استفاده از رابطهای برنامهنویسی کاربردی (API) هوش مصنوعی به یکی از ضروریترین نیازهای کسبوکارها تبدیل شده است. با این حال، هزینههای مرتبط با این فناوریها میتواند به سرعت افزایش یابد و بودجه سازمانها را تحت فشار قرار دهد. این مقاله به بررسی جامع راهکارهای علمی و عملی برای کاهش هزینههای استفاده از API های هوش مصنوعی میپردازد و راهنماییهای مبتنی بر پژوهشهای اخیر و تجربیات صنعتی ارائه میدهد.
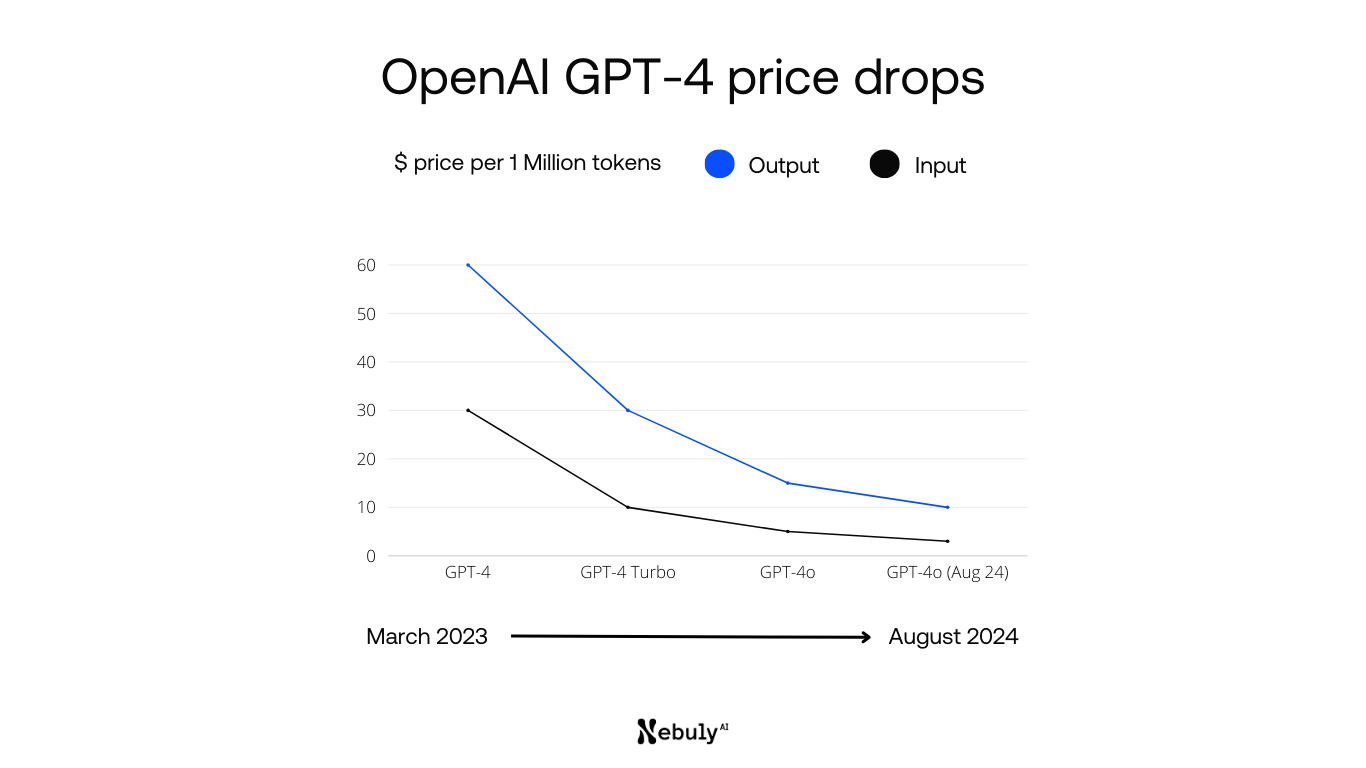
استفاده از API های هوش مصنوعی در سالهای اخیر رشد چشمگیری داشته است. بر اساس گزارشهای اخیر، میزان استفاده از API های GPT-4o در سال ۲۰۲۵ نسبت به سال قبل ۳۰۰ درصد افزایش یافته است. این رشد سریع در حالی است که بسیاری از سازمانها هنوز از روشهای بهینه برای کنترل هزینههای مرتبط آگاه نیستند.
هزینههای API های هوش مصنوعی معمولاً بر اساس تعداد توکنهای پردازششده محاسبه میشود. این مدل قیمتگذاری در عین سادگی، میتواند منجر به هزینههای غیرقابل پیشبینی شود، بهویژه در پروژههای بزرگمقیاس. مطالعات نشان میدهد که سازمانها با بهکارگیری استراتژیهای بهینهسازی مناسب میتوانند تا ۷۰ درصد از هزینههای خود را کاهش دهند.
مروری بر ساختار قیمتگذاری API های هوش مصنوعی
مفهوم توکن و نحوه محاسبه هزینه
توکنها کوچکترین واحد پردازش در مدلهای زبانی هستند. هر کلمه، کاراکتر یا بخشی از متن که توسط API پردازش میشود، بهعنوان توکن محسوب میشود. درک صحیح این مفهوم اولین قدم در بهینهسازی هزینهها محسوب میشود.
برای مثال، مدل GPT-4o با قیمتگذاری زیر ارائه میشود:
- ۲.۵۰ دلار برای هر میلیون توکن ورودی
- ۱۰ دلار برای هر میلیون توکن خروجی
- توکنهای کششده: ۱.۲۵ دلار برای هر میلیون توکن ورودی
تفاوت قیمتگذاری مدلهای مختلف
مدلهای مختلف هوش مصنوعی دارای ساختار قیمتگذاری متفاوتی هستند:
GPT-4o Mini:
- ۰.۱۵ دلار برای هر میلیون توکن ورودی
- ۰.۶۰ دلار برای هر میلیون توکن خروجی
- توکنهای کششده: ۰.۰۷۵ دلار
Azure OpenAI Service:
- مدل استاندارد (پرداخت بر اساس مصرف)
- مدل PTU (واحدهای پردازش اختصاصی) با هزینههای قابل پیشبینی
راهکارهای اساسی کاهش هزینه
۱. بهینهسازی مصرف توکن
کاهش طول پرامپتها
یکی از مؤثرترین روشها برای کاهش هزینه، کوتاه کردن پرامپتها بدون از دست دادن کیفیت خروجی است. تحقیقات نشان میدهد که پرامپتهای طولانی نهتنها هزینه بیشتری دارند، بلکه ممکن است کیفیت پاسخ را نیز کاهش دهند.
راهکارهای عملی:
- حذف کلمات اضافی و تکراری
- استفاده از جملات مستقیم و کوتاه
- اولویتبندی اطلاعات حیاتی در ابتدای پرامپت
استفاده از تکنیکهای فشردهسازی متن
فشردهسازی هوشمندانه محتوا میتواند تا ۳۰ درصد از تعداد توکنها را کاهش دهد:
قبل از بهینهسازی:
"لطفاً این متن طولانی را بررسی کرده و یک خلاصه کامل و جامع از تمام نکات مهم و قابل توجه آن ارائه دهید."
بعد از بهینهسازی:
"خلاصه کامل این متن را ارائه دهید."
۲. پیادهسازی سیستم کش (Caching)
کشکردن یکی از قدرتمندترین ابزارها برای کاهش هزینهها محسوب میشود. این تکنیک امکان ذخیره و استفاده مجدد از پاسخهای قبلی را فراهم میکند.
مزایای کشکردن پرامپت
- کاهش هزینه: تا ۵۰ درصد کاهش هزینه برای توکنهای ورودی
- بهبود سرعت: پردازش سریعتر پاسخها
- کاهش زمان انتظار: پاسخ فوری برای درخواستهای تکراری
انواع استراتژیهای کشکردن
۱. کش محلی (Local Caching): ذخیره پاسخها در سیستم محلی برای استفادههای بعدی
۲. کش توزیعشده (Distributed Caching): استفاده از سیستمهایی مانند Redis برای کشکردن در مقیاس بزرگ
۳. کش هوشمند (Intelligent Caching): تشخیص خودکار پترنهای تکراری و کشکردن بهینه
۳. انتخاب مدل مناسب برای هر وظیفه
استفاده از مدلهای مختلف برای وظایف گوناگون میتواند هزینهها را بهطور قابل توجهی کاهش دهد.
طبقهبندی وظایف بر اساس پیچیدگی
وظایف ساده:
- پردازش متن پایه
- ترجمه ساده
- پاسخهای کوتاه
مدل پیشنهادی: GPT-4o Mini یا مدلهای کوچکتر
وظایف متوسط:
- تحلیل محتوا
- نوشتن خلاقانه
- خلاصهسازی پیچیده
مدل پیشنهادی: GPT-4o استاندارد
وظایف پیچیده:
- تحلیل عمیق داده
- استدلال پیچیده
- وظایف تخصصی
مدل پیشنهادی: GPT-4o یا مدلهای پیشرفتهتر
۴. استفاده از API دستهای (Batch API)
API دستهای یکی از مؤثرترین روشها برای کاهش هزینهها است که امکان ۵۰ درصد کاهش هزینه را فراهم میکند.
مزایای پردازش دستهای
- کاهش هزینه: ۵۰ درصد تخفیف روی توکنهای ورودی و خروجی
- کارایی بالا: پردازش همزمان چندین درخواست
- قابلیت اطمینان: تکمیل تضمینشده در ۲۴ ساعت
موارد استفاده مناسب
- پردازش دادههای بزرگ
- تحلیل گروهی اسناد
- عملیاتهای غیرضروری فوری
- پردازش لاگها و گزارشها
۵. مونیتورینگ و کنترل مصرف
ابزارهای نظارت
داشبورد OpenAI:
- نمایش مصرف روزانه
- تعداد فراخوانیها
- هزینههای تفکیکشده
سیستمهای شخص ثالث:
- Moesif برای تحلیل API
- Holori برای مدیریت مالی
- CloudZero برای بهینهسازی هزینه
تنظیم حدود مصرف
{
"usage_limits": {
"daily_token_limit": 100000,
"monthly_budget": 500,
"alert_threshold": 80
}
}
تکنیکهای پیشرفته بهینهسازی
۱. مدیریت Context Window
Context Window یا پنجره زمینه، مقدار اطلاعاتی است که مدل میتواند در هر درخواست پردازش کند. مدیریت صحیح این پنجره میتواند هزینهها را بهطور چشمگیری کاهش دهد.
استراتژیهای بهینهسازی Context
۱. اولویتبندی اطلاعات: مهمترین اطلاعات در ابتدای پرامپت قرار گیرد
۲. حذف اطلاعات اضافی: اطلاعات غیرضروری برای وظیفه خاص حذف شود
۳. استفاده از خلاصهسازی: متنهای طولانی قبل از ارسال خلاصه شوند
۲. پیادهسازی الگوریتمهای هوشمند توزیع بار
توزیع هوشمند درخواستها بین مدلهای مختلف میتواند تعادل مناسبی بین کیفیت و هزینه ایجاد کند.
مراحل پیادهسازی
تشخیص نوع درخواست:
def classify_request_complexity(prompt):
if len(prompt) < 100 and simple_pattern_match(prompt):
return "simple"
elif len(prompt) < 500:
return "medium"
else:
return "complex"
انتخاب مدل بهینه:
def select_optimal_model(complexity, budget_remaining):
if complexity == "simple":
return "gpt-4o-mini"
elif complexity == "medium" and budget_remaining > threshold:
return "gpt-4o"
else:
return "gpt-4o-mini" # fallback option
۳. بهینهسازی دینامیک پرامپت
این تکنیک شامل تطبیق خودکار پرامپتها با شرایط مختلف است:
ویژگیهای کلیدی
- تطبیق طول: کوتاه کردن خودکار پرامپتهای طولانی
- حذف تکرار: شناسایی و حذف اطلاعات تکراری
- بهینهسازی کلیدواژه: انتخاب مؤثرترین کلیدواژهها
۴. استفاده از مدلهای ترکیبی (Hybrid Models)
ترکیب چندین مدل برای وظایف پیچیده میتواند منجر به بهترین نسبت قیمت به کارایی شود.
معماری پیشنهادی
مرحله ۱: پیشپردازش با مدل کوچک
↓
مرحله ۲: تحلیل اصلی با مدل متوسط
↓
مرحله ۳: بازنگری نهایی با مدل بزرگ (در صورت نیاز)
مطالعه موردی: کاهش ۷۰ درصدی هزینهها
شرکت والمارت: بهینهسازی زنجیره تامین
شرکت والمارت با پیادهسازی راهبردهای هوش مصنوعی موفق به نتایج زیر شد:
- ۱.۵ درصد کاهش هزینه در مذاکرات با تامینکنندگان
- ۲۰ درصد کاهش هزینه واحد از طریق خودکارسازی
- کاهش موجودی و بهبود کارایی
استراتژیهای کلیدی پیادهسازیشده
- استفاده از مدلهای متنوع: از BERT تا GPT-4
- پیادهسازی سیستم کش پیشرفته
- مونیتورینگ مداوم مصرف
- بهینهسازی خودکار پرامپتها
بهترین شیوهها و توصیههای عملی
۱. برنامهریزی و پیشبینی
تحلیل الگوهای مصرف:
- بررسی دورهای آمار مصرف
- شناسایی ساعات اوج مصرف
- پیشبینی رشد آینده
تنظیم بودجه:
{
"monthly_budget": {
"development": 1000,
"testing": 500,
"production": 3000,
"emergency_buffer": 500
}
}
۲. آموزش تیم توسعه
نکات کلیدی آموزش:
- درک صحیح مفهوم توکن
- تکنیکهای نوشتن پرامپت بهینه
- استفاده از ابزارهای مونیتورینگ
- شناخت مدلهای مختلف و کاربردهای آنها
۳. استقرار تدریجی
مراحل پیادهسازی:
فاز ۱: پیادهسازی سیستم مونیتورینگ پایه فاز ۲: اجرای تکنیکهای کشکردن ساده فاز ۳: بهینهسازی انتخاب مدل فاز ۴: پیادهسازی سیستمهای پیشرفته
۴. ارزیابی مداوم و بهبود
شاخصهای کلیدی عملکرد (KPI)
- هزینه به ازای درخواست: محاسبه میانگین هزینه هر فراخوانی API
- نرخ بهرهوری کش: درصد درخواستهایی که از کش پاسخ داده میشوند
- زمان پاسخ متوسط: سرعت پردازش درخواستها
- نرخ خطا: درصد درخواستهای ناموفق
def calculate_cost_efficiency():
total_requests = get_total_requests()
total_cost = get_total_cost()
cache_hit_rate = get_cache_hit_rate()
cost_per_request = total_cost / total_requests
efficiency_score = cache_hit_rate * 100
return {
'cost_per_request': cost_per_request,
'efficiency_score': efficiency_score,
'improvement_potential': calculate_improvement()
}
مزایای استفاده از پلتفرمهای محلی
پلتفرم AvalAI: گزینهای بهینه برای توسعهدهندگان ایرانی
پلتفرم یکپارچه هوش مصنوعی AvalAI با ارائه بیش از ۲۵۰ مدل مختلف هوش مصنوعی، مزایای منحصر به فردی را برای کاهش هزینهها فراهم میکند:
مزایای اقتصادی
۱. حذف هزینههای تبدیل ارز:
- پرداخت مستقیم با ریال ایران
- عدم وابستگی به نوسانات ارز
- کاهش ۱۰-۲۰ درصدی هزینهها نسبت به پلتفرمهای خارجی
۲. قیمتگذاری رقابتی:
- تعرفهها مطابق با ارائه دهندههای اصلی
- پکیجهای تخفیفی برای مصارف بالا
- عدم اعمال مالیاتهای بینالمللی
- ارائه فاکتور رسمی
۳. پشتیبانی کامل فارسی:
- مستندات کامل به زبان فارسی در صفحه مستندات وب سرویس
- پشتیبانی فنی ۲۴/۷ به زبان فارسی
- کاهش زمان توسعه و عیبیابی
تنوع مدلها و کاربردها
با بیش از ۲۵۰ مدل در دسترس، توسعهدهندگان میتوانند:
- مدل مناسب هر وظیفه را انتخاب کنند
- هزینهها را با انتخاب دقیقتر کاهش دهند
- از تکنولوژیهای متنوع در یک پلتفرم استفاده کنند
۱. تعادل بین کیفیت و هزینه
چالش: کاهش بیش از حد هزینهها ممکن است کیفیت خروجی را تحت تأثیر قرار دهد.
راهحل:
- تعریف حد آستانه کیفیت قابل قبول
- آزمایش A/B برای بررسی تأثیر تغییرات
- پیادهسازی سیستم ارزیابی خودکار کیفیت
۲. مدیریت پیکهای مصرف
چالش: نوسانات ناگهانی در مصرف میتواند منجر به افزایش هزینهها شود.
راهحل:
- پیادهسازی سیستم Rate Limiting
- استفاده از Queue برای مدیریت درخواستها
- برنامهریزی پیشبینانه برای دورههای پرترافیک
۳. پیچیدگی مدیریت چندین مدل
چالش: استفاده همزمان از مدلهای مختلف پیچیدگی مدیریت را افزایش میدهد.
راهحل:
- توسعه لایه میانی (Middleware) برای مدیریت واحد
- استانداردسازی رابطهای ارتباطی
- خودکارسازی انتخاب مدل
آینده تکنولوژی و پیشبینیها
روندهای نوظهور
۱. مدلهای کارآمدتر: شرکتهای تکنولوژی مدام در حال توسعه مدلهایی هستند که کارایی بالاتر و هزینه کمتری دارند.
۲. قیمتگذاری پویا: احتمال معرفی مدلهای قیمتگذاری جدید بر اساس زمان، نوع کاربرد و حجم مصرف.
۳. ابزارهای بهینهسازی خودکار: توسعه ابزارهایی که بدون دخالت انسان، بهترین تنظیمات را برای کاهش هزینه پیدا میکنند.
تأثیر بر صنایع مختلف
بخش مالی:
- ۲۵ درصد کاهش هزینههای عملیاتی
- بهبود تجربه مشتری
- خودکارسازی فرآیندهای پیچیده
تولید:
- ۳۲ درصد بهبود در کارایی تولید
- کاهش ضایعات و افزایش کیفیت
- پیشبینی دقیقتر تقاضا
بازاریابی:
- شخصیسازی بهتر محتوا
- افزایش نرخ تبدیل
- کاهش هزینه تولید محتوا
ابزارها و پلتفرمهای پیشنهادی
ابزارهای مونیتورینگ
۱. CloudZero:
- مونیتورینگ دقیق هزینهها
- تحلیل روندهای مصرف
- هشدارهای خودکار
۲. Moesif:
- تحلیل عملکرد API
- ردیابی کاربران
- گزارشگیری تفصیلی
۳. Holori:
- مدیریت مالی جامع
- پیشبینی هزینهها
- بهینهسازی خودکار
ابزارهای توسعه
۱. LangChain:
- مدیریت زنجیرههای پیچیده
- بهینهسازی پرامپت
- ادغام چندین مدل
۲. OpenAI SDK:
- رابط برنامهنویسی آسان
- مدیریت خطا
- پشتیبانی از کش
۳. PromptHub:
- مدیریت و بهینهسازی پرامپتها
- آزمایش A/B
- اشتراکگذاری الگوها
نتیجهگیری
کاهش هزینههای استفاده از API های هوش مصنوعی نهتنها امکانپذیر است، بلکه با اعمال استراتژیهای علمی و عملی، میتواند به کاهش قابل توجه هزینهها منجر شود. مطالعات نشان میدهند که سازمانها با پیادهسازی صحیح این تکنیکها میتوانند تا ۷۰ درصد از هزینههای خود را کاهش دهند.
با توسعه مداوم تکنولوژیهای هوش مصنوعی، انتظار میرود که مدلهای جدید کارآمدتر و ابزارهای بهینهسازی پیشرفتهتری معرفی شوند. سازمانهایی که از همین امروز استراتژیهای بهینهسازی را پیادهسازی کنند، در آینده مزیت رقابتی بیشتری خواهند داشت.