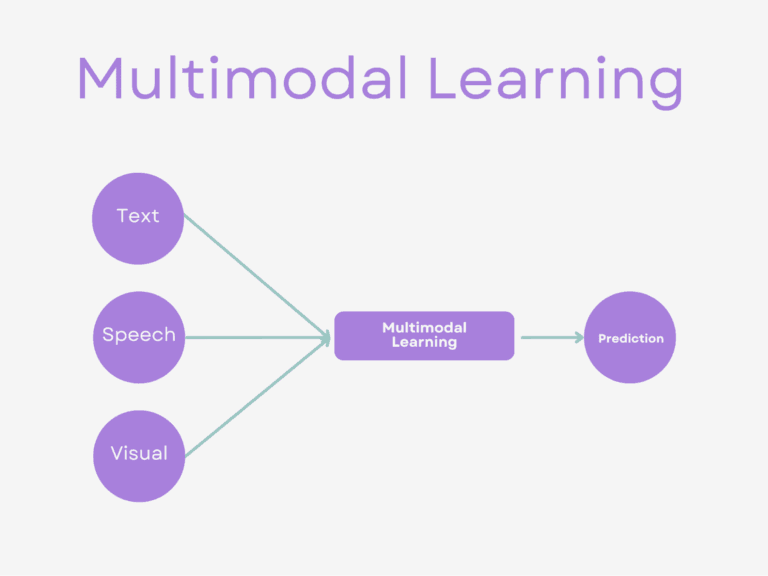
امروزه که دادهها در اشکال گوناگون از متن و تصویر گرفته تا صوت و ویدئو تولید و منتشر میشوند، نیاز به سیستمهای هوشمند با قابلیت درک و پردازش این تنوع اطلاعاتی بیش از پیش احساس میشود. مدلهای چندوجهی (Multimodal Models) در هوش مصنوعی، پاسخی نوآورانه به این نیاز هستند. این مدلها قادرند اطلاعات را از چندین «وجه» یا «حالت» (modality) مختلف به طور همزمان دریافت، پردازش و تفسیر کنند و به درکی جامعتر و شبیهتر به انسان از محیط پیرامون خود دست یابند.
این مقاله به صورت علمی و آموزشی، با زبانی ساده و روان، به معرفی جامع مدلهای چندوجهی، نحوه عملکرد، کاربردها، مزایا و چالشهای پیش روی آنها میپردازد. با ما همراه باشید تا با یکی از هیجانانگیزترین پیشرفتها در حوزه هوش مصنوعی آشنا شوید.
مدل چندوجهی دقیقاً چیست؟ فراتر از درک تکبعدی
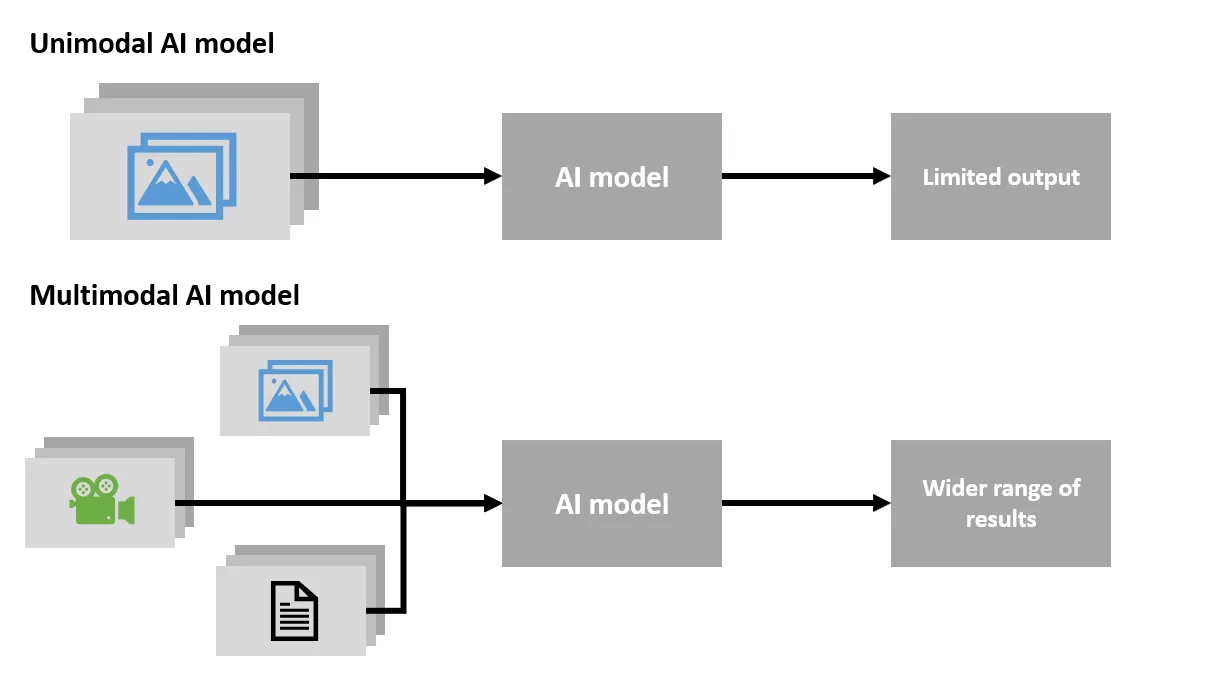
به زبان ساده، یک مدل چندوجهی سیستمی در هوش مصنوعی است که برای پردازش و یادگیری از انواع مختلف دادهها به صورت ترکیبی طراحی شده است.
برای مثال، یک مدل تکوجهی ممکن است بتواند یک تصویر گربه را شناسایی کند یا متنی در مورد گربهها را تحلیل کند. اما یک مدل چندوجهی میتواند تصویری از یک گربه را ببیند، صدای میو کردن آن را بشنود، و متنی توصیفی در مورد تصویر و صدا ارائه دهد، یا حتی به سوالات شما در مورد آن تصویر و صدا پاسخ دهد. این توانایی پردازش و ترکیب اطلاعات از منابع گوناگون، درک مدل را به سطح جدیدی از پیچیدگی و شباهت به درک انسانی ارتقا میدهد.
انواع دادههای ورودی (وجهها) در مدلهای چندوجهی:
- متن: کلمات نوشته شده، مقالات، کدها و …
- تصویر: عکسها، نقاشیها، نمودارها و …
- صوت: گفتار، موسیقی، صداهای محیطی و …
- ویدئو: ترکیبی از تصاویر متحرک و صوت
- دادههای حسگر: اطلاعات حاصل از سنسورهای مختلف مانند دما، فشار، موقعیت مکانی (GPS) و …
- دادههای جدولی: اطلاعات ساختاریافته در جداول
- و حتی دادههای پیچیدهتر مانند سیگنالهای مغزی (EEG) یا دادههای ژنومیک.
مدلهای چندوجهی چگونه کار میکنند؟
نحوه عملکرد مدلهای چندوجهی شامل چندین مرحله کلیدی است :
استخراج ویژگی از هر وجه (Feature Extraction): در ابتدا، برای هر نوع داده ورودی، از شبکهها و الگوریتمهای تخصصی همان وجه برای استخراج ویژگیهای مهم استفاده میشود. به عنوان مثال:
- برای تصاویر: از شبکههای عصبی کانولوشنی (CNNs) برای شناسایی الگوهای بصری مانند لبهها، بافتها و اشیاء استفاده میشود.
- برای متن: از مدلهای پردازش زبان طبیعی (NLP) مانند ترنسفورمرها (Transformers) برای درک معنا و ساختار جملات بهره گرفته میشود.
- برای صوت: از تکنیکهای پردازش سیگنال و شبکههای عصبی بازگشتی (RNNs) یا ترنسفورمرها برای تحلیل ویژگیهای صوتی استفاده میشود.
ایجاد فضای بازنمایی مشترک (Shared Representation Space): یکی از چالشهای اصلی در مدلهای چندوجهی، تبدیل ویژگیهای استخراجشده از وجههای مختلف به یک فضای برداری مشترک و همگن است. در این فضا، اطلاعات مرتبط از وجههای گوناگون به یکدیگر نزدیکتر میشوند. این کار به مدل اجازه میدهد تا ارتباطات و وابستگیهای متقابل بین دادههای مختلف را کشف کند. تکنیکهایی مانند «تعبیههای چندوجهی» (Multimodal Embeddings) در این مرحله نقش کلیدی دارند.
ترکیب اطلاعات (Information Fusion): پس از ایجاد بازنمایی مشترک، اطلاعات از وجههای مختلف با یکدیگر ترکیب میشوند. روشهای مختلفی برای ترکیب اطلاعات وجود دارد، از جمله:
- ترکیب اولیه (Early Fusion): دادهها در مراحل ابتدایی پردازش با هم ترکیب میشوند.
- ترکیب میانی (Intermediate Fusion): بازنماییهای یادگرفته شده از هر وجه در لایههای میانی شبکه با هم ترکیب میشوند.
- ترکیب دیرهنگام (Late Fusion): نتایج حاصل از پردازش مستقل هر وجه در انتها با هم ترکیب میشوند.
- مکانیسم توجه (Attention Mechanism): این روش به مدل اجازه میدهد تا در هنگام ترکیب اطلاعات، به بخشهای مهمتر و مرتبطتر در هر وجه توجه بیشتری کند. این تکنیک در مدلهای پیشرفته امروزی بسیار رایج است.
انجام وظیفه نهایی (Task-Specific Prediction/Generation)
مدلهای زبانی بزرگ چندوجهی (Large Multimodal Models – LMMs)
با ظهور مدلهای زبانی بزرگ (LLMs) مانند خانواده GPT، شاهد جهش بزرگی در تواناییهای هوش مصنوعی بودهایم. گام بعدی و طبیعی در این مسیر، توسعه مدلهای زبانی بزرگ چندوجهی (LMMs) بوده است. این مدلها، قدرت درک و تولید زبان طبیعی LLMها را با توانایی پردازش و درک اطلاعات از وجههای دیگر مانند تصویر و صوت ترکیب میکنند. مدلهایی مانند GPT-4 با قابلیتهای بصری (GPT-4V)، Gemini گوگل و Flamingo از جمله نمونههای برجسته LMMها هستند که تواناییهای شگفتانگیزی در تعاملات چندوجهی از خود نشان دادهاند.
کاربردهای شگفتانگیز مدلهای چندوجهی
- تولید محتوای چندرسانهای: ایجاد خودکار توضیحات متنی برای تصاویر (Image Captioning)، تولید تصویر از روی توضیحات متنی (Text-to-Image Generation)، ساخت ویدئو از روی متن و بالعکس.
- پاسخگویی بصری به پرسش (Visual Question Answering – VQA): پاسخ به سوالات مطرح شده در مورد محتوای یک تصویر یا ویدئو.
- سیستمهای توصیهگر پیشرفته: ارائه پیشنهادهای دقیقتر با در نظر گرفتن تاریخچه متنی جستجوها، تصاویر محصولات مشاهده شده و حتی نظرات صوتی کاربران.
- رباتیک و خودروهای خودران: درک بهتر محیط از طریق ترکیب دادههای دوربین، لیدار، رادار و سنسورهای دیگر برای ناوبری و تعامل ایمنتر.
- حوزه سلامت و پزشکی: تحلیل ترکیبی تصاویر پزشکی (مانند MRI و X-ray) با گزارشهای متنی پزشکان برای تشخیص دقیقتر بیماریها.
- تجربه کاربری و دستیارهای هوشمند: ایجاد دستیارهای مجازی با قابلیت درک و پاسخگویی از طریق گفتار، متن و حتی درک حالات چهره کاربر.
- آموزش و یادگیری: ساخت ابزارهای آموزشی تعاملی که محتوای متنی، تصویری و صوتی را برای درک بهتر مفاهیم ترکیب میکنند.
- تحلیل احساسات چندوجهی: تشخیص احساسات کاربران از طریق تحلیل همزمان متن، لحن صدا و حالات چهره.
مزایای کلیدی مدلهای چندوجهی
استفاده از مدلهای چندوجهی مزایای قابل توجهی نسبت به رویکردهای تکوجهی به همراه دارد:
- درک جامعتر و غنیتر: با ترکیب اطلاعات از منابع مختلف، این مدلها به درک عمیقتر و کاملتری از مفاهیم و موقعیتها دست مییابند.
- افزایش دقت و کارایی: همافزایی بین وجههای مختلف میتواند منجر به بهبود عملکرد و کاهش خطا در وظایف پیچیده شود. اطلاعات از یک وجه میتواند ابهامات موجود در وجه دیگر را برطرف کند.
- انعطافپذیری بیشتر: این مدلها قادر به پردازش ورودیهای متنوع هستند و میتوانند در طیف وسیعتری از کاربردها مورد استفاده قرار گیرند.
- تعامل طبیعیتر و شبیهتر به انسان: توانایی درک و تولید اطلاعات در حالتهای مختلف، تعامل این مدلها با انسان را طبیعیتر و روانتر میکند.
- مقاومت بیشتر در برابر نویز و دادههای ناقص: اگر اطلاعات در یک وجه ناقص یا دارای نویز باشد، اطلاعات از وجههای دیگر میتواند به جبران آن کمک کند.
چالشها و مسیر پیش رو
علیرغم پیشرفتهای چشمگیر، توسعه و پیادهسازی مدلهای چندوجهی با چالشهایی نیز همراه است:
- ناهمگونی دادهها (Data Heterogeneity): دادههای مربوط به وجههای مختلف دارای ساختارها و ویژگیهای متفاوتی هستند که پردازش و یکپارچهسازی آنها را دشوار میکند.
- یافتن بازنمایی مشترک مؤثر: ایجاد یک فضای بازنمایی که بتواند به طور مؤثر اطلاعات را از وجههای مختلف در خود جای دهد و ارتباطات بین آنها را به خوبی مدل کند، یک چالش تحقیقاتی مهم است.
- پیچیدگی معماری و آموزش: طراحی و آموزش مدلهای چندوجهی به دلیل تعداد پارامترهای بیشتر و نیاز به مجموعه دادههای بزرگ و متنوع، پیچیدهتر و پرهزینهتر از مدلهای تکوجهی است.
- همترازی وجهها (Modality Alignment): اطمینان از اینکه بخشهای متناظر در وجههای مختلف (مثلاً یک کلمه در متن و شیء مربوط به آن در تصویر) به درستی با یکدیگر همتراز میشوند، ضروری است.
- ارزیابی عملکرد: تعریف معیارهای مناسب برای ارزیابی عملکرد مدلهای چندوجهی، به خصوص در وظایف تولیدی (generative tasks)، همچنان یک حوزه فعال تحقیقاتی است.
- نیاز به دادههای برچسبخورده چندوجهی: جمعآوری و برچسبگذاری مجموعه دادههای بزرگ که شامل اطلاعات همتراز شده از چندین وجه باشند، زمانبر و پرهزینه است.
با این حال، تحقیقات در زمینه مدلهای چندوجهی با سرعت زیادی در حال پیشرفت است و انتظار میرود در آینده شاهد نوآوریها و بهبودهای بیشتری در این حوزه باشیم. توسعه تکنیکهای کارآمدتر برای یادگیری بازنمایی، روشهای ترکیب اطلاعات پیشرفتهتر، و ایجاد مجموعه دادههای بزرگتر و باکیفیتتر، مسیر را برای کاربردهای گستردهتر و تأثیرگذارتر این مدلها هموار خواهد کرد.
نتیجهگیری
مدلهای چندوجهی نشاندهنده یک گام مهم به سوی ساخت سیستمهای هوش مصنوعی با قابلیتهای شناختی نزدیکتر به انسان هستند. توانایی آنها در پردازش و یکپارچهسازی اطلاعات از منابع گوناگون، پتانسیل ایجاد تحولات عظیمی را در طیف وسیعی از صنایع و جنبههای زندگی ما دارد. با ادامه پژوهشها و رفع چالشهای موجود، میتوان انتظار داشت که مدلهای چندوجهی نقش کلیدیتری در آینده هوش مصنوعی و تعامل ما با فناوری ایفا کنند و دنیایی هوشمندتر و متصلتر را برای ما به ارمغان بیاورند.