شرکتهای بزرگ هوش مصنوعی قول شفافیت دادند، اما چقدر شفاف هستند؟
در سال 2023، 15 شرکتهای بزرگ هوش مصنوعی قول دادند که در مورد سیستمهای هوش مصنوعی خود شفاف تر باشند. این شرکتها گفتند که اطلاعات بیشتری را در مورد نحوه کار سیستمهای خود به اشتراک خواهند گذاشت و قابلیتها و محدودیتهای آنها را گزارش خواهند کرد.
اما شفافیت در زمینه هوش مصنوعی به چه معناست؟ یک گزارش جدید از مرکز تحقیقات استنفورد در مدلهای بنیادی (CRFM) به این سوال پاسخ میدهد. این گزارش 10 مورد از بزرگترین مدلهای هوش مصنوعی را بر اساس 100 معیار مختلف شفافیت ارزیابی کرد.
نتایج گزارش نشان میدهد که شرکتها در ارائه اطلاعات شفاف در مورد سیستمهای هوش مصنوعی خود عملکرد متفاوتی دارند. برخی از شرکتها، مانند OpenAI و Google، اطلاعات زیادی در مورد سیستمهای خود منتشر میکنند. سایر شرکتها، مانند Microsoft و Amazon، اطلاعات کمتری ارائه میدهند.
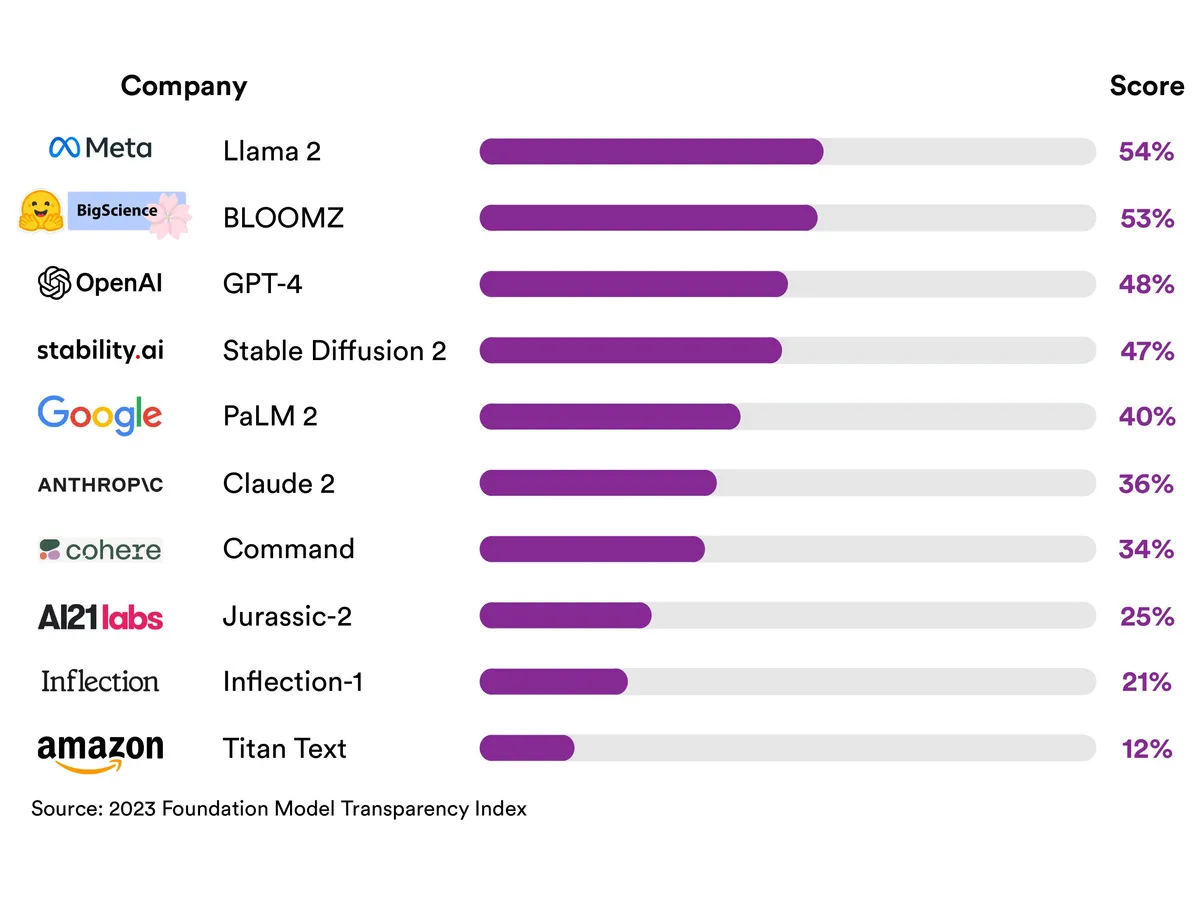
امتیاز بندی شفافیت شرکتهای هوش مصنوعی
لاما 2 متا با 54 امتیاز از 100، بالاترین امتیاز را در میان مدلهای هوش مصنوعی کسب کرد.
شرکتهای بزرگ هوش مصنوعی در ارائه اطلاعات شفاف در مورد مدلهای هوش مصنوعی خود عملکرد ضعیفی داشتند. بالاترین امتیاز کل به لاما 2 متا رسید، که فقط 54 از 100 بود. این نمره در مدرسه مردودی محسوب می شود. محققان گفتند که این نشان دهنده «فقدان اساسی شفافیت در صنعت هوش مصنوعی» است.
ریشی بوماسانی، یکی از رهبران این پروژه، گفت که این شاخص تلاشی برای مبارزه با روند نگرانکننده چند سال گذشته است. او گفت که با افزایش تأثیر مدلهای هوش مصنوعی، شفافیت آنها کاهش یافته است.
شاخص شفافیت مدل بنیادی (CRFM) 100 معیار را برای ارزیابی شفافیت مدلهای هوش مصنوعی در نظر میگیرد. این معیارها را میتوان به سه دسته کلی تقسیم کرد:
- عوامل بالادستی: این عوامل مربوط به نحوه آموزش مدل هستند. به عنوان مثال، این عوامل شامل اطلاعات در مورد دادههای آموزشی، معیارهای ارزیابی و روشهای آموزش میشوند.
- اطلاعات در مورد ویژگی ها و عملکرد مدل: این عوامل مربوط به ویژگیها و عملکرد مدل هستند. به عنوان مثال، این عوامل شامل اطلاعات در مورد اندازه مدل، معماری مدل و قابلیتهای مدل میشوند.
- عوامل پایین دستی: این عوامل مربوط به توزیع و استفاده از مدل هستند. به عنوان مثال، این عوامل شامل اطلاعات در مورد نحوه استفاده از مدل و نحوه مدیریت خطرات احتمالی میشوند.
کوین کلیمن، یکی از نویسندگان گزارش CRFM، گفت که شفافیت در مورد همه جنبههای یک مدل هوش مصنوعی مهم است. او گفت که این شامل شفافیت در مورد منابعی است که برای آموزش مدل استفاده میشوند، ارزیابی قابلیتهای مدل و آنچه پس از انتشار اتفاق میافتد.
برای ارزیابی شفافیت مدلهای هوش مصنوعی، محققان از 100 معیار مختلف استفاده کردند. آنها دادههای در دسترس عموم را برای اطلاعات مربوط به هر معیار جستجو کردند. اگر اطلاعات کافی پیدا میشد، به مدل 1 امتیاز میدادند. اگر اطلاعات کافی پیدا نمیشد، به مدل 0 امتیاز میدادند.
هوش مصنوعی و ابهامات آن
ریشی بوماسانی، محقق هوش مصنوعی در دانشگاه استنفورد، میگوید که شفافیت در مورد نحوه کار مدلهای هوش مصنوعی معمولاً کم است. او میگوید که این کمبود شفافیت در مورد مدلهای هوش مصنوعی حتی بیشتر از سایر زمینههای فناوری است.
شرکتهای هوش مصنوعی اطلاعات کمی در مورد منشأ دادههای آموزشی مدلهای بنیادی خود ارائه میدهند. این موضوع نگرانکننده است زیرا میتواند منجر به استفاده غیرقانونی از مطالب دارای حق چاپ نویسندگان شود.
شاخص شفافیت مدل بنیادی نشان داد که تنها یک مدل، Bloomz از توسعهدهنده Hugging Face، در مورد دادههای آموزشی خود امتیاز بالایی کسب کرد. هیچ یک از مدلهای دیگر امتیاز بالای 40 درصد را کسب نکردند و چندین مدل صفر گرفتند.

علاوه بر علاقه شرکتها به قابلیتهای GPT-4، موضوع نیروی کار نیز مورد توجه قرار گرفت. این موضوع مهم است زیرا مدلهای GPT-4 برای آموزش به کارگران انسانی نیاز دارند. OpenAI از فرآیندی به نام یادگیری تقویتی با بازخورد انسانی استفاده میکند که در آن نیروی انسانی به مدلها میآموزند که کدام پاسخها برای انسان مناسبتر و قابل قبولتر هستند.
با این حال، اکثر توسعهدهندگان اطلاعات کمی در مورد نیروهای انسانی خود ارائه میدهند، مانند اینکه چه کسانی هستند و چه دستمزدهایی دریافت میکنند. این نگرانی وجود دارد که این نیروی کار به کارگران کمدستمزد در مکانهایی مانند کنیا واگذار شود.
بومسانی میگوید: «کار در هوش مصنوعی یک موضوع معمولاً مبهم است، و اینجا بسیار مبهمتر است، حتی فراتر از هنجارهایی که در سایر زمینهها دیدهایم.»
پیشروی مدلهای زبانی منبع باز در شفافیت
سه مدل زبانی باز منبع (Llama 2 از Meta، Bloomz از Hugging Face و Stable Diffusion از Stability AI) در حال حاضر در شفافیت پیشرو هستند. این مدلها وزنهای خود را به طور گستردهای به اشتراک میگذارند، به این معنی که هر کسی میتواند آنها را دانلود و بررسی کند.
این مدلهای باز منبع امتیاز شفافیت بیشتری نسبت به بهترین مدلهای بسته منبع کسب کردهاند. با این حال، برخی نگرانیهایی در مورد مسئولیت پذیری این مدلها دارند. آنها میگویند که این مدلهای قدرتمند میتوانند توسط بازیگران بد برای اهداف مخرب استفاده شوند.
محققان استنفورد متعهد به بهروزرسانی شاخص شفافیت هوش مصنوعی خود هستند. آنها امیدوارند که این شاخص به سیاستگذاران در سراسر جهان کمک کند تا قوانین مربوط به هوش مصنوعی را تدوین کنند.
این شاخص 100 حوزه مختلف را که در مورد شفافیت هوش مصنوعی مهم هستند، شناسایی میکند. محققان استنفورد میگویند که اگر شرکتها در این حوزهها بیشتر شفاف باشند، قانونگذاران میتوانند بهتر تصمیم بگیرند که آیا مداخلهای لازم است یا خیر.
به عنوان مثال، اگر شرکتها اطلاعات کمی در مورد تأثیرات نیروی کار و پاییندستی هوش مصنوعی ارائه دهند، این میتواند به قانونگذاران کمک کند تا در مورد قوانین حمایت از کارگران و محیط زیست تصمیم بگیرند.
حتی اگر یک مدل در شاخص شفافیت هوش مصنوعی استنفورد امتیاز بالایی کسب کند، این لزوماً به این معنی نیست که آن مدل از نظر اخلاقی خوب است. به عنوان مثال، یک مدل می تواند بر روی داده های دارای حق چاپ آموزش دیده باشد یا توسط افرادی که کمتر از حداقل دستمزد پرداخت می کنند، اصلاح شده باشد.
بومسانی می گوید: «ما در حال تلاش برای آشکار کردن حقایق به عنوان اولین گام هستیم.» با این حال، او می افزاید که شفافیت تنها اولین قدم است. «زمانی که شفافیت داشته باشید، کارهای بسیار بیشتری برای انجام دادن وجود دارد.»