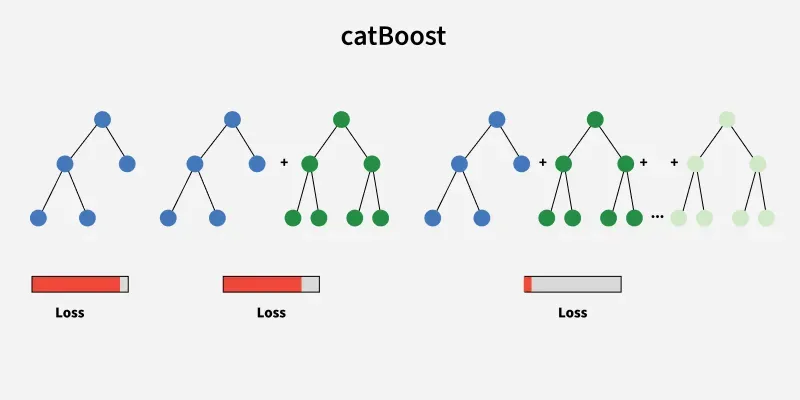
الگوریتم CatBoost یکی از پیشرفتهترین روشهای یادگیری ماشین مبتنی بر تقویت گرادیان (Gradient Boosting) است که توسط محققان شرکت یاندکس توسعه یافته است. این الگوریتم با قابلیت پردازش خودکار ویژگیهای دستهای و استفاده از تکنیکهای نوآورانه مانند تقویت مرتبشده (Ordered Boosting)، توانسته است عملکرد برتری نسبت به الگوریتمهای مشابه از جمله XGBoost و LightGBM از خود نشان دهد. در این مقاله به بررسی جامع اصول نظری، معماری، پیادهسازی عملی و تنظیم فراپارامترهای الگوریتم CatBoost برای مسائل طبقهبندی میپردازیم.
فهرست مطالب
- مقدمه
- مبانی نظری الگوریتم CatBoost
- معماری و ویژگیهای منحصربهفرد
- پیادهسازی عملی در پایتون
- تنظیم فراپارامترها
- مقایسه با سایر الگوریتمها
- کاربردهای عملی
- نتیجهگیری
- منابع و مراجع
مقدمه
در دنیای امروز، دادههای ساختاریافته (Tabular Data) بخش عمدهای از مسائل یادگیری ماشین را تشکیل میدهند. از پیشبینی رفتار مشتریان در تجارت الکترونیک تا تشخیص بیماریها در حوزه پزشکی، همه نیازمند الگوریتمهایی هستند که بتوانند با دقت بالا، الگوهای پیچیده را در دادهها شناسایی کنند.
الگوریتمهای مبتنی بر تقویت گرادیان (Gradient Boosting Decision Trees یا GBDT) از جمله موفقترین روشهای یادگیری ماشین برای دادههای ساختاریافته به شمار میروند. CatBoost که مخفف “Categorical Boosting” است، نسل جدیدی از این الگوریتمها را نمایندگی میکند که چالشهای اساسی روشهای سنتی را برطرف نموده است.
اهمیت موضوع
یکی از چالشهای اصلی در یادگیری ماشین، پردازش صحیح ویژگیهای دستهای (Categorical Features) است. در اکثر الگوریتمهای سنتی، نیاز به تبدیل این ویژگیها به اعداد از طریق روشهایی مانند کدگذاری یک-گرم (One-Hot Encoding) یا کدگذاری برچسبی (Label Encoding) وجود دارد. این فرآیند علاوه بر زمانبر بودن، میتواند منجر به از دست رفتن اطلاعات مهم یا افزایش ابعاد داده شود. CatBoost با ارائه روشی هوشمند برای پردازش خودکار این ویژگیها، این مشکل را به طور بنیادین حل کرده است.
مبانی نظری الگوریتم CatBoost
تقویت گرادیان: پایه و اساس
تقویت گرادیان یک روش یادگیری گروهی (Ensemble Learning) است که در آن، مدلهای ضعیف (معمولاً درختهای تصمیم) به صورت متوالی آموزش داده میشوند. در هر مرحله، مدل جدید سعی میکند خطاهای مدلهای قبلی را تصحیح کند.
فرآیند کلی به شرح زیر است:
- مدل اولیه: با یک پیشبینی ساده (مثلاً میانگین مقادیر هدف) شروع میکنیم
- محاسبه باقیماندهها: خطاهای مدل فعلی محاسبه میشود
- آموزش مدل جدید: یک درخت تصمیم جدید برای پیشبینی این خطاها آموزش داده میشود
- بهروزرسانی مدل: مدل جدید با وزن مناسب به مدل کلی اضافه میشود
- تکرار: این فرآیند تا رسیدن به تعداد تکرار مشخص یا همگرایی ادامه مییابد
معادلات ریاضی
مدل نهایی در تقویت گرادیان به صورت زیر تعریف میشود:
F(x) = F₀(x) + η · Σᵢ₌₁ⁿ hᵢ(x)
که در آن:
- F(x): مدل نهایی
- F₀(x): مدل اولیه
- η: نرخ یادگیری (Learning Rate)
- hᵢ(x): درخت تصمیم i-ام
- n: تعداد درختها
تابع هدف که باید کمینه شود:
L = Σⱼ L(yⱼ, F(xⱼ)) + Σᵢ Ω(hᵢ)
که در آن:
- L(y, F(x)): تابع زیان
- Ω(h): جمله منظمسازی
مشکل تغییر پیشبینی (Prediction Shift)
یکی از مشکلات اساسی در الگوریتمهای GBDT سنتی، پدیدهای به نام “تغییر پیشبینی” است که ناشی از نشت هدف (Target Leakage) میباشد. این مشکل زمانی رخ میدهد که از همان دادههایی که برای آموزش مدل استفاده شده، برای محاسبه گرادیانها نیز استفاده میشود. این امر میتواند منجر به بیشبرازش (Overfitting) شود.
معماری و ویژگیهای منحصربهفرد
1. تقویت مرتبشده (Ordered Boosting)
تقویت مرتبشده مهمترین نوآوری الگوریتم CatBoost است که برای حل مشکل تغییر پیشبینی طراحی شده است.
نحوه عملکرد:
- CatBoost جایگشتهای تصادفی از دادههای آموزشی ایجاد میکند
- برای هر نمونه، تنها از دادههای قبلی در جایگشت برای محاسبه آمارها استفاده میشود
- این رویکرد از الگوریتمهای یادگیری آنلاین الهام گرفته شده است
- با استفاده از چند جایگشت مختلف، واریانس مدل کاهش مییابد
مزایا:
- جلوگیری از نشت هدف
- کاهش بیشبرازش بهویژه در مجموعه دادههای کوچک
- بهبود قدرت تعمیمدهی مدل
دو حالت تقویت در CatBoost:
- حالت Plain: ترکیبی از GBDT استاندارد با آمارهای هدف مرتبشده
- حالت Ordered: استفاده کامل از تقویت مرتبشده با نگهداری مدلهای پشتیبان
2. پردازش خودکار ویژگیهای دستهای
CatBoost از روش نوآورانهای برای پردازش ویژگیهای دستهای استفاده میکند که به آمارهای هدف مرتبشده (Ordered Target Statistics) معروف است.
روش سنتی (Target Statistics):
برای یک ویژگی دستهای با مقدار c، میانگین مقادیر هدف محاسبه میشود:
TS(c) = (Σ yᵢ) / n
این روش مستعد نشت هدف است.
روش CatBoost (Ordered TS):
برای نمونه i با مقدار دستهای c در جایگشت σ:
TS(xᵢ) = (Σⱼ<ᵢ yⱼ · I[xⱼ = c] + α·P) / (Σⱼ<ᵢ I[xⱼ = c] + α)
که در آن:
- I: تابع نشانگر
- α: پارامتر هموارسازی
- P: مقدار پیشین (Prior)
این روش تنها از دادههای قبلی استفاده میکند و از نشت هدف جلوگیری میکند.
3. درختهای متقارن (Symmetric Trees)
برخلاف الگوریتمهای دیگر که درختهای نامتقارن میسازند، CatBoost از درختهای متقارن (Oblivious Trees) استفاده میکند.
ویژگیها:
- در هر سطح، همه برگها با یک شرط تقسیم میشوند
- ساختار درخت کاملاً متقارن است
- عمق درخت به جای تعداد برگها کنترل میشود
مزایا:
- سرعت پیشبینی بسیار بالا (تا 10 برابر سریعتر)
- پیادهسازی کارآمد بر روی CPU
- عملکرد به عنوان یک نوع منظمسازی
- کاهش احتمال بیشبرازش
4. پشتیبانی از GPU
CatBoost از آموزش بر روی GPU به صورت کامل پشتیبانی میکند که منجر به تسریع چشمگیر فرآیند آموزش میشود.
قابلیتها:
- پشتیبانی از چند GPU به صورت همزمان
- تنظیمات ساده برای استفاده از GPU
- بهینهسازی خاص برای معماری GPU
5. تشخیص خودکار بیشبرازش
CatBoost دارای مکانیزم تشخیص خودکار بیشبرازش است که میتواند آموزش را در صورت مشاهده نشانههای بیشبرازش متوقف کند.
پیادهسازی عملی در پایتون
نصب کتابخانه
برای نصب CatBoost از دستور زیر استفاده میکنیم:
pip install catboost
یا برای استفاده از conda:
conda install -c conda-forge catboost
مثال 1: طبقهبندی دودویی ساده
import pandas as pd
import numpy as np
from catboost import CatBoostClassifier, Pool
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# بارگذاری دادهها
# فرض میکنیم یک مجموعه داده با ویژگیهای عددی و دستهای داریم
df = pd.read_csv('data.csv')
# جداسازی ویژگیها و برچسبها
X = df.drop('target', axis=1)
y = df['target']
# مشخص کردن ویژگیهای دستهای
categorical_features = ['gender', 'occupation', 'education', 'marital_status']
# تقسیم داده به مجموعه آموزش و آزمون
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# ایجاد مدل CatBoost
model = CatBoostClassifier(
iterations=1000, # تعداد درختها
learning_rate=0.03, # نرخ یادگیری
depth=6, # عمق درختها
loss_function='Logloss', # تابع زیان
eval_metric='AUC', # معیار ارزیابی
random_seed=42, # بذر تصادفی برای تکرارپذیری
verbose=100 # نمایش پیشرفت هر 100 تکرار
)
# آموزش مدل
model.fit(
X_train, y_train,
cat_features=categorical_features,
eval_set=(X_test, y_test),
early_stopping_rounds=50, # توقف زودهنگام
plot=True # نمایش نمودار یادگیری
)
# پیشبینی
y_pred = model.predict(X_test)
y_pred_proba = model.predict_proba(X_test)
# ارزیابی
accuracy = accuracy_score(y_test, y_pred)
print(f"دقت مدل: {accuracy:.4f}")
print("\nگزارش طبقهبندی:")
print(classification_report(y_test, y_pred))
2: استفاده از Pool برای مدیریت بهتر داده
# ایجاد Pool برای دادههای آموزش و آزمون
train_pool = Pool(
data=X_train,
label=y_train,
cat_features=categorical_features
)
test_pool = Pool(
data=X_test,
label=y_test,
cat_features=categorical_features
)
# آموزش با استفاده از Pool
model = CatBoostClassifier(
iterations=1000,
learning_rate=0.05,
depth=8,
l2_leaf_reg=3,
boosting_type='Ordered', # استفاده از تقویت مرتبشده
bootstrap_type='Bayesian',
random_strength=1,
verbose=False
)
model.fit(train_pool, eval_set=test_pool, verbose=100)
3: طبقهبندی چندکلاسه
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# بارگذاری مجموعه داده Iris
iris = load_iris()
X, y = iris.data, iris.target
# تقسیم داده
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
# مدل طبقهبندی چندکلاسه
model = CatBoostClassifier(
iterations=500,
learning_rate=0.1,
depth=5,
loss_function='MultiClass', # تابع زیان برای طبقهبندی چندکلاسه
eval_metric='Accuracy',
verbose=False
)
# آموزش
model.fit(X_train, y_train, eval_set=(X_test, y_test))
# پیشبینی
y_pred = model.predict(X_test)
# ارزیابی
accuracy = accuracy_score(y_test, y_pred)
print(f"دقت مدل: {accuracy:.4f}")
4: مدیریت دادههای گمشده
import numpy as np
# ایجاد دادههای گمشده مصنوعی
X_train_missing = X_train.copy()
X_test_missing = X_test.copy()
# اضافه کردن مقادیر NaN به صورت تصادفی
mask = np.random.rand(*X_train_missing.shape) < 0.1
X_train_missing[mask] = np.nan
# CatBoost به صورت خودکار دادههای گمشده را مدیریت میکند
model_with_missing = CatBoostClassifier(
iterations=1000,
learning_rate=0.05,
depth=6,
nan_mode='Min', # روش مدیریت دادههای گمشده
verbose=False
)
model_with_missing.fit(
X_train_missing, y_train,
cat_features=categorical_features,
eval_set=(X_test, y_test)
)
5: ذخیره و بارگذاری مدل
# ذخیره مدل
model.save_model('catboost_model.cbm')
# یا در فرمت JSON
model.save_model('catboost_model.json', format='json')
# بارگذاری مدل
loaded_model = CatBoostClassifier()
loaded_model.load_model('catboost_model.cbm')
# استفاده از مدل بارگذاری شده
predictions = loaded_model.predict(X_test)
تنظیم فراپارامترها
تنظیم صحیح فراپارامترها نقش حیاتی در دستیابی به بهترین عملکرد مدل دارد.
فراپارامترهای کلیدی
1. iterations (تعداد تکرارها)
توضیح: تعداد درختهایی که باید ساخته شود.
محدوده پیشنهادی: 100 تا 10000
نکات:
- مقادیر بالاتر معمولاً به دقت بهتر منجر میشود اما زمان آموزش افزایش مییابد
- از early_stopping برای جلوگیری از بیشبرازش استفاده کنید
- برای مجموعه دادههای کوچک، 500-1000 معمولاً کافی است
model = CatBoostClassifier(iterations=1000)
2. learning_rate (نرخ یادگیری)
توضیح: سهم هر درخت در مدل نهایی را کنترل میکند.
محدوده پیشنهادی: 0.001 تا 0.3
نکات:
- مقادیر کوچکتر نیاز به iterations بیشتر دارند اما معمولاً به دقت بهتر منجر میشوند
- مقادیر متداول: 0.03، 0.05، 0.1
model = CatBoostClassifier(learning_rate=0.05)
3. depth (عمق درخت)
توضیح: حداکثر عمق درختهای تصمیم.
محدوده پیشنهادی: 4 تا 16
نکات:
- عمق بیشتر = پیچیدگی بیشتر = احتمال بیشبرازش بیشتر
- برای اکثر مسائل، عمق 6-10 مناسب است
- برای دادههای کوچک، عمق 4-6 توصیه میشود
model = CatBoostClassifier(depth=8)
4. l2_leaf_reg (منظمسازی L2)
توضیح: ضریب منظمسازی L2 برای تابع هزینه.
محدوده پیشنهادی: 1 تا 10
نکات:
- مقادیر بالاتر به کاهش بیشبرازش کمک میکنند
- پارامتر کلیدی برای بهینهسازی
model = CatBoostClassifier(l2_leaf_reg=3)
5. boosting_type (نوع تقویت)
توضیح: نوع الگوریتم تقویت.
مقادیر ممکن:
- ‘Ordered’: تقویت مرتبشده (بهتر برای دادههای کوچک)
- ‘Plain’: تقویت استاندارد (سریعتر)
model = CatBoostClassifier(boosting_type='Ordered')
6. random_strength
توضیح: مقدار تصادفیسازی در انتخاب تقسیمها.
محدوده پیشنهادی: 0 تا 10
نکات:
- مقادیر بالاتر منجر به تصادفیسازی بیشتر و کاهش بیشبرازش میشود
model = CatBoostClassifier(random_strength=1.5)
7. bagging_temperature
توضیح: کنترل شدت نمونهبرداری تصادفی.
محدوده پیشنهادی: 0 تا 1
نکات:
- 0: نمونهبرداری قطعی (بدون تصادفیسازی)
- 1: نمونهبرداری کاملاً تصادفی
model = CatBoostClassifier(bagging_temperature=0.5)
روشهای تنظیم فراپارامترها
1. جستجوی شبکهای (Grid Search)
from sklearn.model_selection import GridSearchCV
# تعریف فضای جستجو
param_grid = {
'iterations': [500, 1000],
'learning_rate': [0.03, 0.1],
'depth': [4, 6, 8],
'l2_leaf_reg': [1, 3, 5]
}
# ایجاد مدل پایه
base_model = CatBoostClassifier(
loss_function='Logloss',
verbose=False
)
# جستجوی شبکهای
grid_search = GridSearchCV(
estimator=base_model,
param_grid=param_grid,
cv=5,
scoring='accuracy',
n_jobs=-1,
verbose=2
)
# اجرای جستجو
grid_search.fit(X_train, y_train, cat_features=categorical_features)
# بهترین پارامترها
print("بهترین پارامترها:", grid_search.best_params_)
print("بهترین امتیاز:", grid_search.best_score_)
# استفاده از بهترین مدل
best_model = grid_search.best_estimator_
2. جستجوی تصادفی (Random Search)
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import uniform, randint
# تعریف توزیعهای پارامتر
param_distributions = {
'iterations': randint(500, 2000),
'learning_rate': uniform(0.01, 0.3),
'depth': randint(4, 12),
'l2_leaf_reg': uniform(1, 10),
'random_strength': uniform(0, 2)
}
# جستجوی تصادفی
random_search = RandomizedSearchCV(
estimator=base_model,
param_distributions=param_distributions,
n_iter=50, # تعداد ترکیبها
cv=5,
scoring='roc_auc',
n_jobs=-1,
verbose=2,
random_state=42
)
random_search.fit(X_train, y_train, cat_features=categorical_features)
3. استفاده از grid_search داخلی CatBoost
# تعریف شبکه پارامترها
grid = {
'learning_rate': [0.03, 0.1],
'depth': [4, 6, 10],
'l2_leaf_reg': [1, 3, 5, 7, 9]
}
# ایجاد Pool
train_pool = Pool(X_train, y_train, cat_features=categorical_features)
# مدل با grid search داخلی
model = CatBoostClassifier(
iterations=1000,
loss_function='Logloss',
eval_metric='AUC'
)
# اجرای grid search
grid_search_result = model.grid_search(
grid,
train_pool,
cv=5,
plot=True,
verbose=False
)
print("بهترین پارامترها:", grid_search_result['params'])
4. بهینهسازی بیزی با Optuna
import optuna
from catboost import CatBoostClassifier
def objective(trial):
# تعریف فضای جستجو
params = {
'iterations': trial.suggest_int('iterations', 500, 2000),
'learning_rate': trial.suggest_float('learning_rate', 0.01, 0.3),
'depth': trial.suggest_int('depth', 4, 10),
'l2_leaf_reg': trial.suggest_float('l2_leaf_reg', 1, 10),
'random_strength': trial.suggest_float('random_strength', 0, 2),
'bagging_temperature': trial.suggest_float('bagging_temperature', 0, 1),
'border_count': trial.suggest_int('border_count', 32, 255)
}
# ایجاد و آموزش مدل
model = CatBoostClassifier(
**params,
loss_function='Logloss',
eval_metric='AUC',
verbose=False,
random_seed=42
)
model.fit(
X_train, y_train,
cat_features=categorical_features,
eval_set=(X_test, y_test),
early_stopping_rounds=50
)
# ارزیابی
y_pred_proba = model.predict_proba(X_test)[:, 1]
score = roc_auc_score(y_test, y_pred_proba)
return score
# ایجاد مطالعه و بهینهسازی
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=100, timeout=3600)
# نمایش بهترین پارامترها
print("بهترین امتیاز:", study.best_value)
print("بهترین پارامترها:", study.best_params)
# آموزش مدل نهایی با بهترین پارامترها
final_model = CatBoostClassifier(**study.best_params, verbose=False)
final_model.fit(X_train, y_train, cat_features=categorical_features)
جدول راهنمای تنظیم پارامترها
| پارامتر | مقدار پایه | مقدار محافظهکارانه | مقدار پرخطر | توضیحات |
|---|---|---|---|---|
| iterations | 1000 | 500-1000 | 2000-5000 | با early_stopping استفاده کنید |
| learning_rate | 0.03 | 0.01-0.05 | 0.1-0.3 | کمتر = دقیقتر اما کندتر |
| depth | 6 | 4-6 | 8-12 | عمق کمتر = کمتر بیشبرازش |
| l2_leaf_reg | 3 | 5-10 | 1-2 | بالاتر = منظمسازی بیشتر |
| random_strength | 1 | 1-2 | 0-0.5 | بالاتر = تصادفیسازی بیشتر |
مقایسه با سایر الگوریتمها
CatBoost در مقابل XGBoost
| ویژگی | CatBoost | XGBoost |
|---|---|---|
| پردازش ویژگیهای دستهای | خودکار و داخلی | نیاز به پیشپردازش دستی |
| نوع درخت | متقارن (Oblivious) | نامتقارن |
| سرعت پیشبینی | سریعتر (تا 10 برابر) | سریع |
| دقت پیشفرض | بالا | نیاز به تنظیم دقیق |
| مدیریت بیشبرازش | تقویت مرتبشده | منظمسازی سنتی |
| سهولت استفاده | بسیار ساده | متوسط |
| مستندات | عالی | خوب |
CatBoost در مقابل LightGBM
| ویژگی | CatBoost | LightGBM |
|---|---|---|
| سرعت آموزش | متوسط تا سریع | بسیار سریع |
| مصرف حافظه | متوسط | کم |
| دقت با تنظیمات پیشفرض | بالا | متوسط |
| ویژگیهای دستهای | عالی | خوب |
| مجموعه دادههای کوچک | عالی | متوسط |
| مجموعه دادههای بزرگ | خوب | عالی |
مثال عملی مقایسه
from catboost import CatBoostClassifier
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
from sklearn.model_selection import cross_val_score
import time
# دادههای آزمایشی
X_train_encoded = X_train.copy()
for col in categorical_features:
X_train_encoded[col] = X_train_encoded[col].astype('category').cat.codes
# تعریف مدلها
models = {
'CatBoost': CatBoostClassifier(
iterations=500,
learning_rate=0.1,
depth=6,
verbose=False
),
'XGBoost': XGBClassifier(
n_estimators=500,
learning_rate=0.1,
max_depth=6,
random_state=42
),
'LightGBM': LGBMClassifier(
n_estimators=500,
learning_rate=0.1,
max_depth=6,
random_state=42
)
}
# مقایسه عملکرد
results = {}
for name, model in models.items():
start_time = time.time()
if name == 'CatBoost':
model.fit(X_train, y_train, cat_features=categorical_features)
scores = cross_val_score(model, X_train, y_train, cv=5, scoring='accuracy')
else:
model.fit(X_train_encoded, y_train)
scores = cross_val_score(model, X_train_encoded, y_train, cv=5, scoring='accuracy')
training_time = time.time() - start_time
results[name] = {
'accuracy_mean': scores.mean(),
'accuracy_std': scores.std(),
'training_time': training_time
}
print(f"\n{name}:")
print(f" دقت میانگین: {scores.mean():.4f} (±{scores.std():.4f})")
print(f" زمان آموزش: {training_time:.2f} ثانیه")
کاربردهای عملی
1. پیشبینی ریزش مشتریان (Customer Churn)
# مثال کاربردی: پیشبینی ریزش مشتریان
import pandas as pd
from catboost import CatBoostClassifier
from sklearn.metrics import roc_auc_score, precision_recall_curve
# فرض: دادههای مشتریان با ویژگیهای دستهای
categorical_cols = ['contract_type', 'payment_method', 'internet_service']
# مدل پیشبینی ریزش
churn_model = CatBoostClassifier(
iterations=1000,
learning_rate=0.05,
depth=6,
loss_function='Logloss',
eval_metric='AUC',
class_weights=[1, 3], # وزن بیشتر برای کلاس ریزش
random_seed=42
)
# آموزش
churn_model.fit(
X_train, y_train,
cat_features=categorical_cols,
eval_set=(X_test, y_test),
early_stopping_rounds=50
)
# پیشبینی احتمال ریزش
churn_probabilities = churn_model.predict_proba(X_test)[:, 1]
# تحلیل اهمیت ویژگیها
feature_importance = churn_model.get_feature_importance(prettified=True)
print("\nمهمترین ویژگیها در پیشبینی ریزش:")
print(feature_importance.head(10))
2. تشخیص تقلب (Fraud Detection)
# مدل تشخیص تقلب با دادههای نامتوازن
fraud_model = CatBoostClassifier(
iterations=2000,
learning_rate=0.03,
depth=8,
loss_function='Logloss',
auto_class_weights='Balanced', # تنظیم خودکار وزن کلاسها
bootstrap_type='Bernoulli',
subsample=0.7,
random_seed=42
)
# آموزش با دادههای نامتوازن
fraud_model.fit(
X_train, y_train,
cat_features=categorical_features,
eval_set=(X_test, y_test),
metric_period=100
)
# ارزیابی با معیارهای مناسب برای داده نامتوازن
from sklearn.metrics import precision_recall_fscore_support, roc_curve
y_pred = fraud_model.predict(X_test)
y_pred_proba = fraud_model.predict_proba(X_test)[:, 1]
precision, recall, f1, _ = precision_recall_fscore_support(
y_test, y_pred, average='binary'
)
print(f"دقت (Precision): {precision:.4f}")
print(f"بازخوانی (Recall): {recall:.4f}")
print(f"F1-Score: {f1:.4f}")
print(f"AUC-ROC: {roc_auc_score(y_test, y_pred_proba):.4f}")
3. سیستم توصیهگر (Recommender System)
# پیشبینی احتمال کلیک (CTR Prediction)
ctr_model = CatBoostClassifier(
iterations=3000,
learning_rate=0.02,
depth=10,
loss_function='Logloss',
eval_metric='AUC',
cat_features=['user_id', 'item_id', 'category', 'device_type'],
verbose=200
)
# آموزش با دادههای تعاملی
ctr_model.fit(
interactions_train, clicks_train,
eval_set=(interactions_test, clicks_test)
)
# رتبهبندی آیتمها برای کاربر
def recommend_items(user_id, n_recommendations=10):
user_items = create_user_item_pairs(user_id, available_items)
scores = ctr_model.predict_proba(user_items)[:, 1]
top_indices = np.argsort(scores)[-n_recommendations:][::-1]
return available_items[top_indices]
4. طبقهبندی متن (Text Classification)
from catboost import CatBoostClassifier
from sklearn.feature_extraction.text import TfidfVectorizer
# استخراج ویژگیهای متنی
vectorizer = TfidfVectorizer(max_features=5000)
X_train_tfidf = vectorizer.fit_transform(texts_train)
X_test_tfidf = vectorizer.transform(texts_test)
# مدل طبقهبندی متن
text_classifier = CatBoostClassifier(
iterations=1000,
learning_rate=0.1,
depth=6,
loss_function='MultiClass',
random_seed=42
)
# آموزش
text_classifier.fit(
X_train_tfidf, labels_train,
eval_set=(X_test_tfidf, labels_test)
)
تکنیکهای پیشرفته
1. مدیریت دادههای نامتوازن
# روش 1: استفاده از class_weights
model_weighted = CatBoostClassifier(
iterations=1000,
class_weights={0: 1, 1: 10}, # وزن بیشتر برای کلاس اقلیت
verbose=False
)
# روش 2: auto_class_weights
model_auto = CatBoostClassifier(
iterations=1000,
auto_class_weights='Balanced',
verbose=False
)
# روش 3: scale_pos_weight (برای طبقهبندی دودویی)
neg_count = (y_train == 0).sum()
pos_count = (y_train == 1).sum()
scale_pos_weight = neg_count / pos_count
model_scaled = CatBoostClassifier(
iterations=1000,
scale_pos_weight=scale_pos_weight,
verbose=False
)
2. انتخاب ویژگی (Feature Selection)
# استفاده از اهمیت ویژگیها برای انتخاب
model = CatBoostClassifier(iterations=1000, verbose=False)
model.fit(X_train, y_train, cat_features=categorical_features)
# دریافت اهمیت ویژگیها
feature_importance = model.get_feature_importance()
feature_names = X_train.columns
# انتخاب بهترین ویژگیها
importance_df = pd.DataFrame({
'feature': feature_names,
'importance': feature_importance
}).sort_values('importance', ascending=False)
# انتخاب 80% بهترین ویژگیها
threshold = importance_df['importance'].quantile(0.2)
selected_features = importance_df[
importance_df['importance'] > threshold
]['feature'].tolist()
# آموزش مدل با ویژگیهای منتخب
X_train_selected = X_train[selected_features]
X_test_selected = X_test[selected_features]
model_selected = CatBoostClassifier(iterations=1000, verbose=False)
model_selected.fit(X_train_selected, y_train)
3. مهندسی ویژگی با CatBoost
# ترکیب ویژگیهای دستهای
model_with_combinations = CatBoostClassifier(
iterations=1000,
cat_features=categorical_features,
one_hot_max_size=10, # استفاده از one-hot برای ویژگیهای کمتعداد
combinations=[['feature1', 'feature2'], ['feature3', 'feature4']],
verbose=False
)
# آموزش
model_with_combinations.fit(X_train, y_train)
4. تحلیل SHAP برای تفسیرپذیری
import shap
# ایجاد توضیحدهنده SHAP
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_test)
# نمودار خلاصه
shap.summary_plot(shap_values, X_test, plot_type="bar")
# توضیح برای یک نمونه خاص
shap.force_plot(
explainer.expected_value,
shap_values[0],
X_test.iloc[0]
)
# نمودار وابستگی
shap.dependence_plot(
"feature_name",
shap_values,
X_test
)
5. اعتبارسنجی متقاطع سفارشی
from sklearn.model_selection import StratifiedKFold
# تعریف استراتژی اعتبارسنجی
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
# ذخیره نتایج
cv_scores = []
cv_predictions = np.zeros(len(X_train))
for fold, (train_idx, val_idx) in enumerate(skf.split(X_train, y_train)):
print(f"\nآموزش Fold {fold + 1}")
X_fold_train = X_train.iloc[train_idx]
y_fold_train = y_train.iloc[train_idx]
X_fold_val = X_train.iloc[val_idx]
y_fold_val = y_train.iloc[val_idx]
model_fold = CatBoostClassifier(
iterations=1000,
learning_rate=0.05,
depth=6,
verbose=False
)
model_fold.fit(
X_fold_train, y_fold_train,
cat_features=categorical_features,
eval_set=(X_fold_val, y_fold_val),
early_stopping_rounds=50
)
# پیشبینی
fold_predictions = model_fold.predict_proba(X_fold_val)[:, 1]
cv_predictions[val_idx] = fold_predictions
# ارزیابی
fold_score = roc_auc_score(y_fold_val, fold_predictions)
cv_scores.append(fold_score)
print(f"AUC Fold {fold + 1}: {fold_score:.4f}")
print(f"\nمیانگین AUC: {np.mean(cv_scores):.4f} (±{np.std(cv_scores):.4f})")
بهترین شیوهها و نکات کاربردی
1. پیشپردازش داده
# نکات مهم پیشپردازش
# 1. CatBoost نیازی به نرمالسازی ندارد
# 2. میتواند با مقادیر گمشده کار کند
# 3. ویژگیهای دستهای را خودکار پردازش میکند
# مثال کامل پیشپردازش
def preprocess_data(df, categorical_cols):
# حذف ستونهای غیرضروری
df = df.drop(['id', 'timestamp'], axis=1, errors='ignore')
# تبدیل نوع دادههای دستهای
for col in categorical_cols:
df[col] = df[col].astype(str)
# مدیریت مقادیر نامعتبر
df = df.replace([np.inf, -np.inf], np.nan)
return df
X_processed = preprocess_data(X, categorical_features)
2. مانیتورینگ آموزش
# استفاده از callback برای مانیتورینگ
class CustomCallback:
def __init__(self):
self.best_score = 0
self.best_iteration = 0
def after_iteration(self, info):
if info.iteration % 100 == 0:
print(f"Iteration {info.iteration}: "
f"Train={info.metrics['learn']['AUC']:.4f}, "
f"Test={info.metrics['validation']['AUC']:.4f}")
current_score = info.metrics['validation']['AUC']
if current_score > self.best_score:
self.best_score = current_score
self.best_iteration = info.iteration
return True
# استفاده از callback
callback = CustomCallback()
model = CatBoostClassifier(iterations=2000, verbose=False)
model.fit(
X_train, y_train,
eval_set=(X_test, y_test),
callbacks=[callback]
)
3. ذخیرهسازی و نسخهبندی مدل
import joblib
from datetime import datetime
# ذخیره مدل با اطلاعات متادیتا
model_metadata = {
'model': model,
'feature_names': list(X_train.columns),
'categorical_features': categorical_features,
'training_date': datetime.now().strftime('%Y-%m-%d'),
'performance': {
'train_accuracy': accuracy_score(y_train, model.predict(X_train)),
'test_accuracy': accuracy_score(y_test, model.predict(X_test))
}
}
# ذخیره
joblib.dump(model_metadata, f'catboost_model_{datetime.now().strftime("%Y%m%d")}.pkl')
# بارگذاری
loaded_metadata = joblib.load('catboost_model_20250101.pkl')
loaded_model = loaded_metadata['model']
4. اشکالزدایی و عیبیابی
# بررسی وضعیت آموزش
print("تعداد تکرارهای انجام شده:", model.tree_count_)
print("بهترین تکرار:", model.get_best_iteration())
print("امتیاز بهترین تکرار:", model.get_best_score())
# بررسی اهمیت ویژگیها
importance_df = model.get_feature_importance(
data=Pool(X_test, y_test, cat_features=categorical_features),
type='FeatureImportance',
prettified=True
)
print("\nاهمیت ویژگیها:")
print(importance_df)
# بررسی ویژگیهایی که استفاده نشدهاند
zero_importance = importance_df[importance_df['Importances'] == 0]
if not zero_importance.empty:
print("\nویژگیهای بدون اهمیت:")
print(zero_importance['Feature Id'].tolist())
مدیریت حافظه و عملکرد
1. بهینهسازی مصرف حافظه
# استفاده از snapshot برای کاهش مصرف حافظه
model = CatBoostClassifier(
iterations=2000,
snapshot_file='catboost_snapshot.cbsnapshot',
snapshot_interval=100, # ذخیره هر 100 تکرار
verbose=False
)
# آموزش با امکان از سرگیری
try:
model.fit(X_train, y_train, cat_features=categorical_features)
except KeyboardInterrupt:
print("آموزش متوقف شد، میتوان از snapshot استفاده کرد")
2. آموزش موازی
# استفاده از چند هسته پردازنده
model = CatBoostClassifier(
iterations=1000,
thread_count=-1, # استفاده از تمام هستهها
task_type='CPU', # یا 'GPU' برای استفاده از GPU
verbose=False
)
# آموزش بر روی GPU (اگر موجود باشد)
model_gpu = CatBoostClassifier(
iterations=2000,
task_type='GPU',
devices='0:1', # استفاده از GPU 0 و 1
verbose=False
)
3. پردازش دستهای (Batch Processing)
# پیشبینی دستهای برای دادههای بزرگ
def batch_predict(model, X, batch_size=10000):
n_samples = len(X)
predictions = []
for i in range(0, n_samples, batch_size):
batch = X.iloc[i:i+batch_size]
batch_pred = model.predict_proba(batch)[:, 1]
predictions.extend(batch_pred)
return np.array(predictions)
# استفاده
large_predictions = batch_predict(model, X_large_test)
نتیجهگیری
الگوریتم CatBoost با ارائه راهحلهای نوآورانه برای چالشهای اساسی یادگیری ماشین، توانسته است جایگاه ویژهای در میان الگوریتمهای یادگیری ماشین به دست آورد. ویژگیهای کلیدی این الگوریتم عبارتند از:
نقاط قوت
- پردازش خودکار ویژگیهای دستهای: نیازی به پیشپردازش پیچیده ندارد
- عملکرد برتر با تنظیمات پیشفرض: برای مبتدیان مناسب است
- مقاوم در برابر بیشبرازش: به لطف تقویت مرتبشده
- سرعت پیشبینی بالا: درختهای متقارن را سریع اجرا میکنند
- مستندات جامع: منابع یادگیری فراوان
نقاط ضعف
- سرعت آموزش متوسط: در مقایسه با LightGBM کندتر است
- مصرف حافظه: برای مجموعه دادههای بسیار بزرگ میتواند چالشبرانگیز باشد
- پیچیدگی الگوریتم: فهم کامل نیازمند دانش عمیق است
توصیههای نهایی
- برای مجموعه دادههای کوچک تا متوسط با ویژگیهای دستهای، CatBoost انتخاب ایدهآل است
- برای مجموعه دادههای بسیار بزرگ، LightGBM ممکن است مناسبتر باشد
- همیشه از اعتبارسنجی متقاطع برای ارزیابی استفاده کنید
- تنظیم فراپارامترها را با روشهای سیستماتیک انجام دهید
- از تفسیرپذیری مدل (SHAP) برای درک بهتر استفاده کنید