به صورت موثر در تیمهای چند تخصصی.
- یادگیری مداوم: علم داده یک حوزه به سرعت در حال تحول است، بنابراین توانایی و تمایل به یادگیری مداوم ضروری است.
با توجه به کمبود متخصصان و تقاضای بالا، شرکتها برای جذب و نگهداشت نیروهای متخصص در این حوزه رقابت میکنند و سعی دارند حقوق و مزایای جذابتر ارائه دهند.
نتیجهگیری
بازار کار علم داده در ایران با وجود چالشهای موجود، فرصتهای شغلی فراوانی را برای متخصصان این حوزه فراهم کرده است. با توجه به روند رو به رشد فناوری و افزایش نیاز به تحلیل دادهها، پیشبینی میشود که آینده این بازار بسیار روشن و پررونق باشد. بنابراین، افرادی که علاقهمند به ورود به این حوزه هستند، میتوانند با کسب مهارتها و دانش لازم، از فرصتهای شغلی موجود بهرهمند شوند و به توسعه این حوزه در ایران کمک کنند.