بخشبندی تصاویر پزشکی (Medical Image Segmentation) یکی از حیاتیترین کاربردهای هوش مصنوعی در تشخیص بیماریها است. از تشخیص تومورهای مغزی در تصاویر MRI گرفته تا شناسایی نودولهای ریوی در CT اسکن، دقت در تفکیک بافتها مرز بین مرگ و زندگی را تعیین میکند. در این میان، معماری U-Net که در سال ۲۰۱۵ معرفی شد، به عنوان استاندارد طلایی در این حوزه شناخته میشود. این مقاله به بررسی عمیق ساختار، ریاضیات و پیادهسازی فنی U-Net میپردازد و راهکارهایی برای غلبه بر چالشهای رایج مانند کمبود داده و عدم تعادل کلاسها ارائه میدهد.
۱. مقدمه: چرا U-Net انقلاب کرد؟
تا پیش از معرفی معماری U-Net توسط اولاف رونبرگر (Olaf Ronneberger) و همکارانش، شبکههای عصبی کانولوشنی (CNN) عمدتاً برای طبقهبندی تصاویر (Classification) استفاده میشدند (مثلاً تصویر حاوی گربه است یا خیر). اما در پزشکی، دانستن اینکه “یک تومور در تصویر وجود دارد” کافی نیست؛ پزشکان نیاز دارند دقیقاً بدانند “تومور کجاست و مرزهای آن با بافت سالم چیست”.
مشکل معماریهای سنتی این بود که با استفاده از لایههای ادغام (Pooling)، ابعاد تصویر کاهش مییافت و اطلاعات مکانی دقیق (Spatial Information) از بین میرفت. U-Net با ارائه یک معماری متقارن U شکل و معرفی اتصالات پرشی (Skip Connections)، این مشکل را حل کرد. این شبکه قادر است با تعداد کمی تصویر آموزشی، به دقت بسیار بالایی دست یابد که برای دادههای پزشکی کمیاب، یک ویژگی حیاتی است.
۲. تحلیل عمیق معماری U-Net
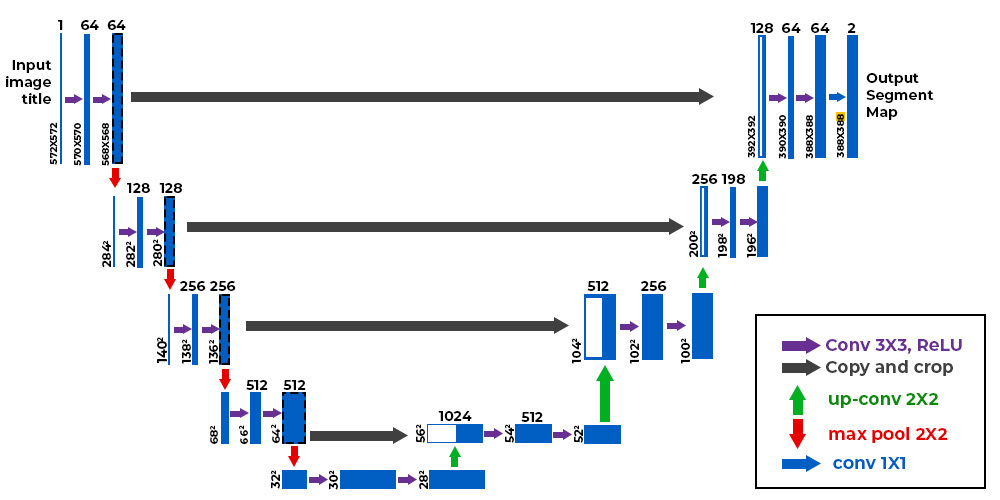
معماری U-Net از دو بخش اصلی تشکیل شده است که شکل حرف ‘U’ را میسازند: مسیر انقباضی (Contracting Path) و مسیر انبساطی (Expanding Path).
۲.۱. مسیر انقباضی (Encoder)
این بخش سمت چپ شبکه است و شبیه به یک CNN کلاسیک عمل میکند. هدف آن استخراج ویژگیهای تصویر (Feature Extraction) و درک “چه چیزی” در تصویر است.
ساختار: شامل بلوکهای تکرار شونده از دو لایه کانولوشن $3 \times 3$ (بدون لایهگذاری یا unpadded) است که هر کدام با یک تابع فعالساز ReLU دنبال میشوند.
کاهش ابعاد: پس از هر بلوک، یک لایه Max Pooling با ابعاد $2 \times 2$ و گام (Stride) ۲ قرار دارد که ابعاد تصویر را نصف میکند.
افزایش کانالها: در هر مرحله پایینرونده، تعداد کانالهای ویژگی (Feature Channels) دو برابر میشود (مثلاً از 64 به 128، سپس 256 و…). این کار به شبکه اجازه میدهد ویژگیهای پیچیدهتر و انتزاعیتری را یاد بگیرد.
۲.۲. گلوگاه (Bottleneck)
این بخش پایینترین نقطه ‘U’ است و رابط بین انکودر و دیکودر میباشد. در اینجا تصویر به فشردهترین حالت خود رسیده و حاوی غنیترین اطلاعات معنایی (Semantic Information) است، اما اطلاعات مکانی دقیق آن بسیار کم است.
۲.۳. مسیر انبساطی (Decoder)
این بخش سمت راست شبکه است و وظیفه آن بازیابی ابعاد تصویر و تعیین “کجایی” اشیاء است.
Upsampling: در هر مرحله، از یک “کانولوشن ترانهاده” (Transposed Convolution) یا Up-convolution با ابعاد $2 \times 2$ استفاده میشود که ابعاد ویژگیها را دو برابر میکند.
نکته کلیدی (Concatenation): پس از هر بار بزرگنمایی، نقشه ویژگی حاصل با نقشه ویژگی متناظر از مسیر انقباضی (که برش داده شده تا هماندازه شوند) الحاق (Concatenate) میشود. این همان جادوی U-Net است.
۲.۴. نقش حیاتی اتصالات پرشی (Skip Connections)
چرا اتصالات پرشی مهم هستند؟ وقتی تصویر در انکودر کوچک میشود، اطلاعات دقیق لبهها و بافتها (High-frequency information) از دست میرود. در دیکودر، شبکه تلاش میکند تصویر را بازسازی کند اما بدون دسترسی به اطلاعات اولیه، لبهها تار میشوند.
اتصالات پرشی، اطلاعات مکانی دقیق را مستقیماً از مراحل اولیه انکودر به دیکودر منتقل میکنند. این کار باعث میشود شبکه همزمان “محتوای معنایی” (از لایههای عمیق) و “جزئیات دقیق مکانی” (از طریق اتصالات پرشی) را در اختیار داشته باشد.
۳. راهنمای فنی پیادهسازی (Implementation Steps)
برای پیادهسازی این معماری معمولاً از فریمورکهای Keras/TensorFlow یا PyTorch استفاده میشود. در اینجا منطق پیادهسازی را گامبهگام بررسی میکنیم.
۳.۱. پیشپردازش دادهها (Data Preprocessing)
تصاویر پزشکی معمولاً فرمتهای خاصی دارند (مثل DICOM یا NIfTI).
نرمالسازی: پیکسلهای تصاویر پزشکی (مثلاً CT) دارای بازه شدت (Hounsfield Unit) متفاوتی هستند. نرمالسازی این مقادیر به بازه $[0, 1]$ برای همگرایی سریعتر شبکه الزامی است.
تغییر اندازه (Resizing): اگرچه U-Net کاملاً کانولوشنی است و میتواند ورودی با ابعاد مختلف بپذیرد، اما برای آموزش دستهای (Batch Training) معمولاً تصاویر به ابعاد ثابت مثل $128 \times 128$ یا $256 \times 256$ تغییر سایز داده میشوند.
۳.۲. ساختار کد (Pseudo-code Logic)
منطق ساخت مدل به صورت لایهبهلایه به شرح زیر است:
ورودی: تانسوری با ابعاد $(H, W, C)$ (برای تصاویر پزشکی سیاه و سفید $C=1$).
تابع Encoder Block: ورودی را میگیرد، دو بار کانولوشن و ReLU اعمال میکند و دو خروجی میدهد: یکی برای MaxPool (رفتن به لایه بعد) و دیگری برای Skip Connection.
تابع Decoder Block: ورودی پایینی و ورودی Skip را میگیرد. ورودی پایینی را Upsample میکند، با ورودی Skip الحاق میکند و سپس کانولوشن اعمال میکند.
لایه خروجی: یک کانولوشن $1 \times 1$ که تعداد کانالها را به تعداد کلاسها (مثلاً ۱ برای بافت هدف) تبدیل میکند. تابع فعالساز در اینجا برای بخشبندی دو دویی Sigmoid و برای چند کلاسه Softmax است.
۴. توابع هزینه و معیارها (Loss Functions & Metrics)
یکی از چالشهای اصلی در تصاویر پزشکی، عدم تعادل کلاسها (Class Imbalance) است. مثلاً در تصویر ریه، بخش نودول سرطانی ممکن است کمتر از ۱٪ کل پیکسلهای تصویر را تشکیل دهد. اگر از تابع هزینه معمولی استفاده کنیم، شبکه ممکن است یاد بگیرد همه پیکسلها را “سالم” پیشبینی کند و دقت ۹۹٪ بگیرد، اما در عمل هیچ ارزشی ندارد.
۴.۱. ضریب دایس (Dice Coefficient)
این معیار شباهت بین دو نمونه (ماسک پیشبینی شده و ماسک واقعی) را میسنجد. فرمول آن به شرح زیر است:
که در آن $A$ ماسک پیشبینی شده و $B$ ماسک واقعی (Ground Truth) است. مقدار آن بین ۰ تا ۱ است.
۴.۲. تابع هزینه دایس (Dice Loss)
برای آموزش شبکه، ما میخواهیم ضریب دایس را بیشینه کنیم، بنابراین تابع هزینه را به صورت زیر تعریف میکنیم:
این تابع هزینه مستقیماً روی همپوشانی تمرکز دارد و کمتر تحت تأثیر تعداد زیاد پیکسلهای پسزمینه قرار میگیرد.
۴.۳. ترکیب BCE و Dice
بسیاری از مقالات مدرن پیشنهاد میکنند از ترکیب Binary Cross Entropy (BCE) و Dice Loss استفاده شود. BCE به همگرایی کلی کمک میکند و Dice Loss دقت روی لبهها و اشیاء کوچک را تضمین میکند.
۵. چالشها و راهکارها: افزایش داده (Data Augmentation)
همانطور که در منابع علمی اشاره شده است (Ronneberger et al., 2015)، موفقیت U-Net تا حد زیادی مدیون استراتژیهای هوشمندانه افزایش داده است. از آنجا که دیتاستهای پزشکی (Labelled Data) بسیار گران و کمیاب هستند، باید دادههای مصنوعی تولید کرد.
تکنیکهای کلیدی Augmentation:
تغییر شکل الاستیک (Elastic Deformation): این مهمترین تکنیک برای بافتهای بیولوژیک است. بافتهای بدن صلب نیستند و ممکن است خمیده شوند. اعمال تغییر شکلهای تصادفی الاستیک، شبکه را نسبت به تغییرات طبیعی بافت مقاوم میکند.
چرخش و جابجایی (Rotation & Shift): برای اینکه شبکه بفهمد مکان و زاویه تومور نباید در تشخیص آن تأثیر بگذارد.
تغییر شدت روشنایی: برای شبیهسازی تفاوت کنتراست در دستگاههای مختلف تصویربرداری.
۶. کاربردهای عملی در پزشکی
معماری U-Net و مشتقات آن (مانند Attention U-Net, U-Net++, 3D U-Net) در حوزههای مختلفی استاندارد شدهاند:
عصبشناسی (Neuroscience): بخشبندی ماده سفید و خاکستری مغز، تشخیص ضایعات MS.
انکولوژی (Oncology): تشخیص دقیق مرزهای تومور برای پرتودرمانی (Radiotherapy planning). هر میلیمتر خطا در اینجا میتواند به بافت سالم آسیب بزند.
چشمپزشکی: بخشبندی عروق خونی در تصاویر شبکیه برای تشخیص رتینوپاتی دیابتی.
۷. نتیجهگیری
پیادهسازی U-Net برای بخشبندی تصاویر پزشکی ترکیبی از هنر و علم است. اگرچه معماری پایه ساده به نظر میرسد، اما تنظیم دقیق هایپرپارامترها، انتخاب صحیح تابع هزینه (مانند Dice Loss) و بهکارگیری هوشمندانه Data Augmentation است که یک مدل معمولی را به یک ابزار کلینیکی قابل اعتماد تبدیل میکند. آینده این حوزه به سمت ترکیب U-Net با مکانیزمهای Attention و مدلهای Transformer میرود تا همزمان جزئیات محلی و ارتباطات سراسری (Global Context) در تصویر درک شوند.