خوشهبندی (Clustering) یکی از بنیادیترین وظایف در حوزه یادگیری بدون نظارت (Unsupervised Learning) است که هدف آن گروهبندی دادههای مشابه در دستههای مجزا میباشد. الگوریتم K-Means، به دلیل سادگی و کارایی محاسباتی، به عنوان یکی از محبوبترین روشها در این زمینه شناخته میشود. با این حال، K-Means یک نقطه ضعف اساسی دارد: حساسیت شدید به انتخاب مراکز اولیه خوشهها (Centroids). انتخاب ضعیف مراکز اولیه میتواند الگوریتم را در یک بهینه محلی (Local Optimum) ضعیف گرفتار کرده و نتایج خوشهبندی را به شدت تحت تأثیر قرار دهد. الگوریتم K-Means++ به عنوان یک راهحل هوشمندانه برای این مشکل معرفی شد. این مقاله به بررسی فنی و علمی الگوریتم K-Means++، مکانیسم بهینهسازی آن و نحوه پیادهسازی عملی آن برای دستیابی به خوشهبندی بهینه میپردازد.
۱. مقدمه
در عصر کلاندادهها، توانایی استخراج الگوهای پنهان و ساختارهای ذاتی از مجموعهدادههای بدون برچسب، یک مزیت رقابتی محسوب میشود. خوشهبندی به عنوان ابزاری قدرتمند در این راستا، در کاربردهای متنوعی از جمله تقسیمبندی مشتریان، تشخیص ناهنجاری، فشردهسازی تصویر و بیوانفورماتیک مورد استفاده قرار میگیرد.
الگوریتم K-Means [۱]، که توسط مککویین در سال ۱۹۶۷ معرفی شد، یک الگوریتم تکرارشونده (iterative) است که سعی دارد $n$ مشاهده را به $k$ خوشه تقسیم کند. هدف آن کمینهسازی مجموع مربعات فواصل درونخوشهای (Within-Cluster Sum of Squares – WCSS) یا اینرسی (Inertia) است. با وجود محبوبیت، پاشنه آشیل K-Means، مرحله اول آن، یعنی انتخاب تصادفی $k$ مرکز اولیه است. اگر این مراکز اولیه به صورت نامناسب (مثلاً همگی در یک ناحیه متراکم) انتخاب شوند، K-Means به سرعت به یک نتیجه ضعیف همگرا میشود.
برای رفع این نقیصه، آرتور و واسیلویتسکی (Arthur and Vassilvitskii) در سال ۲۰۰۷ الگوریتم K-Means++ را معرفی کردند [۲]. K-Means++ یک روش مقداردهی اولیه (initialization) هوشمند است که تضمین میکند مراکز اولیه انتخابشده، تا حد امکان از یکدیگر فاصله داشته باشند. این مقاله به تشریح این الگوریتم و پیادهسازی آن میپردازد.
۲. مروری بر چالش K-Means استاندارد
الگوریتم K-Means استاندارد در دو مرحله تکرار میشود تا به همگرایی برسد:
- مرحله تخصیص (Assignment Step): هر نقطه داده به نزدیکترین مرکز خوشه (بر اساس فاصله اقلیدسی) تخصیص مییابد.
- مرحله بهروزرسانی (Update Step): مرکز هر خوشه با محاسبه میانگین تمام نقاط داده تخصیصیافته به آن خوشه، مجدداً محاسبه میشود.
این فرآیند تکرار میشود تا زمانی که مراکز خوشهها دیگر تغییر نکنند (یا تغییرات بسیار جزئی باشند).
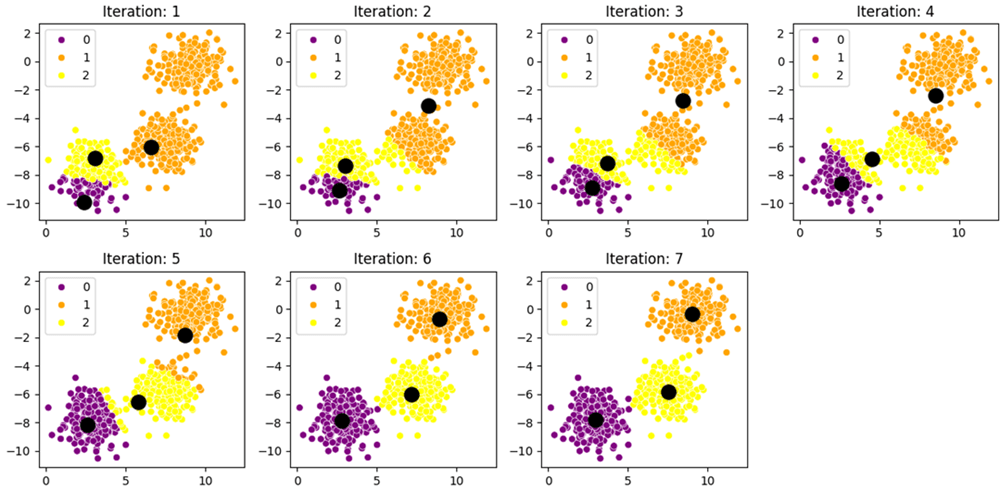
مشکل کجاست؟ فرض کنید در یک مجموعه داده با دو خوشه واضح، هر دو مرکز اولیه تصادفی در داخل یکی از خوشهها قرار گیرند. الگوریتم K-Means به احتمال زیاد قادر به شناسایی خوشه دوم نخواهد بود و هر دو مرکز را در همان خوشه اول بهینه میکند، که منجر به یک نتیجه بسیار ضعیف میشود.
۳. تشریح فنی الگوریتم K-Means++
K-Means++ مشکل مقداردهی اولیه را با یک رویکرد احتمالی هوشمند حل میکند. هدف آن توزیع مراکز اولیه در سراسر فضای داده است. این الگوریتم جایگزین K-Means نمیشود، بلکه مرحله اول (انتخاب مراکز اولیه) آن را بهینه میکند. پس از انتخاب $k$ مرکز توسط K-Means++، الگوریتم K-Means استاندارد (مراحل تخصیص و بهروزرسانی) اجرا میشود.
مراحل الگوریتم مقداردهی اولیه K-Means++ به شرح زیر است:
- انتخاب اولین مرکز: اولین مرکز خوشه ($c_1$) به صورت تصادفی و یکنواخت از میان تمام نقاط داده ($X$) انتخاب میشود.
- انتخاب مراکز بعدی ($c_2$ تا $c_k$):الف. برای هر نقطه داده $x$ در مجموعه داده، فاصله آن تا نزدیکترین مرکز خوشهای که تاکنون انتخاب شده است را محاسبه کنید. این فاصله را $D(x)$ مینامیم.
ب. مرکز خوشه بعدی ($c_i$) از میان نقاط داده $x$ انتخاب میشود، اما این انتخاب تصادفی، وزندار است. احتمال انتخاب هر نقطه $x$ به عنوان مرکز بعدی، متناسب با مربع فاصله آن ($D(x)^2$) است.
$$P(x) = \frac{D(x)^2}{\sum_{x’ \in X} D(x’)^2}$$ج. این فرآیند (الف و ب) تکرار میشود تا زمانی که تمام $k$ مرکز خوشه انتخاب شوند.
چرا این روش کار میکند؟
با استفاده از توزیع احتمال مبتنی بر $D(x)^2$ (که به آن $D^2$-sampling نیز گفته میشود)، نقاطی که از مراکز خوشههای موجود دورتر هستند، شانس بسیار بیشتری برای انتخاب شدن به عنوان مرکز بعدی دارند. این مکانیسم به طور طبیعی مراکز را در فضاهای دادهای مجزا و دور از هم پخش میکند و از تجمع مراکز اولیه در یک ناحیه جلوگیری مینماید.
مزایای K-Means++:
- همگرایی سریعتر: با شروع از نقاط بهتر، K-Means به تکرارهای کمتری برای رسیدن به همگرایی نیاز دارد.
- نتایج با کیفیتتر: K-Means++ به طور قابل توجهی احتمال گرفتار شدن در بهینههای محلی ضعیف را کاهش میدهد و در نتیجه به مقادیر اینرسی (SSE) پایینتر و خوشهبندی دقیقتری دست مییابد.
- تضمین نظری: آرتور و واسیلویتسکی ثابت کردند که K-Means++ یک تقریب $O(\log k)$ از بهینه مطلق K-Means ارائه میدهد که بسیار بهتر از تضمینهای K-Means استاندارد است [۲].
۴. پیادهسازی عملی K-Means++
خوشبختانه، پیادهسازی K-Means++ در اکثر کتابخانههای مدرن یادگیری ماشین، مانند Scikit-learn در پایتون، بسیار ساده است، زیرا این الگوریتم به عنوان روش پیشفرض مقداردهی اولیه در ماژول KMeans گنجانده شده است.
۴.۱. ابزارها و محیط
برای پیادهسازی، ما از اکوسیستم پایتون استفاده میکنیم:
- Python 3.x
- Scikit-learn: برای اجرای الگوریتم.
- Numpy: برای عملیات آرایهای.
- Matplotlib: برای بصریسازی نتایج.
- Jupyter Notebook یا هر IDE پایتون دیگر.
۴.۲. پیادهسازی با Scikit-learn
در کتابخانه sklearn.cluster.KMeans، پارامتری به نام init وجود دارد که نحوه انتخاب مراکز اولیه را مشخص میکند.
init='random': همان K-Means استاندارد با انتخاب کاملاً تصادفی.init='k-means++': از الگوریتم K-Means++ برای مقداردهی اولیه استفاده میکند.
نکته مهم: مقدار پیشفرض این پارامتر در Scikit-learn، 'k-means++' است. بنابراین، اگر شما به سادگی KMeans را فراخوانی کنید، در حال حاضر از مزایای K-Means++ بهره میبرید.
۵. نتیجهگیری
الگوریتم K-Means به عنوان یک ابزار اساسی در جعبهابزار تحلیل داده باقی میماند، اما نقطه ضعف آن در حساسیت به مقداردهی اولیه، استفاده از آن را در حالت استاندارد (random init) پرریسک میکند. الگوریتم K-Means++ یک راهحل هوشمندانه، کارآمد و از نظر تئوری مستحکم برای این مشکل ارائه میدهد.
با استفاده از یک روش نمونهگیری احتمالی وزندار ($D^2$-sampling)، K-Means++ تضمین میکند که مراکز اولیه به خوبی در فضای داده توزیع شدهاند. این امر منجر به همگرایی سریعتر، کاهش احتمال افتادن در بهینههای محلی ضعیف و دستیابی به خوشهبندی بهینهتر (اینرسی کمتر) میشود.
در عمل، به لطف پیادهسازی پیشفرض آن در کتابخانههایی مانند Scikit-learn، استفاده از K-Means++ به استاندارد طلایی برای خوشهبندی K-Means تبدیل شده است. محققان و تحلیلگران داده باید آگاه باشند که هنگام استفاده از KMeans، به طور پیشفرض در حال بهرهبرداری از این روش بهینهسازی هستند.