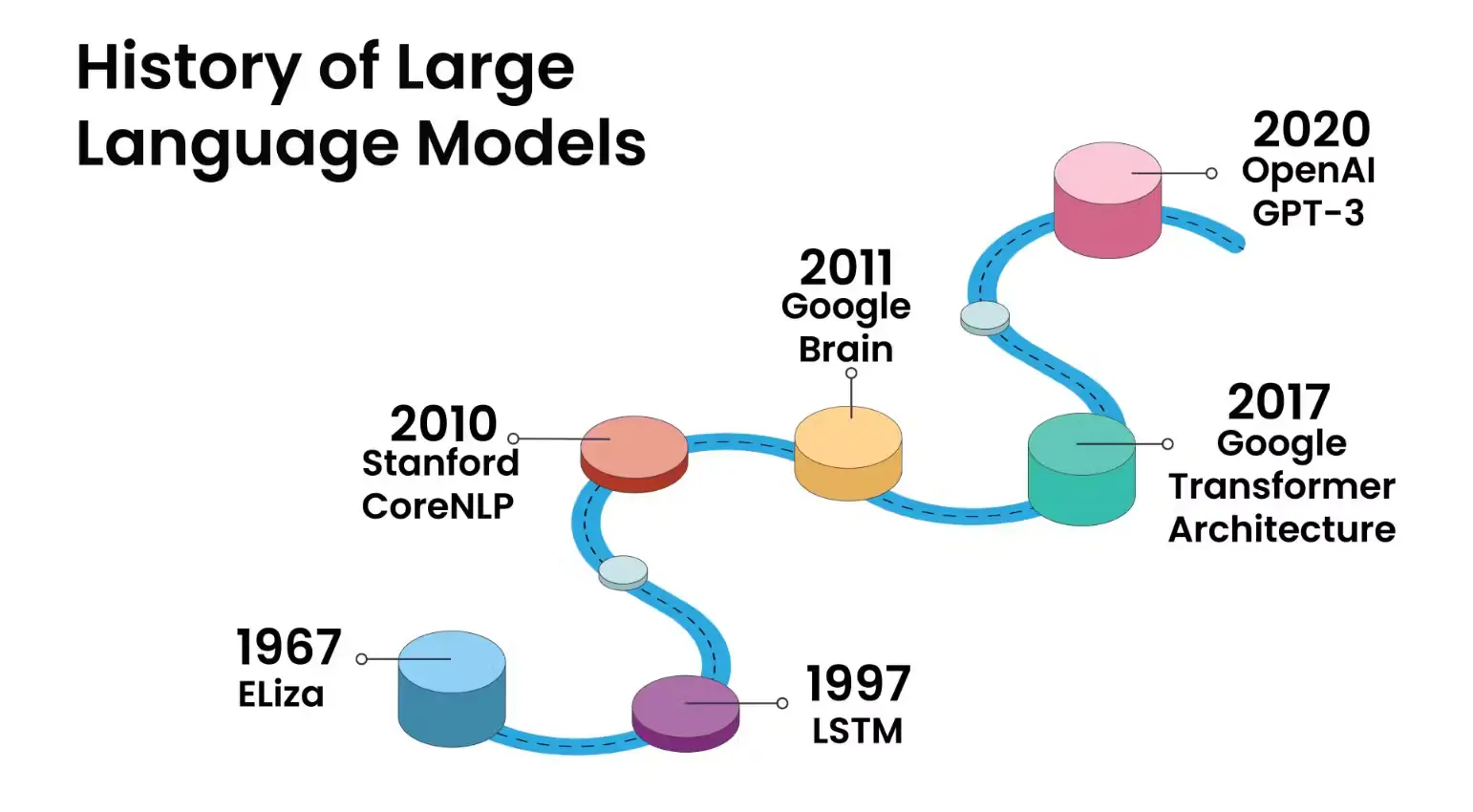
در دهههای اخیر، تکنولوژی اطلاعات و ارتباطات به طور چشمگیری پیشرفت کرده است، و یکی از این پیشرفتها مربوط به حوزه هوش مصنوعی است، به خصوص ظهور مدلهای زبان بزرگ مانند GPT و مدلهای مشابه مبتنی بر شبکههای عصبی مصنوعی است. این مدلها به عنوان مدلهای زبان بزرگ شناخته میشوند و قادر به فهم و تولید زبان طبیعی به سطحی نوین شدهاند. با استفاده از الگوریتمهای ترنسفورمر، این مدلها توانایی پردازش دادههای زبانی را دارند و بدون نیاز به دادههای بزرگ، اطلاعات گستردهای را از منابع مختلف جمعآوری کرده و آنها را به صورت هوشمندانه تحلیل میکنند. علاوه بر این، این مدلها قادر به درک مفاهیم، تولید متن، و حتی پاسخ به سوالات پیچیده نیز هستند.
مدلهای زبانی چه کاربردهایی دارند ؟
مدلهای زبانی بزرگ یا LLM (Large Language Models) مانند GPT-4o دارای کاربردهای گستردهای هستند. این مدلها به دلیل توانایی یادگیری از حجم بزرگی از دادهها و توانایی در درک و تولید زبان طبیعی بشری، در موارد زیر میتوانند استفاده شوند:
پردازش زبان طبیعی (NLP)، که از آن بهره میبریم، در حوزههای گوناگونی از ترجمه ماشینی تا تحلیل متن، استخراج اطلاعات، تولید محتوا خودکار و سایر وظایف مرتبط با پردازش زبان طبیعی کاربرد دارد.
– پاسخ به سوالات: این مدلها میتوانند به سوالات متنی پاسخ دهند و اطلاعات مرتبط را از متون حاوی دادههای گوناگون استخراج کنند.
– تولید محتوا: استفاده از LLM برای تولید محتوا در وبسایتها، بلاگها، خبرنامهها، و حتی در تولید داستانها و شعرها امکانپذیر است.
– پشتیبانی از گفتار: این مدلها در تولید متنهایی برای سیستمهای پشتیبانی یا چتباتها مورد استفاده قرار میگیرند.
– آموزش مدلهای خاص: از این مدلها برای آموزش مدلهای خاص و بهینهسازی عملکرد آنها استفاده میشود.
– تحلیل داده: LLM در تحلیل دادههای متنی کمک میکند، از جمله تشخیص الگوها، استخراج اطلاعات کلیدی و تفسیر محتوای متنی.
– پژوهش علمی: از این مدلها برای انجام تحقیقات در زمینههای مختلف علمی و پژوهشی بهره میبرند.
– توسعه بازیهای ویدئویی: LLM در تولید داستانها، کاراکترها، و دنیای مجازی در بازیهای ویدئویی مورد استفاده قرار میگیرد.
– آموزش زبان: از این مدلها در امور آموزشی و زبانآموزی بهره برده میشود، از جمله تصحیح متون یا ارائه تمرینهای زبانی. برای استفاده مؤثر از این مدلها، دقت کافی به مسائل امنیتی و اخلاقی اساسی است و باید به نحوی استفاده شوند که به جامعه به نحوی مثبت کمک کنند.
برای پاسخگویی به این درخواست، ابتدا جستجویی در گوگل انجام می دهم تا منابع معتبر برای تهیه مقاله را پیدا کنم.
نحوه کارکرد مدل های زبانی بزرگ
پیش بینی کلمه بعدی
اساس کار مدل های زبانی بزرگ، پیش بینی کلمه بعدی است. به عبارتی، مدل یاد می گیرد با توجه به کلمات قبلی، احتمال وقوع کلمات بعدی را محاسبه کند. این فرآیند را “مدل سازی زبان خودرگرسیو” (Autoregressive Language Modeling) می نامیم.
برای مثال، وقتی می نویسیم “هوا امروز بسیار…” مدل احتمالات مختلفی برای کلمه بعدی محاسبه می کند: “گرم” (با احتمال بالا)، “سرد” (با احتمال متوسط)، “درخت” (با احتمال بسیار پایین). سپس کلمه ای با بالاترین احتمال را انتخاب می کند یا از روش های نمونه گیری برای تنوع بیشتر استفاده می کند.
توکن سازی (Tokenization)
مدل های زبانی بزرگ متن را به صورت مستقیم پردازش نمی کنند، بلکه ابتدا آن را به واحدهای کوچکتر به نام “توکن” تقسیم می کنند. توکن ها می توانند کلمات کامل، بخشی از کلمات یا حتی کاراکترهای خاص باشند.
برای مثال، عبارت “هوش مصنوعی” ممکن است به توکن های [“هو”, “ش”, ” مصنو”, “عی”] تبدیل شود. توکن سازی، گام مهمی در پردازش متن است و کیفیت آن تأثیر زیادی بر عملکرد مدل دارد.
فضای برداری و تعبیه (Embedding)
هر توکن به یک بردار عددی چندبعدی (معمولاً بین 768 تا 4096 بعد) تبدیل می شود. این بردارها را “تعبیه” یا “embedding” می نامیم. توکن هایی که از نظر معنایی یا کاربردی به هم نزدیک هستند، در این فضای برداری نیز به هم نزدیک خواهند بود.
مکانیسم توجه (Attention Mechanism)
مکانیسم توجه، قلب تپنده مدل های زبانی بزرگ است. این مکانیسم به مدل امکان می دهد برای هر توکن، میزان ارتباط آن با سایر توکن ها را محاسبه کند. برای مثال، در جمله “کتابی که روی میز است، مال من است”، هنگام پردازش کلمه “است” در انتهای جمله، مدل با استفاده از مکانیسم توجه می تواند تشخیص دهد که “است” به “کتاب” اشاره می کند، نه به “میز”.
قابلیت های مدل های زبانی بزرگ
یادگیری در حین استنتاج (In-context Learning)
یکی از ویژگی های شگفت انگیز مدل های زبانی بزرگ، توانایی آنها در یادگیری از مثال ها در همان متن ورودی است. برای مثال، می توان چند نمونه از ترجمه انگلیسی به فرانسه را به مدل نشان داد و سپس از آن خواست جمله ای جدید را ترجمه کند، بدون اینکه نیاز به آموزش دوباره مدل باشد.
استدلال زنجیره ای (Chain-of-Thought Reasoning)
مدل های زبانی پیشرفته می توانند با استفاده از روش استدلال زنجیره ای، مسائل پیچیده را گام به گام حل کنند. این قابلیت به خصوص در حل مسائل ریاضی، استدلال منطقی و تصمیم گیری های چندمرحله ای کاربرد دارد.
چالش ها و محدودیت ها
توهمات هوش مصنوعی (AI Hallucinations)
مدل های زبانی گاهی اطلاعات نادرست یا غیرواقعی تولید می کنند که به آن “توهم” می گویند. این مشکل از آنجا ناشی می شود که مدل تنها احتمالات آماری را دنبال می کند و درک واقعی از جهان ندارد.
سوگیری و تعصب
مدل ها سوگیری های موجود در داده های آموزشی را یاد می گیرند و ممکن است در پاسخ های خود منعکس کنند. پژوهشگران تلاش می کنند با روش هایی مانند آموزش با بازخورد انسانی (RLHF) این مشکل را کاهش دهند.
محدودیت دانش
دانش مدل های زبانی به زمان آموزش آنها محدود می شود. برای مثال، GPT-4 اطلاعاتی درباره رویدادهای پس از آخرین به روزرسانی داده های آموزشی خود ندارد.
چالش های استفاده از مدلها
چالش دیگر، تولید متن غیر واقعی است. LLM ها میتوانند متنی تولید کنند که بسیار شبیه متن انسان است. این امر میتواند برای ساخت اخبار جعلی یا ایجاد محتوای تبلیغاتی مضر استفاده شود. به عنوان مثال، یک LLM میتواند متنی تولید کند که در آن یک شرکت ادعا میکند که محصولش تأثیرات مثبتی بر سلامتی دارد، در حالی که این ادعاها بیاساس هستند.
چالش دیگر، محدودیتهای تفسیری است. LLM ها میتوانند الگوهایی را در دادهها تشخیص دهند که برای انسانها قابل درک نیستند. این امر میتواند تفسیر خروجی LLM ها را دشوار کند. به عنوان مثال، یک LLM ممکن است متنی تولید کند که از نظر معنایی صحیح باشد، اما انگیزه نویسنده آن مشخص نباشد.
در نهایت، هزینه و دسترسی نیز چالشهایی هستند که باید در نظر گرفته شوند. آموزش LLM ها نیاز به مجموعه دادههای عظیم و قدرت محاسباتی قابل توجهی دارد. این امر میتواند هزینه آموزش و استفاده از LLM ها را افزایش دهد. علاوه بر این، LLM ها معمولاً در اختیار شرکتهای بزرگ فناوری قرار دارند، که میتواند دسترسی به آنها را برای افراد و سازمانهای کوچک محدود کند.
محققان در حال کار بر روی راهحلهایی برای چالشهای استفاده از LLM ها هستند. به عنوان مثال، آنها در حال توسعه روشهایی برای کاهش سوگیری در LLM ها و بهبود تفسیر خروجی آنها هستند. با این حال، همچنان راه زیادی برای طی کردن وجود دارد تا بتوان از LLM ها به طور ایمن و مسئولانه استفاده کرد.
سخن پایانی
مدلهای زبانی بزرگ نه تنها ابزاری بسیار قدرتمند برای تکنولوژی فعلی هستند، بلکه به دلیل قابلیتها و کارآییهایشان، به وسیلهی آنها، به سمت یک آیندهی هوشمندتر و بهرهورتر هدایت میشویم. این مدلها همچنین قابلیتها و کاربردهای جدیدی را برای آینده به ارمغان میآورند که با ادامه تحقیقات و توسعه، به طور چشمگیری افزایش خواهد یافت.
به همراه این افزایش قابلیتها، مدیریت و حل چالشهای مرتبط با این تکنولوژی نیز بسیار حائز اهمیت است. این چالشها ممکن است شامل مواردی مانند حفظ حریم خصوصی، مدیریت منابع محاسباتی، بهبود دقت و قابلیت اطمینان مدلها، و ارتقاء قابلیتهای اخلاقی و اجتماعی آنها باشد. از این رو، همراه با توسعه و استفاده بیشتر از این مدلها، توجه به جوانب مدیریتی و اخلاقی نیز امری ضروری است.