یادگیری انتقالی (Transfer Learning) به عنوان یکی از پیشرفتهترین تکنیکهای یادگیری ماشین، در حال تحول بنیادین حوزه هوش مصنوعی است. این مقاله به بررسی جامع آینده این فناوری و کاربردهای نوظهور آن میپردازد. با تحلیل پیشرفتهای اخیر و روندهای آتی، نشان میدهیم که چگونه یادگیری انتقالی از مدلهای پیشآموزشدیده ساده به سیستمهای هوشمند چندمنظوره تبدیل شده است.
مقدمه
در دهه اخیر، یادگیری عمیق موفقیتهای چشمگیری در حوزههای مختلف از بینایی کامپیوتر تا پردازش زبان طبیعی به دست آورده است. با این حال، یکی از چالشهای اساسی این رویکردها، نیاز به مجموعه دادههای عظیم برچسبگذاری شده است. یادگیری انتقالی به عنوان راهحلی کارآمد برای این محدودیت ظاهر شده و امکان استفاده مجدد از دانش آموختهشده در یک وظیفه برای بهبود عملکرد در وظایف مرتبط را فراهم میکند.
بر اساس تحقیقات موسسه MIT، یادگیری انتقالی میتواند زمان توسعه مدلها را تا ۴۰ درصد کاهش دهد و دقت مدلها را در وظایفی مانند طبقهبندی تصویر و پردازش زبان طبیعی تا ۱۵-۲۰ درصد بهبود بخشد، بهویژه زمانی که دادههای آموزشی محدود باشند.
مبانی نظری یادگیری انتقالی
تعریف و مفهوم
یادگیری انتقالی به فرآیند استخراج دانش از یک محیط منبع و اعمال آن به محیط هدف متفاوت اشاره دارد. این رویکرد بر این فرض استوار است که دانش به دست آمده از حل یک مسئله میتواند در حل مسائل مشابه مفید باشد.
انواع یادگیری انتقالی
۱. انتقال مبتنی بر نمونه (Instance-based Transfer) در این روش، نمونههای داده از دامنه منبع با وزندهی مجدد برای استفاده در دامنه هدف انتخاب میشوند.
۲. انتقال مبتنی بر ویژگی (Feature-based Transfer) این رویکرد بر یادگیری نمایشهای ویژگی مشترک بین دامنههای منبع و هدف تمرکز دارد.
۳. انتقال مبتنی بر مدل (Model-based Transfer) در این روش، پارامترهای مدلهای پیشآموزشدیده در دامنه منبع به عنوان نقطه شروع برای آموزش در دامنه هدف استفاده میشوند.
۴. سازگاری دامنه (Domain Adaptation) این تکنیک به مدلها اجازه میدهد دانش خود را از یک دامنه به دامنه دیگر منتقل کنند، حتی زمانی که توزیع دادهها متفاوت است.
پیشرفتهای اخیر در یادگیری انتقالی
مدلهای زبانی بزرگ
مدلهایی مانند BERT، GPT-3 و T5 انقلابی در پردازش زبان طبیعی ایجاد کردهاند. BERT با استفاده از رویکرد دوجهته، درک عمیقتری از زبان ارائه میدهد، در حالی که GPT-3 با ۱۷۵ میلیارد پارامتر، قابلیت تولید متن شبیه انسان را دارد.
تحقیقات نشان میدهند که این مدلها میتوانند با حداقل نمونهها (Few-Shot Learning) به وظایف جدید سازگار شوند و نیاز به مجموعه دادههای بزرگ برچسبگذاری شده را کاهش دهند.
معماریهای شبکه عصبی پیشرفته
شبکههای کانولوشنی (CNNs) معماریهایی مانند VGG، ResNet و EfficientNet در بینایی کامپیوتر به عنوان مدلهای پایه برای یادگیری انتقالی استفاده میشوند.
ترنسفورمرها (Transformers) این معماری با مکانیزم توجه (Attention) خود، توانایی پردازش موازی و درک روابط بلندمدت در دادهها را فراهم میکند.
کاربردهای نوین یادگیری انتقالی
۱. حوزه پزشکی و سلامت
یادگیری انتقالی در تشخیص بیماریها از طریق تصاویر پزشکی نقش حیاتی ایفا میکنده است. تحقیقات اخیر نشان میدهند که:
- مدلهای پیشآموزشدیده میتوانند با دقت ۹۹.۶۴% بیماریهای برنج را تشخیص دهند
- در طبقهبندی بیماریهای گوجهفرنگی، دقت ۹۹.۵۱% حاصل شده است
- برای تشخیص آلزایمر، مدلهای سهبعدی CNN با یادگیری انتقالی دقت ۹۲.۸% برای تفکیک بیماران از افراد سالم داشتهاند
یادگیری فدرال در مراقبتهای بهداشتی این رویکرد به بیمارستانها و مؤسسات تحقیقاتی اجازه میدهد بدون به اشتراکگذاری دادههای حساس بیماران، بهصورت مشترک مدلهای هوش مصنوعی را آموزش دهند. تحقیقات نشان میدهند که تنها ۵.۲% از مطالعات یادگیری فدرال به مرحله پیادهسازی بالینی واقعی رسیدهاند، که نشاندهنده پتانسیل عظیم برای رشد است.
۲. خودروهای خودران
یادگیری انتقالی در توسعه خودروهای خودران نقش کلیدی دارد:
AutoML و بهینهسازی معماری شرکت Waymo با همکاری Google AI، از یادگیری انتقالی برای ساخت مدلهای عصبی بهینه استفاده میکند. آنها موفق شدند مدلهایی با تأخیر ۲۰-۳۰% کمتر و نرخ خطای ۸-۱۰% پایینتر نسبت به معماریهای دستی طراحی کنند.
تشخیص در شرایط جوی نامساعد مدلهای یادگیری انتقالی با ادغام EfficientNet، SqueezeNet و MobileNet-V2، قادر به تشخیص دقیق اشیا در شرایط جوی سخت هستند.
یادگیری از مشاهده الگوریتمهای جدید به خودروهای خودران اجازه میدهند با مشاهده سایر خودروها در محیط، تکنیکهای رانندگی ایمن را یاد بگیرند.
۳. کشاورزی هوشمند
یادگیری انتقالی در کشاورزی دقیق کاربردهای متنوعی دارد:
- تشخیص بیماری گیاهان: معماریهای اصلاحشده VGG19، NasNetMobile و DenseNet169 برای کاهش پارامترهای قابل آموزش استفاده میشوند
- تشخیص نهالها: مدلهای R-CNN بهبودیافته با ResNet101 امتیاز F1 برابر ۹۳% در تشخیص نهالهای کاهو دستیافتهاند
- پیشبینی آبوهوا: متخصصان هواشناسی از مدلهای پیشآموزشدیده بر روی دادههای تاریخی آبوهوا استفاده میکنند تا شرایط آتی را با دقت بیشتری پیشبینی کنند
۴. محاسبات لبه و اینترنت اشیا
چالشها و راهحلها دستگاههای IoT معمولاً دارای منابع محاسباتی محدود، حافظه کوچک و مصرف انرژی پایین هستند. یادگیری انتقالی با اشتراک لایههای پایینی شبکههای عمیق بین چندین برنامه، مقدار محاسبات کلی را کاهش میدهد.
معماری ترکیبی ابر-لبه این معماری از قدرت محاسباتی ابر برای آموزش مدلهای پیچیده استفاده میکند و سپس آنها را برای اجرای بلادرنگ بر روی دستگاههای لبه مستقر میسازد.
فریمورک BrainyEdge این فریمورک هوش مدلهای AI در لبه را با طراحی یک رویه یادگیری شامل یادگیری انتقالی و یادگیری افزایشی افزایش میدهد تا مدلها را با دادههای شخصیسازیشده و افزایشی ذخیرهشده محلی، بهصورت پویا بازآموزی کند.
۵. صنایع ساختمانی
تحلیل سیستماتیک ۳۶۶ انتشار از سال ۲۰۱۵ تا ۲۰۲۴ نشان میدهد که یادگیری انتقالی در ساختوساز هوشمند کاربردهای گستردهای دارد:
- تشخیص نقص در مواد ساختمانی
- پیشبینی ایمنی در محل کار
- مدیریت منابع و بهینهسازی پروژه
- نظارت بر کیفیت ساخت
یادگیری چندمنظوره (Few-Shot و Meta-Learning)
مفهوم و اهمیت
یادگیری چندمنظوره به توانایی یادگیری مفاهیم جدید با تنها چند نمونه اشاره دارد. این رویکرد مستقیماً از یادگیری انتقالی الهام گرفته و سه نوع اصلی دارد:
۱. یادگیری چندنمونهای (Few-Shot Learning) یادگیری از چند نمونه برچسبدار
۲. یادگیری تکنمونهای (One-Shot Learning) یادگیری از تنها یک نمونه
۳. یادگیری صفرنمونهای (Zero-Shot Learning) پیشبینی بدون هیچ داده برچسبدار با استفاده از دانش پیشین
چارچوب N-Way K-Shot
در این چارچوب:
- N: تعداد کلاسهایی که مدل باید تشخیص دهد
- K: تعداد نمونههای برچسبدار برای هر کلاس
برای مثال، در یک وظیفه ۳-Way-۲-Shot:
- مجموعه داده شامل ۳ کلاس است
- هر کلاس ۲ نمونه دارد
الگوریتمهای کلیدی
۱. MAML (Model-Agnostic Meta-Learning) این الگوریتم پارامترهای مدل را بهگونهای بهینه میکند که بتواند با یک مجموعه داده کوچک برای وظیفه جدید بهطور کارآمد تنظیم شود.
۲. شبکههای اولیه (Prototypical Networks) این شبکهها نمونههای ورودی را به فضای تعبیه (Embedding Space) نگاشت میکنند که در آن کلاسهای مشابه در کنار هم قرار میگیرند.
۳. شبکههای تطبیق (Matching Networks) اولین روشی که برای آموزش و آزمایش در وظایف n-shot، k-way طراحی شد، با ایجاد یک الگوریتم همسایگان نزدیک بهطور کامل تفاضلپذیر.
روندهای آینده یادگیری انتقالی
۱. بهبود تکنیکهای یادگیری انتقالی
کاهش عدم تطابق داده (Data Mismatch) در سال ۲۰۲۴ و ۲۰۲۵، توسعه تکنیکهای کارآمدتر یادگیری انتقالی که کمتر مستعد مشکلات عدم تطابق داده هستند، در حال پیشرفت است.
یادگیری انتقالی دوگانه (Double Transfer Learning) این رویکرد با استفاده از مدل پیشآموزشدیده برای آموزش مجدد در دامنه مرتبط، و سپس انتقال به دامنه هدف، عملکرد را بهطور چشمگیری بهبود میبخشد. برای مثال، در تشخیص زخم پای دیابتی، این روش امتیاز F1 را از ۸۶% به ۹۹.۲۵% افزایش داد.
۲. معماریهای مدل پیشرفته
مدلهای ترانسفورمر بهبودیافته معماریهای جدید مانند XLNet، RoBERTa و ALBERT در حال بهبود عملکرد یادگیری انتقالی هستند. RoBERTa نشان داده که صرفاً آموزش BERT برای مدت طولانیتر و با دادههای بیشتر، نتایج را بهبود میبخشد.
مدلهای کارآمد برای دستگاههای موبایل MobileBERT به عنوان نسخه فشرده BERT برای دستگاههای موبایل طراحی شده و بر سرعت و کارایی تمرکز دارد.
۳. یادگیری چندزبانه
یکی از وعدههای اصلی پیشآموزش این است که میتواند به ما کمک کند شکاف زبانی دیجیتال را پر کنیم و یادگیری مدلهای NLP را برای بیشتر از ۶۰۰۰ زبان دنیا امکانپذیر سازد. روشهای رایج شامل:
- یادگیری نمایشهای متنی در زبانهای مختلف و همراستا کردن آنها
- اشتراک واژگان زیرکلمه و آموزش یک مدل بر روی چندین زبان
۴. هوش مصنوعی توضیحپذیر (Explainable AI)
با رشد استفاده از یادگیری انتقالی در حوزههای حساس مانند پزشکی و خودروهای خودران، نیاز به مدلهای قابل تفسیر افزایش یافته است. تحقیقات آینده بر توسعه روشهایی تمرکز دارند که نهتنها عملکرد بالایی داشته باشند، بلکه توانایی توضیح تصمیمات خود را نیز داشته باشند.
۵. یادگیری انتقالی در محیطهای پویا
سازگاری مداوم مدلهای آینده باید قادر به یادگیری مداوم از محیط و سازگاری با تغییرات بدون فراموشی دانش قبلی (Catastrophic Forgetting) باشند.
یادگیری چندوظیفهای (Multi-Task Learning) این رویکرد به مدلها اجازه میدهد همزمان چندین وظیفه را یاد بگیرند و دانش مشترک بین آنها را به اشتراک بگذارند.
چالشها و محدودیتهای فعلی
۱. انتقال منفی (Negative Transfer)
زمانی که انتقال دانش از منبع به هدف نهتنها بهبودی ایجاد نمیکند، بلکه باعث کاهش عملکرد میشود. این اتفاق معمولاً زمانی رخ میدهد که دامنه منبع و هدف شباهت کافی نداشته باشند.
۲. فراموشی فاجعهآمیز
هنگام تنظیم دقیق مدل پیشآموزشدیده، خطر وجود دارد که مدل دانش زبان عمومی کسبشده در طول پیشآموزش را فراموش کند.
۳. منابع محاسباتی
تنظیم دقیق مدلهای بزرگ پیشآموزشدیده مانند GPT-3 یا BERT هنوز نیازمند منابع محاسباتی قابل توجهی از جمله GPUهای قدرتمند و حافظه قابل توجه است.
۴. عدم تطابق دامنه
اگر عدم تطابق قابل توجهی بین دامنه مجموعه داده پیشآموزش و دامنه وظیفه تنظیم دقیق وجود داشته باشد، مدل ممکن است بهخوبی منتقل نشود.
فرصتهای تحقیقاتی آینده
۱. یادگیری فدرال پیشرفته
توسعه الگوریتمهای یادگیری فدرال که بتوانند در محیطهای ناهمگن با دادههای غیرهمسان (Non-IID) بهطور کارآمد کار کنند.
۲. یادگیری انتقالی خودکار (AutoML for Transfer Learning)
توسعه سیستمهای خودکار که بهترین استراتژی یادگیری انتقالی را برای یک وظیفه خاص انتخاب کنند.
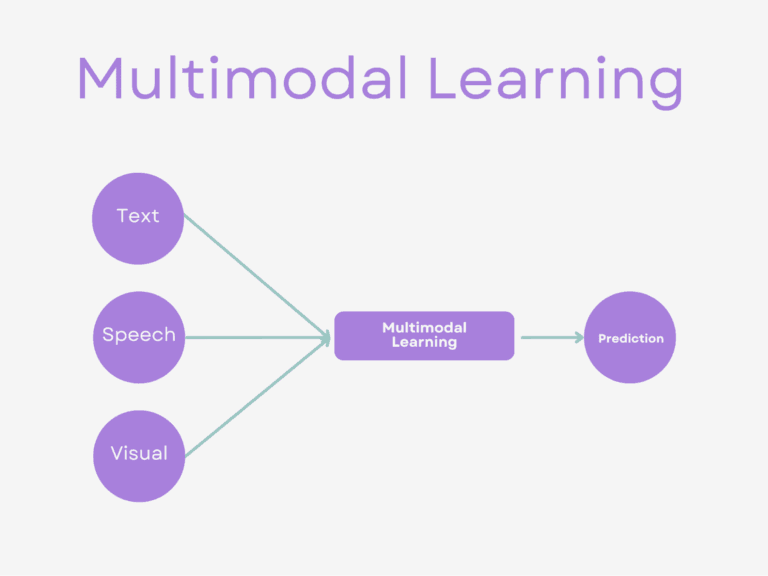
۳. یادگیری چندحسی (Multi-Modal Learning)
ادغام اطلاعات از حالتهای مختلف (تصویر، متن، صدا) برای ایجاد مدلهای جامعتر و قدرتمندتر.
۴. کاهش تعصب و افزایش عدالت
تحقیقات نشان میدهد که یادگیری انتقالی میتواند به کاهش نابرابریهای مراقبتهای بهداشتی ناشی از نابرابری دادههای زیستپزشکی بین گروههای قومی مختلف کمک کند. یادگیری انتقالی عمیق میتواند عملکرد مدل را برای گروههای قومی محروم از داده بهبود بخشد.
۵. بهینهسازی برای دستگاههای محدود منابع
توسعه تکنیکهای فشردهسازی مدل، کوانتیزاسیون و هرس (Pruning) برای اجرای مدلهای پیچیده بر روی دستگاههای با منابع محدود.
مطالعات موردی
مطالعه موردی ۱: تشخیص سرطان پوست
یک مدل CNN که از ابتدا آموزش داده شد، امتیاز F1 برابر ۸۹.۰۹% حاصل کرد، در حالی که همان مدل با استفاده از یادگیری انتقالی به ۹۸.۵۳% رسید. این نشاندهنده بهبود ۱۰% در عملکرد است.
مطالعه موردی ۲: طبقهبندی سرطان پستان
مدل از ابتدا: دقت ۸۵.۲۹% مدل با یادگیری انتقالی: دقت ۹۷.۵۱% این نتایج نشان میدهند که یادگیری انتقالی میتواند بهطور قابل توجهی عملکرد در مسائل تصویربرداری پزشکی را بهبود بخشد.
مطالعه موردی ۳: خودروهای خودران Waymo
با استفاده از AutoML و یادگیری انتقالی:
- کاهش ۲۰-۳۰% در تأخیر شبکه عصبی
- کاهش ۸-۱۰% در نرخ خطا
- زمان محاسباتی از بیش از یک سال به تنها دو هفته کاهش یافت
چشمانداز ۲۰۲۵ و فراتر از آن
توسعههای فناوری
۱. قدرت محاسباتی بهبودیافته رشد مداوم در منابع محاسباتی امکان آموزش مدلهای بزرگتر و پیچیدهتر را فراهم میکند.
۲. معماریهای شبکه عصبی پیشرفته با ظهور معماریهای پیچیدهتر، مدلهای یادگیری انتقالی کارآمدتر و قادر به انجام وظایف پیچیدهتر خواهند بود.
۳. دسترسی گستردهتر ابزارها و کتابخانههای منبعباز مانند TensorFlow، PyTorch و Hugging Face، یادگیری انتقالی پیشرفته را برای محققان و کسبوکارهای کوچک در دسترستر میکنند.
کاربردهای نوظهور
شهرهای هوشمند یادگیری انتقالی در مدیریت ترافیک، بهینهسازی مصرف انرژی و بهبود خدمات شهری نقش کلیدی خواهد داشت.
آموزش شخصیسازیشده سیستمهای آموزشی با استفاده از یادگیری انتقالی میتوانند به سرعت به سبک یادگیری فردی دانشآموزان سازگار شوند.
تشخیص و مدیریت بحران در شرایط اضطراری، مدلهای یادگیری انتقالی میتوانند به سرعت به شرایط جدید سازگار شوند و به تصمیمگیری سریع کمک کنند.
نتیجهگیری
یادگیری انتقالی به عنوان یکی از حیاتیترین پیشرفتها در هوش مصنوعی، در حال تغییر اساسی نحوه توسعه و استقرار سیستمهای یادگیری ماشین است. از تشخیص بیماریها در پزشکی تا خودروهای خودران، از کشاورزی دقیق تا محاسبات لبه، تأثیر این فناوری عمیق و گسترده است.
با نگاهی به آینده، میتوانیم انتظار داشته باشیم که یادگیری انتقالی:
۱. کارآمدتر شود با توسعه الگوریتمهای بهینهتر و معماریهای شبکه عصبی پیشرفته
۲. در دسترستر گردد با ابزارهای منبعباز و پلتفرمهای ابری که هزینهها را کاهش میدهند
۳. قدرتمندتر باشد با یادگیری از دادههای چندحسی و توانایی سازگاری سریعتر با وظایف جدید
۴. مسئولانهتر شود با تمرکز بر عدالت، کاهش تعصب و توضیحپذیری