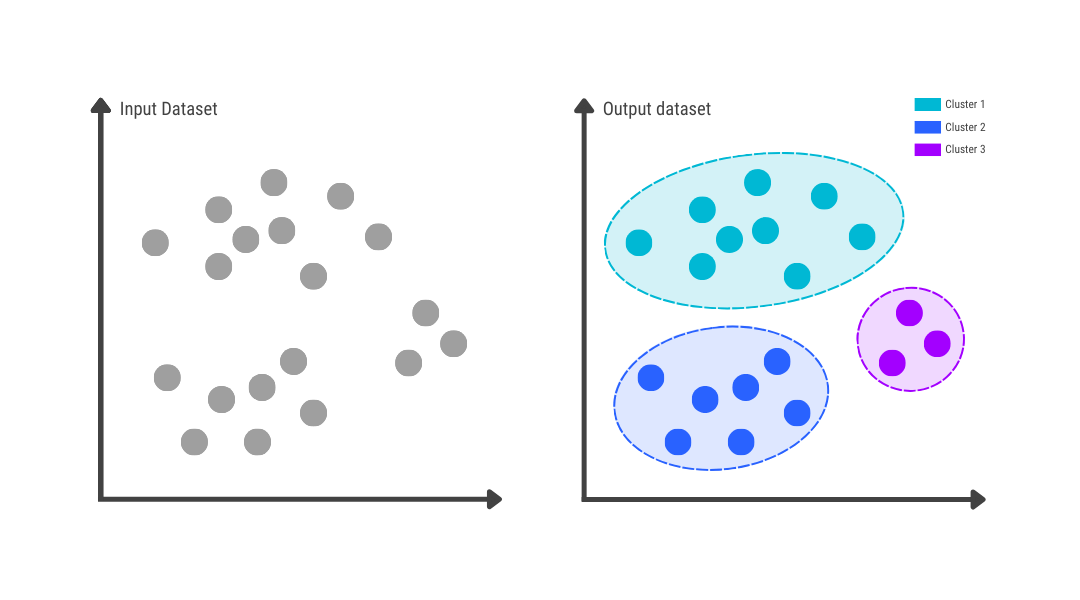
خوشهبندی (Clustering) یک فرآیند بنیادی در حوزههای دادهکاوی و یادگیری ماشین به شمار میرود. این تکنیک به گروهبندی مجموعهای از اشیاء یا نقاط داده به گروههای مجزا، که “خوشه” نامیده میشوند، میپردازد. هدف اصلی خوشهبندی، حداکثر کردن شباهت بین اعضای درون یک خوشه و در عین حال حداقل کردن شباهت بین خوشههای مختلف است. این رویکرد به معنای آن است که دادههای درون یک گروه باید تا حد امکان به یکدیگر شبیه باشند، در حالی که از دادههای گروههای دیگر متمایز گردند.
الگوریتمهای خوشهبندی به عنوان یکی از شاخههای کلیدی یادگیری بدون نظارت (Unsupervised Learning)، ابزاری قدرتمند برای دستهبندی دادهها بر اساس شباهتهای ذاتی آنها، بدون نیاز به هیچگونه برچسب یا دانش قبلی، فراهم میکنند. این مقاله علمی-آموزشی به بررسی جامع مفهوم خوشهبندی، معرفی مهمترین الگوریتمهای آن، کاربردها و چالشهای پیش رو میپردازد.
خوشهبندی چیست و چرا اهمیت دارد؟
تصور کنید با مجموعهای بزرگ از اسناد متنی، تصاویر مشتریان یک فروشگاه آنلاین یا دادههای ژنتیکی روبرو هستید و هیچ اطلاعاتی در مورد گروهبندی یا دستهبندی آنها ندارید. هدف شما، سازماندهی این دادهها به گروههایی است که اعضای هر گروه، بیشترین شباهت را به یکدیگر و بیشترین تفاوت را با اعضای گروههای دیگر داشته باشند. این فرآیند، در هستهی خود، همان خوشهبندی (Clustering) است.
خوشهبندی، وظیفه تقسیم یک مجموعه داده به تعدادی گروه یا خوشه (Cluster) را بر عهده دارد. اصل اساسی در این فرآیند، بیشینهسازی شباهت درونخوشهای (Intra-cluster similarity) و کمینهسازی شباهت بینخوشهای (Inter-cluster similarity) است. اهمیت خوشهبندی از آنجا ناشی میشود که به ما امکان میدهد ساختارهای پنهان، الگوهای طبیعی و گروههای ذاتی را در دادهها کشف کنیم؛ کاری که برای بسیاری از کاربردهای عملی از جمله تقسیمبندی بازار، تشخیص ناهنجاری و تحلیل شبکههای اجتماعی حیاتی است.
سفری به دنیای الگوریتمهای خوشهبندی
الگوریتمهای خوشهبندی بر اساس رویکرد و منطق دستهبندی، به خانوادههای مختلفی تقسیم میشوند. در ادامه، به بررسی سه دسته از پرکاربردترین و بنیادیترین این الگوریتمها میپردازیم.
۱. خوشهبندی مبتنی بر مرکز (Centroid-Based Clustering): الگوریتم K-Means
الگوریتم K-Means (K-میانگین)، بیتردید مشهورترین و یکی از سادهترین الگوریتمهای خوشهبندی است. این الگوریتم از نوع خوشهبندی سخت (Hard Clustering) است، به این معنا که هر نمونه داده دقیقاً به یک خوشه تعلق دارد.
نحوه عملکرد الگوریتم K-Means:
- تعیین تعداد خوشهها (K): اولین و مهمترین گام، مشخص کردن تعداد خوشههایی است که میخواهیم دادهها را به آن تقسیم کنیم. این مقدار (K) باید توسط کاربر تعیین شود.
- مقداردهی اولیه مراکز خوشهها (Centroids): الگوریتم به صورت تصادفی K نقطه از فضای داده را به عنوان مراکز اولیه خوشهها انتخاب میکند.
- تخصیص دادهها به نزدیکترین خوشه: در این مرحله، فاصله هر نمونه داده تا هر یک از K مرکز خوشه محاسبه میشود (معمولاً با استفاده از فاصله اقلیدسی). سپس هر نمونه به خوشهای تخصیص مییابد که مرکز آن، نزدیکترین فاصله را با آن نمونه دارد.
- بهروزرسانی مراکز خوشهها: پس از تخصیص تمام دادهها، مرکز هر خوشه مجدداً محاسبه میشود. مرکز جدید هر خوشه، میانگین تمام نمونههای دادهای است که در آن خوشه قرار گرفتهاند.
- تکرار: مراحل ۳ و ۴ آنقدر تکرار میشوند تا زمانی که مراکز خوشهها دیگر تغییر نکنند یا تغییرات آنها بسیار ناچیز باشد. در این نقطه، الگوریتم به همگرایی رسیده است.
چالش اصلی K-Means: انتخاب مقدار بهینه K یک چالش کلیدی است. روشهایی مانند «روش آرنج» (Elbow Method) و «امتیاز سیلوئت» (Silhouette Score) برای کمک به انتخاب بهترین مقدار K استفاده میشوند.
۲. خوشهبندی سلسلهمراتبی (Hierarchical Clustering)
برخلاف K-Means، خوشهبندی سلسلهمراتبی نیازی به تعیین تعداد خوشهها از قبل ندارد. این الگوریتم، یک ساختار درختی از خوشهها به نام دندروگرام (Dendrogram) ایجاد میکند که سلسلهمراتب ادغام یا تقسیم خوشهها را نمایش میدهد. این روش به دو دسته اصلی تقسیم میشود:
- روش تجمعی (Agglomerative): این رویکرد که از پایین به بالا عمل میکند، در ابتدا هر نمونه داده را به عنوان یک خوشه مجزا در نظر میگیرد. سپس، در هر مرحله، دو خوشهای که بیشترین شباهت (کمترین فاصله) را با یکدیگر دارند، با هم ادغام میکند و این فرآیند را تا زمانی که تمام نمونهها در یک خوشه واحد قرار گیرند، ادامه میدهد.
- روش تقسیمی (Divisive): این رویکرد که از بالا به پایین عمل میکند، در ابتدا تمام نمونهها را در یک خوشه بزرگ قرار میدهد. سپس در هر مرحله، بزرگترین خوشه را به دو زیرخوشه تقسیم میکند و این فرآیند را تا زمانی که هر نمونه در یک خوشه مجزا قرار گیرد، ادامه میدهد.
یکی از مفاهیم کلیدی در این روش، معیار اتصال (Linkage Criterion) است که نحوه محاسبه فاصله بین دو خوشه را تعیین میکند. معیارهای رایج عبارتند از:
- Single Linkage: فاصله بین نزدیکترین اعضای دو خوشه.
- Complete Linkage: فاصله بین دورترین اعضای دو خوشه.
- Average Linkage: میانگین فاصله بین تمام جفت اعضای دو خوشه.
- Ward’s Method: این معیار سعی در کمینه کردن واریانس کل درون خوشهها دارد.
۳. خوشهبندی مبتنی بر چگالی (Density-Based Clustering): الگوریتم DBSCAN
الگوریتم K-Means در شناسایی خوشههایی با اشکال غیرکروی و اندازههای متفاوت دچار مشکل میشود. الگوریتم DBSCAN (Density-Based Spatial Clustering of Applications with Noise) برای غلبه بر این محدودیت طراحی شده است. این الگوریتم قادر است خوشههایی با هر شکل دلخواه را شناسایی کرده و دادههای پرت (نویز) را نیز تشخیص دهد.
مفاهیم کلیدی در DBSCAN:
- Epsilon (ε): یک پارامتر شعاع است که همسایگی اطراف یک نقطه را تعریف میکند.
- Minimum Points (minPts): حداقل تعداد نقاطی که باید در شعاع ε یک نقطه قرار گیرند تا آن ناحیه به عنوان یک ناحیه چگال شناخته شود.
دستهبندی نقاط در DBSCAN:
- نقطه هسته (Core Point): نقطهای است که حداقل
minPtsهمسایه (شامل خودش) در شعاعεخود داشته باشد. - نقطه مرزی (Border Point): نقطهای است که در همسایگی یک نقطه هسته قرار دارد اما خودش یک نقطه هسته نیست.
- نقطه نویز (Noise Point): نقطهای که نه هسته است و نه مرزی. این نقاط به هیچ خوشهای تعلق ندارند.
الگوریتم با انتخاب یک نقطه تصادفی شروع به کار کرده و اگر آن نقطه، یک نقطه هسته باشد، یک خوشه جدید را با تمام نقاط قابل دسترس از آن (نقاط هسته و مرزی) تشکیل میدهد. این فرآیند برای تمام نقاط مجموعه داده تکرار میشود. مزیت بزرگ DBSCAN این است که نیازی به تعیین تعداد خوشهها ندارد و به طور مؤثری نویز را شناسایی میکند.
مقایسه الگوریتمها: کدام یک را انتخاب کنیم؟
| ویژگی | K-Means | خوشهبندی سلسلهمراتبی | DBSCAN |
| تعداد خوشهها | باید از قبل مشخص شود (K) | نیازی به تعیین اولیه ندارد | نیازی به تعیین اولیه ندارد |
| شکل خوشهها | فرض کروی بودن خوشهها | میتواند اشکال پیچیده را مدیریت کند | هرگونه شکل دلخواه را شناسایی میکند |
| دادههای پرت (نویز) | به نویز حساس است و آن را در خوشهها قرار میدهد | به نویز حساس است | قادر به شناسایی و جداسازی نویز است |
| مقیاسپذیری | بسیار کارآمد و سریع برای دادههای بزرگ | از نظر محاسباتی سنگین است () | کارآمدتر از سلسلهمراتبی () |
| پارامترها | تعداد خوشهها (K) | معیار اتصال و ارتفاع برش دندروگرام | شعاع (eps) و حداقل نقاط (minPts) |
کاربردهای عملی الگوریتمهای خوشهبندی
خوشهبندی در زمینههای بسیار متنوعی کاربرد دارد:
- بازاریابی و کسبوکار: برای تقسیمبندی مشتریان (Customer Segmentation) بر اساس رفتار خرید، اطلاعات دموگرافیک یا تعاملات آنها با وبسایت، به منظور ارائه پیشنهادهای شخصیسازی شده.
- پردازش تصویر: برای بخشبندی تصاویر (Image Segmentation) و جداسازی اشیاء مختلف در یک تصویر، مانند تشخیص سلولهای سرطانی در تصاویر پزشکی.
- تحلیل اسناد و متون: برای گروهبندی اسناد خبری مشابه، دستهبندی ایمیلها یا تحلیل نظرات کاربران.
- زیستشناسی و ژنتیک: برای دستهبندی ژنها با الگوهای بیان مشابه یا طبقهبندی گونههای مختلف بر اساس ویژگیهایشان.
- تشخیص ناهنجاری و تقلب (Anomaly/Fraud Detection): شناسایی تراکنشهای بانکی غیرمعمول یا تشخیص نفوذ به یک شبکه با شناسایی الگوهای ترافیکی غیرعادی به عنوان نویز.
- برنامهریزی شهری: تحلیل دادههای مربوط به زلزله برای شناسایی مناطق پرخطر یا گروهبندی مناطق شهری بر اساس کاربری زمین.
خلاصه کاربردی
- خوشهبندی، یک روش یادگیری بدون نظارت است: هدف آن گروهبندی دادههای بدون برچسب بر اساس شباهت است.
- الگوریتم مناسب را انتخاب کنید: برای خوشههای کروی و دادههای بزرگ، K-Means گزینه خوبی است. اگر به دنبال ساختار سلسلهمراتبی هستید یا تعداد خوشهها مشخص نیست، از خوشهبندی سلسلهمراتبی استفاده کنید. برای دادههایی با چگالی متغیر، اشکال نامنظم و وجود نویز، DBSCAN بهترین انتخاب است.
- پیشپردازش دادهها حیاتی است: کیفیت نتایج خوشهبندی به شدت به کیفیت دادههای ورودی بستگی دارد. اقداماتی مانند نرمالسازی ویژگیها و مدیریت دادههای گمشده ضروری است.
- ارزیابی نتایج را فراموش نکنید: از معیارهایی مانند امتیاز سیلوئت (Silhouette Score) برای ارزیابی کیفیت خوشههای ایجاد شده استفاده کنید، به خصوص زمانی که برچسبهای واقعی وجود ندارند.
- انتخاب پارامترها مهم است: عملکرد الگوریتمها به تنظیم صحیح پارامترهایی مانند K در K-Means و
epsوminPtsدر DBSCAN بستگی دارد. برای این کار از روشهای تحلیلی و آزمون و خطا استفاده کنید.