مکانیسم توجه یک تکنیک پیشرفته و تحولآفرین در حوزه یادگیری ماشین و شبکههای عصبی عمیق است که به مدلهای هوش مصنوعی امکان میدهد تا بر مرتبطترین بخشهای داده ورودی تمرکز کنند و بخشهای کماهمیتتر را نادیده بگیرند. این رویکرد از توانایی مغز انسان در تمرکز انتخابی بر جزئیات برجسته و نادیده گرفتن اطلاعات کماهمیتتر الهام گرفته شده است. هدف اصلی این مکانیسم، بهبود دقت پیشبینی، افزایش کارایی مدل و قابلیت پردازش مؤثر مجموعهدادههای گسترده و پیچیده است.
پیش از ظهور مکانیسم توجه، مدلهای سنتی یادگیری عمیق مانند شبکههای عصبی بازگشتی (RNN) و شبکههای حافظه کوتاهمدت بلند (LSTM) در پردازش توالیهای طولانی داده با چالشهای اساسی مواجه بودند. این مدلها به دلیل ماهیت سریالی پردازش خود، تمایل داشتند اطلاعات ابتدایی توالی را در طول زمان فراموش کنند و در شناسایی وابستگیهای دوربرد (long-range dependencies) دچار مشکل میشدند. این محدودیتها، بهویژه در وظایفی مانند ترجمه ماشینی که نیاز به درک کل جمله و روابط بین کلمات دور از هم دارد، به کاهش دقت و انسجام خروجی منجر میشد. در چنین سناریوهایی، پردازش کل داده برای مدل دشوار بود و بردار زمینه با طول ثابت که توسط رمزگشا برای تولید خروجی استفاده میشد، نمیتوانست تمام اطلاعات لازم را بهطور مؤثر فشرده کند.
مفهوم مکانیسم توجه
مکانیسم توجه روشی است که به مدلهای هوش مصنوعی اجازه میدهد بهطور هوشمندانه بخشهای مرتبطتر ورودی را شناسایی و بر روی آنها تمرکز کنند. این فرایند مشابه توجه انتخابی در انسانها است که به ما امکان میدهد در میان انبوهی از اطلاعات حسی، بر روی جنبههای مهمتر متمرکز شویم.
در سیستمهای پردازش زبان طبیعی، برای مثال، یک مدل مجهز به مکانیسم توجه میتواند هنگام ترجمه یک جمله، ارتباط بین کلمات مختلف در زبان مبدأ و مقصد را بهطور دقیقتری تشخیص دهد و وزن بیشتری به کلمات مرتبطتر اختصاص دهد.
تاریخچه و اهمیت مکانیسم توجه
مکانیسم توجه اولین بار در سال 2014 توسط باهدانائو و همکارانش برای بهبود عملکرد مدلهای ترجمه ماشینی معرفی شد. قبل از معرفی این مکانیسم، مدلهای مبتنی بر شبکههای عصبی بازگشتی (RNN) در مواجهه با توالیهای طولانی با محدودیتهای جدی روبرو بودند. این مدلها در حفظ اطلاعات طولانیمدت با مشکل مواجه میشدند.
مکانیسم توجه این مشکل را با فراهم کردن امکان دسترسی مستقیم به تمام حالتهای پنهان گذشته حل کرد. این قابلیت نه تنها به بهبود عملکرد مدلها انجامید، بلکه قابلیت تفسیرپذیری آنها را نیز افزایش داد.
مکانیسم توجه چگونه کار میکند؟ اجزا و فرآیند
مکانیسم توجه معمولاً شامل سه جزء اصلی است که همگی به صورت بردار نمایش داده میشوند: پرسوجو (Query – Q)، کلید (Key – K) و مقدار (Value – V). این سه جزء، هسته اصلی فرآیند توجه را تشکیل میدهند:
- پرسوجو (Query – Q): این بردار، وضعیت فعلی یا تمرکز مدل را نشان میدهد. به عبارت دیگر، پرسوجو بیانگر “آنچه مدل در حال حاضر به دنبال آن است” در ورودی است.
- کلید (Key – K): این بردارها، نماینده عناصر یا ویژگیهای مختلف داده ورودی هستند. کلیدها “آنچه برای مقایسه با پرسوجو در دسترس است” را مشخص میکنند.
- مقدار (Value – V): این بردارها حاوی اطلاعات واقعی مرتبط با هر کلید هستند. مقدارها “اطلاعاتی که در صورت مرتبط بودن کلید، باید استخراج و استفاده شوند” را در خود جای میدهند. در برخی مدلها مانند Bahdanau (2015)، بردارهای K و V اساساً مشابه هستند و حالتهای پنهان رمزگذاری شده را نشان میدهند.
مراحل کار مکانیسم توجه
فرآیند کار مکانیسم توجه به این صورت است که مدل ابتدا با مقایسه بردار پرسوجو (Q) با هر بردار کلید (K)، “امتیاز توجه” (Attention Score) را محاسبه میکند. این امتیاز میزان مرتبط بودن عنصر کلید با پرسوجوی فعلی را نشان میدهد. معمولاً از حاصلضرب نقطهای (Dot Product) برای اندازهگیری شباهت بین پرسوجو و کلیدها استفاده میشود. سپس، این امتیازات از طریق تابع سافتمکس (Softmax) عبور داده میشوند. تابع سافتمکس، امتیازات را به احتمالات (بین 0 تا 1) تبدیل میکند که مجموع آنها 1 است. این احتمالات، “وزنهای توجه” (Attention Weights) را تعیین میکنند که نشاندهنده میزان اهمیت هر مقدار (Value) در خروجی نهایی است.
در نهایت، بردار خروجی یا بردار زمینه با جمع وزنی بردارهای مقدار (V) تولید میشود. وزندهی بر اساس امتیازات توجه محاسبهشده انجام میشود، به طوری که عناصری با امتیاز توجه بالاتر، تأثیر بیشتری بر خروجی نهایی داشته باشند. این بردار زمینه، خلاصهای متمرکز و پویا از اطلاعات مرتبط ورودی را فراهم میکند که سپس در مراحل بعدی مدل (مانند تولید کلمه بعدی در ترجمه) استفاده میشود.
در مدلهای سنتی، یک بردار زمینه ثابت (fixed-length context vector) کل اطلاعات ورودی را فشرده میکرد. این به معنای یک بازنمایی ایستا از کل ورودی بود که با افزایش طول توالی، کارایی خود را از دست میداد. در مقابل، مکانیسم توجه با استفاده از Q، K، V و محاسبه وزنهای پویا، یک بردار زمینه “متغیر” و “متمرکز” برای هر مرحله خروجی ایجاد میکند. این به مدل اجازه میدهد تا در هر لحظه، بر مهمترین اطلاعات تمرکز کند و نیازی به فشردهسازی تمام اطلاعات در یک فضای محدود نداشته باشد. این بدان معناست که مدل میتواند “حافظه” خود را به طور انتخابی مدیریت کند و تنها اطلاعاتی را که در لحظه برای تصمیمگیری مرتبط هستند، بازیابی کند.
انواع مکانیسمهای توجه
مکانیسمهای توجه انواع مختلفی دارند که هر کدام برای کاربردهای خاصی بهینه شدهاند:
1. توجه افزودنی (Additive Attention)
این روش که به توجه باهدانائو هم معروف است، از یک شبکه عصبی کوچک برای محاسبه امتیازات توجه استفاده میکند. فرمول اصلی آن به صورت زیر است:
score(s_t, h_i) = v_a^T tanh(W_a[s_t; h_i])
که در آن v_a و W_a پارامترهای قابل یادگیری هستند.
2. توجه نقطهای (Dot-Product Attention)
این روش سادهتر و کارآمدتر است و از ضرب نقطهای برای محاسبه امتیازات استفاده میکند:
score(s_t, h_i) = s_t^T × h_i
3. توجه عمومی (General Attention)
در این روش، از یک ماتریس وزن قابل یادگیری برای محاسبه امتیازات استفاده میشود:
score(s_t, h_i) = s_t^T × W × h_i
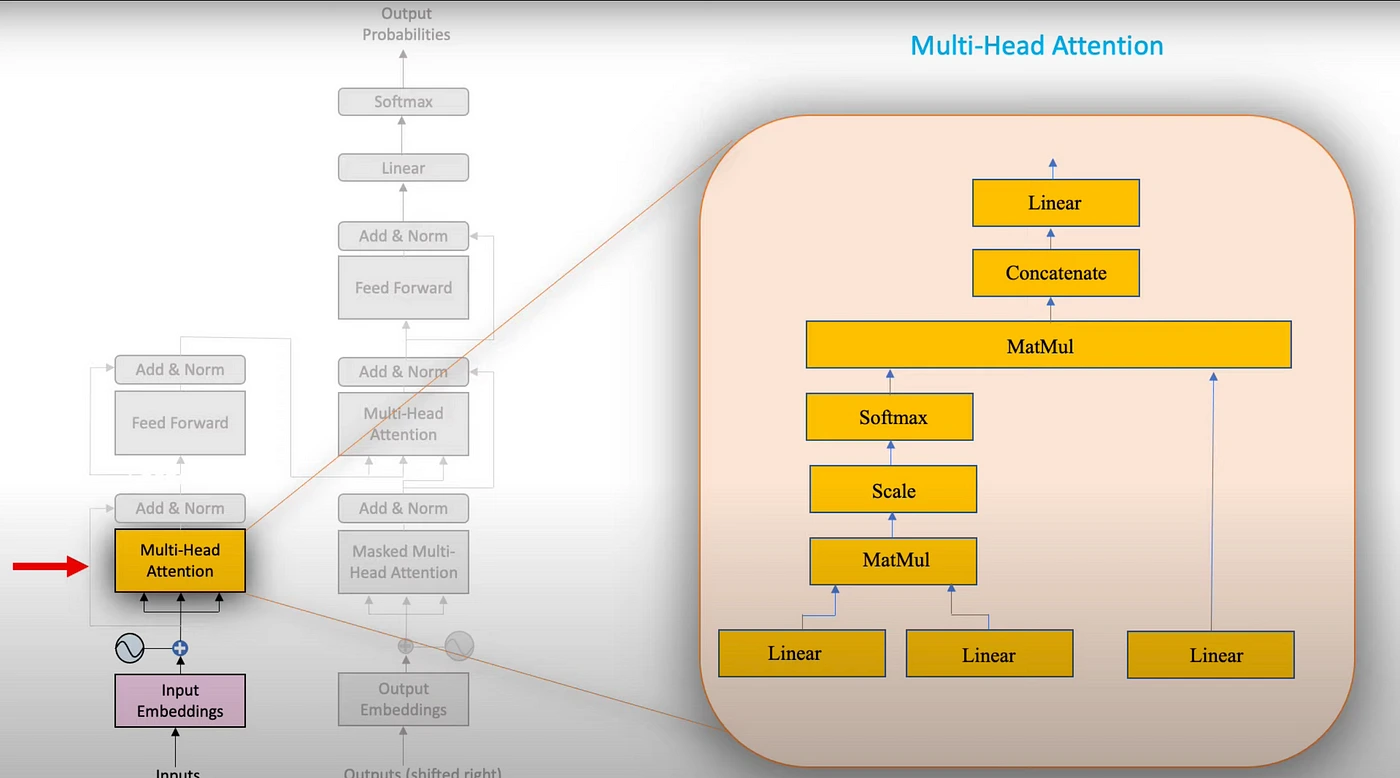
4. توجه چندسره (Multi-Head Attention)
توجه چندسره که در معماری ترانسفورمر استفاده میشود، چندین مکانیسم توجه را بهطور موازی اجرا میکند تا اطلاعات مختلف از فضاهای متفاوت استخراج شود.
ترانسفورمرها و خودتوجهی (Self-Attention)
مکانیسم خودتوجهی (Self-Attention) که در معماری ترانسفورمر استفاده میشود، یکی از مهمترین پیشرفتها در حوزه پردازش زبان طبیعی است. در این مکانیسم، مدل روابط بین تمام عناصر یک توالی را در نظر میگیرد.
مراحل اصلی خودتوجهی شامل:
- ایجاد سه بردار Query، Key و Value برای هر کلمه
- محاسبه امتیازات توجه با ضرب نقطهای Query و Key
- مقیاسگذاری امتیازات و اعمال تابع سافتمکس
- ضرب وزنها در بردارهای Value و جمع کردن نتایج
معماری ترانسفورمر با استفاده از این مکانیسم توانست بسیاری از محدودیتهای مدلهای توالی-به-توالی مبتنی بر RNN و CNN را برطرف کند.
کاربردهای مکانیسم توجه
مکانیسم توجه در حوزههای متنوعی از هوش مصنوعی کاربرد دارد:
1. پردازش زبان طبیعی (NLP)
ترجمه ماشینی: مدلهایی مانند ترانسفورمر و BERT از مکانیسم توجه برای بهبود کیفیت ترجمه استفاده میکنند.
خلاصهسازی متن: تشخیص و تمرکز بر بخشهای مهم متن برای تولید خلاصههای باکیفیت
پاسخگویی به سؤالات: یافتن بخشهای مرتبط با سؤال در متنهای طولانی
2. بینایی ماشین (Computer Vision)
تشخیص اشیاء: تمرکز بر بخشهای مهم تصویر برای تشخیص دقیقتر اشیاء
زیرنویسگذاری تصاویر: ایجاد ارتباط بین بخشهای مختلف تصویر و کلمات مرتبط
تحلیل ویدیو: توجه به فریمها و بخشهای مهم در توالی ویدیویی
3. پردازش صوت و گفتار
تشخیص گفتار: تمرکز بر بخشهای مهم سیگنال صوتی
تبدیل متن به گفتار: بهبود طبیعی بودن صدای تولیدشده
4. سیستمهای توصیهگر
تحلیل رفتار کاربر: تمرکز بر ویژگیهای مهمتر در ترجیحات کاربر
توصیه محتوا: ارتباط بین ویژگیهای مختلف محصولات و ترجیحات کاربر
مزایای استفاده از مکانیسم توجه
مکانیسم توجه مزایای متعددی برای مدلهای یادگیری عمیق به ارمغان میآورد:
- بهبود عملکرد در توالیهای طولانی: برخلاف RNNها، مکانیسم توجه محدودیتی در طول توالی ندارد.
- پردازش موازی: امکان محاسبات همزمان برخلاف ساختارهای توالی مانند RNN
- قابلیت تفسیر: امکان مشاهده و تحلیل بخشهایی که مدل به آنها توجه کرده است
- مقیاسپذیری: امکان استفاده در مدلهای بزرگ و پیچیده
- انعطافپذیری: قابلیت ترکیب با سایر معماریها و تکنیکها
چالشها و محدودیتها
علیرغم مزایای قابل توجه، مکانیسم توجه با چالشهایی نیز روبرو است:
- پیچیدگی محاسباتی: توجه با مربع طول توالی رشد میکند (O(n²))
- نیاز به حافظه زیاد: ذخیرهسازی ماتریسهای بزرگ توجه برای توالیهای طولانی
- چالشهای آموزش: نیاز به دادههای زیاد و منابع محاسباتی قوی
پیشرفتهای اخیر و روند آینده
پژوهشگران برای غلبه بر محدودیتهای مکانیسم توجه، روشهای جدیدی را توسعه دادهاند:
- توجه خطی (Linear Attention): کاهش پیچیدگی محاسباتی از O(n²) به O(n)
- توجه کارآمد از نظر حافظه (Memory-Efficient Attention): بهینهسازی مصرف حافظه
- روشهای توجه محلی (Local Attention): تمرکز بر همسایگی محدود برای کاهش محاسبات
- مکانیسمهای توجه اسپارس (Sparse Attention): کاهش تعداد ارتباطات محاسبهشده
با پیشرفت مداوم در این حوزه، انتظار میرود مکانیسمهای توجه کارآمدتر و قدرتمندتری در آینده ظهور کنند که میتوانند مدلهای بزرگتر و پیچیدهتری را پشتیبانی کنند.
نتیجهگیری
مکانیسم توجه انقلابی در حوزه هوش مصنوعی ایجاد کرده است و بهعنوان یکی از اصلیترین اجزای مدلهای پیشرفته امروزی شناخته میشود. از ترجمه ماشینی گرفته تا بینایی ماشین و پردازش گفتار، این تکنیک قدرتمند عملکرد مدلها را بهطور چشمگیری بهبود بخشیده است.
با تداوم پژوهش و توسعه در این حوزه، مکانیسم توجه همچنان نقش مهمی در پیشرفت هوش مصنوعی و یادگیری ماشین ایفا خواهد کرد. درک عمیقتر و پیادهسازی مؤثرتر این مکانیسم میتواند دستاوردهای شگفتانگیزی را در آینده به همراه داشته باشد.