یادگیری ماشین (Machine Learning) به عنوان یکی از شاخههای پرتحول هوش مصنوعی، در حال دگرگون کردن صنایع مختلف است. در قلب بسیاری از الگوریتمهای یادگیری ماشین، فرآیندی به نام «آموزش» (Training) قرار دارد که طی آن، مدل تلاش میکند تا از دادهها الگوها را بیاموزد. یکی از مولفههای حیاتی که موفقیت و کارایی این فرآیند آموزش را به شدت تحت تاثیر قرار میدهد، نرخ یادگیری (Learning Rate) است. اما نرخ یادگیری دقیقاً چیست و چرا تا این حد اهمیت دارد؟
در این مقاله جامع، به زبانی ساده و روان به بررسی مفهوم نرخ یادگیری در ماشین لرنینگ، اهمیت آن، چالشهای انتخاب نرخ نامناسب و روشهای تعیین نرخ بهینه خواهیم پرداخت. اگر به دنبال درک عمیقتری از این مفهوم کلیدی هستید، تا انتهای این مطلب با ما همراه باشید.
نرخ یادگیری (Learning Rate) چیست؟ تعریف و مفهوم بنیادین
در سادهترین تعریف، نرخ یادگیری یک هایپرپارامتر (Hyperparameter) در الگوریتمهای بهینهسازی، مانند گرادیان کاهشی (Gradient Descent)، است که اندازه گامهایی را که الگوریتم برای رسیدن به بهترین راهحل (کمترین خطا) برمیدارد، کنترل میکند.
بیایید این تعریف را کمی بازتر کنیم:
- هایپرپارامتر: برخلاف پارامترهای مدل که در طول فرآیند آموزش توسط خود مدل یاد گرفته میشوند (مانند وزنها در یک شبکه عصبی)، هایپرپارامترها مقادیری هستند که قبل از شروع آموزش توسط توسعهدهنده یا مهندس یادگیری ماشین تنظیم میشوند. Learning Rate یکی از مهمترین هایپرپارامترهاست.
- الگوریتم بهینهسازی: هدف این الگوریتمها، به حداقل رساندن یک «تابع هزینه» (Cost Function یا Loss Function) است. تابع هزینه، میزان خطای مدل در پیشبینیهایش را اندازهگیری میکند. الگوریتمهایی مانند گرادیان کاهشی سعی میکنند با تنظیم پارامترهای مدل، این خطا را کاهش دهند.
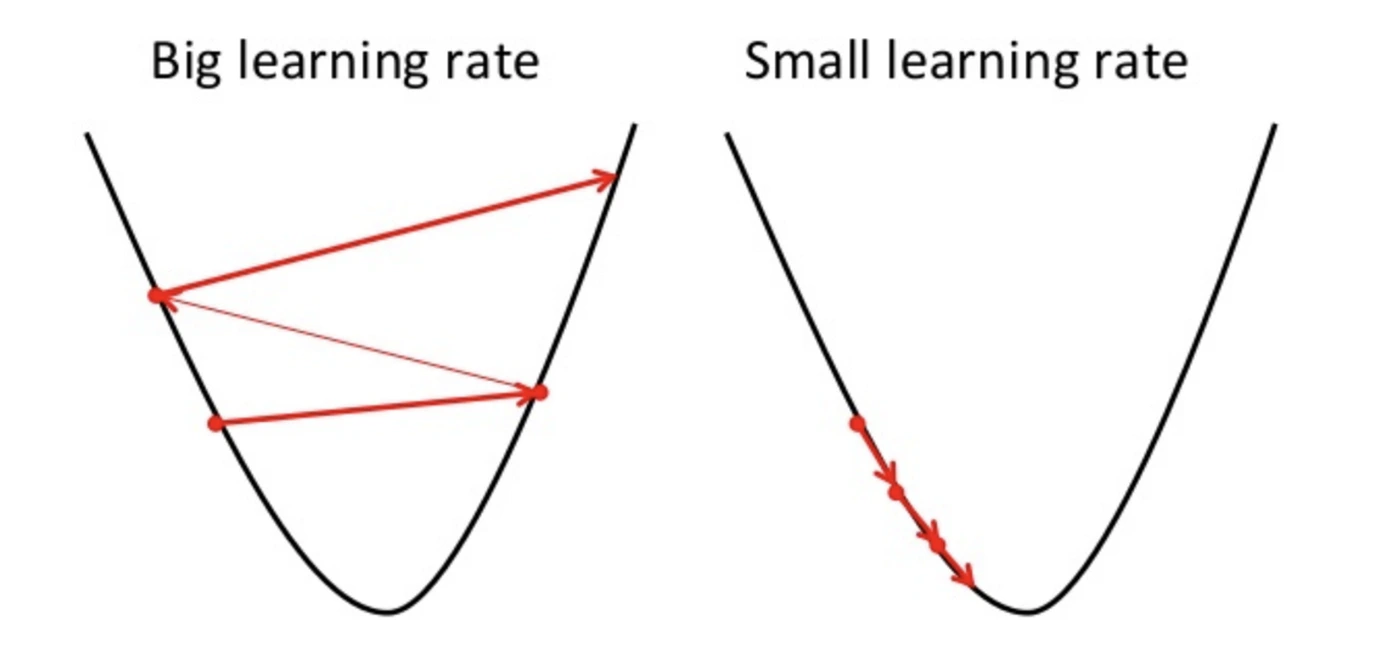
- اندازه گام: تصور کنید در حال پایین آمدن از یک کوه در مه غلیظ هستید و میخواهید به پایینترین نقطه دره برسید (این نقطه معادل کمترین خطا در مدل است). نرخ یادگیری، اندازه قدمهای شما را در هر مرحله تعیین میکند. اگر قدمهای شما خیلی کوچک باشد، زمان زیادی طول میکشد تا به دره برسید. اگر قدمهایتان خیلی بزرگ باشد، ممکن است از روی دره بپرید و هرگز به آن نرسید یا حتی شروع به بالا رفتن از دامنه دیگری کنید!
بنابراین، Learning Rate مشخص میکند که مدل با چه سرعتی و به چه میزان باید پارامترهای داخلی خود (مثلاً وزنها و بایاسها در شبکههای عصبی) را در هر تکرار (epoch) از فرآیند آموزش، بر اساس خطای محاسبهشده، بهروزرسانی کند. مقدار آن معمولاً یک عدد مثبت کوچک است (مثلاً بین 0.0001 تا 0.1).
فرمول ساده بهروزرسانی وزنها با استفاده از نرخ یادگیری:
وزن جدید = وزن قدیم - (نرخ یادگیری * گرادیان تابع هزینه)
در این فرمول، گرادیان تابع هزینه، جهت و شیب بیشترین افزایش خطا را نشان میدهد. با حرکت در خلاف جهت گرادیان، مدل به سمت کاهش خطا پیش میرود و Learning Rate، طول این حرکت را تعیین میکند.
چرا نرخ یادگیری تا این حد مهم است؟ تأثیر مستقیم بر عملکرد مدل
انتخاب نرخ یادگیری مناسب، تأثیر چشمگیری بر سرعت آموزش، کیفیت همگرایی (convergence) و در نهایت، عملکرد نهایی مدل دارد. بیایید ببینیم انتخاب نرخ یادگیری نامناسب چه عواقبی میتواند داشته باشد:
۱. نرخ یادگیری خیلی کوچک (Too Small Learning Rate)
- کند شدن شدید فرآیند آموزش: اگر گامها بسیار کوچک باشند، مدل برای رسیدن به نقطه بهینه (کمترین خطا) به تعداد تکرارهای بسیار زیادی نیاز خواهد داشت. این امر باعث طولانی شدن زمان آموزش و افزایش هزینههای محاسباتی میشود.
- گیر افتادن در مینیمم محلی (Local Minima): تابع هزینه در مدلهای پیچیده میتواند چندین نقطه مینیمم داشته باشد. اگر نرخ یادگیری خیلی کوچک باشد، ممکن است مدل در یک مینیمم محلی که بهینه جهانی (Global Minimum) نیست، گیر کند و نتواند به بهترین راهحل ممکن دست یابد. مانند کوهنوردی که در یک چاله کوچک گیر میکند و فکر میکند به پایینترین نقطه رسیده است، در حالی که دره عمیقتری در ادامه مسیر وجود دارد.
- نیاز به ایپاکهای (Epochs) بیشتر: هر ایپاک به یک دور کامل آموزش مدل روی کل مجموعه داده آموزشی گفته میشود. با نرخ یادگیری پایین، تعداد ایپاکهای لازم برای همگرایی افزایش مییابد.
۲. نرخ یادگیری خیلی بزرگ (Too Large Learning Rate)
- عدم همگرایی مدل (Divergence): اگر گامها بسیار بزرگ باشند، ممکن است مدل در هر بهروزرسانی از روی نقطه بهینه «بپرد» و هرگز به آن نزدیک نشود. در موارد شدیدتر، تابع هزینه ممکن است به جای کاهش، شروع به افزایش کند که به این پدیده واگرایی یا عدم همگرایی (Divergence) گفته میشود. این مانند کوهنوردی است که با برداشتن قدمهای خیلی بلند، دائماً از یک سمت دره به سمت دیگر میپرد و دورتر میشود.
- نوسانات شدید در تابع هزینه: حتی اگر مدل واگرا نشود، Learning Rate بزرگ میتواند باعث نوسانات شدید و ناپایدار در مقدار تابع هزینه در طول آموزش شود. این امر رسیدن به یک راهحل پایدار و خوب را دشوار میکند.
- از دست دادن مینیمم بهینه: مدل ممکن است از کنار مینیمم بهینه عبور کرده و در یک نقطه با خطای بالاتر مستقر شود.
۳. نرخ یادگیری مناسب (Optimal Learning Rate)
- همگرایی سریعتر: مدل با سرعت معقولی به سمت راهحل بهینه حرکت میکند.* رسیدن به مینیمم بهینه (یا نزدیک به آن): احتمال بیشتری وجود دارد که مدل به مینیمم جهانی تابع هزینه یا یک مینیمم محلی بسیار خوب برسد.
- عملکرد بهتر و پایدارتر مدل: مدل نهایی از دقت و قابلیت تعمیم بالاتری برخوردار خواهد بود.
پیدا کردن این “نقطه شیرین” برای نرخ یادگیری یکی از چالشهای مهم در آموزش مدلهای یادگیری ماشین است.
چگونه Learning Rate مناسب را انتخاب کنیم؟ روشها و تکنیکها
متأسفانه، هیچ فرمول جادویی برای تعیین نرخ یادگیری بهینه برای همه مدلها و همه مجموعه دادهها وجود ندارد. انتخاب آن اغلب نیازمند آزمون و خطا و تجربه است. با این حال، روشها و تکنیکهای مختلفی برای کمک به این فرآیند توسعه یافتهاند:
۱. آزمون و خطا (Trial and Error)
سادهترین روش، شروع با یک مقدار رایج (مثلاً 0.1، 0.01، 0.001) و مشاهده رفتار مدل (میزان کاهش تابع هزینه، دقت مدل بر روی داده اعتبارسنجی) است. سپس میتوان این مقدار را به صورت دستی کم یا زیاد کرد. این روش میتواند زمانبر باشد.
۲. جستجوی شبکهای (Grid Search) و جستجوی تصادفی (Random Search)
در این روشها، مجموعهای از مقادیر مختلف برای Learning Rate (و سایر هایپرپارامترها) تعریف میشود. سپس مدل با هر ترکیب از این مقادیر آموزش داده شده و بهترین ترکیب بر اساس یک معیار ارزیابی (مانند دقت) انتخاب میشود. جستجوی شبکهای تمام ترکیبات ممکن را امتحان میکند، در حالی که جستجوی تصادفی به صورت تصادفی نمونهبرداری میکند.
۳. تکنیکهای یافتن نرخ یادگیری (Learning Rate Finder Techniques)
یکی از تکنیکهای محبوب، روشی است که توسط لزلی اسمیت (Leslie N. Smith) در مقاله “Cyclical Learning Rates for Training Neural Networks” پیشنهاد شد. در این روش، آموزش با یک Learning Rate بسیار کوچک شروع شده و به تدریج در هر تکرار افزایش مییابد. با رسم نمودار تابع هزینه بر حسب نرخ یادگیری، میتوان محدودهای را شناسایی کرد که در آن تابع هزینه به سرعت شروع به کاهش میکند، اما هنوز واگرا نشده است. معمولاً یک نقطه قبل از شروع افزایش شدید تابع هزینه به عنوان نرخ یادگیری مناسب انتخاب میشود.
۴. نرخ یادگیری تطبیقی (Adaptive Learning Rates)
به جای استفاده از یک Learning Rate ثابت در طول آموزش، الگوریتمهای بهینهسازی تطبیقی، نرخ یادگیری را به صورت پویا برای هر پارامتر مدل و یا در طول زمان تنظیم میکنند. این الگوریتمها میتوانند فرآیند آموزش را تسریع کرده و به همگرایی بهتر کمک کنند. برخی از محبوبترین الگوریتمهای نرخ یادگیری تطبیقی عبارتند از:
- AdaGrad (Adaptive Gradient Algorithm): نرخ یادگیری را برای پارامترهایی که بهروزرسانیهای مکرر دریافت میکنند، کاهش میدهد و برای پارامترهایی که بهروزرسانیهای کمتری دارند، افزایش میدهد.
- RMSProp (Root Mean Square Propagation): مشابه AdaGrad است اما مشکل کاهش سریع نرخ یادگیری در AdaGrad را برطرف میکند.
- Adam (Adaptive Moment Estimation): یکی از پراستفادهترین و موثرترین الگوریتمهای بهینهسازی است که مزایای RMSProp و الگوریتم Momentum را ترکیب میکند. این الگوریتم برای هر پارامتر، نرخ یادگیری جداگانهای را محاسبه و تطبیق میدهد.
استفاده از این بهینهسازهای تطبیقی اغلب نیاز به تنظیم دستی Learning Rate اولیه را کاهش میدهد، هرچند که خود این الگوریتمها نیز هایپرپارامترهای خاص خود را دارند (مانند Learning Rate اولیه برای Adam).
۵. برنامهریزی نرخ یادگیری (Learning Rate Schedulers)
ایده اصلی در اینجا، تغییر Learning Rate بر اساس یک برنامه از پیش تعیینشده در طول فرآیند آموزش است. برخی از استراتژیهای رایج عبارتند از: کاهش پلهای (Step Decay): Learning Rate پس از تعداد مشخصی از ایپاکها با یک ضریب معین کاهش مییابد (مثلاً هر 10 ایپاک، نرخ یادگیری نصف میشود).
- کاهش نمایی (Exponential Decay): نرخ یادگیری به صورت نمایی در طول زمان کاهش مییابد.
- کاهش کسینوسی (Cosine Annealing): Learning Rate طبق یک تابع کسینوسی تغییر میکند، که میتواند به مدل کمک کند تا از مینیممهای محلی فرار کند.
- گرم کردن نرخ یادگیری (Learning Rate Warmup): در ابتدای آموزش، Learning Rate از یک مقدار بسیار کوچک به تدریج افزایش مییابد تا به نرخ یادگیری اولیه مورد نظر برسد. این کار میتواند به پایداری آموزش در مراحل اولیه کمک کند، بهخصوص برای مدلهای بزرگ.
- نرخهای یادگیری چرخهای (Cyclical Learning Rates – CLR): Learning Rate به صورت دورهای بین یک حد پایین و یک حد بالا نوسان میکند. این روش میتواند به فرار از نقاط زینی (saddle points) و مینیممهای محلی کمک کند.
کتابخانههای یادگیری عمیق مانند TensorFlow و PyTorch، پیادهسازیهای متنوعی از این زمانبندها را ارائه میدهند.
نکات عملی برای انتخاب نرخ یادگیری
- با مقادیر استاندارد شروع کنید: برای الگوریتم Adam، مقادیر اولیهای مانند 0.001 یا 0.0001 اغلب نقطه شروع خوبی هستند.
- تابع هزینه را مانیتور کنید: همیشه نمودار تابع هزینه را در طول آموزش مشاهده کنید. اگر هزینه به سرعت کاهش نمییابد، نرخ یادگیری ممکن است خیلی کوچک باشد. اگر هزینه نوسان میکند یا افزایش مییابد، Learning Rate احتمالاً خیلی بزرگ است.
- از تکنیکهای یافتن نرخ یادگیری استفاده کنید: روشهایی مانند LR Range Test میتوانند در یافتن یک محدوده مناسب برای نرخ یادگیری بسیار مفید باشند.
- صبور باشید و آزمایش کنید: تنظیم هایپرپارامترها، از جمله Learning Rate، یک فرآیند تکراری است. انتظار نداشته باشید در اولین تلاش به بهترین نتیجه برسید.
- به معماری مدل و دادهها توجه کنید: Learning Rate بهینه میتواند بسته به پیچیدگی مدل، اندازه مجموعه داده و ویژگیهای دادهها متفاوت باشد.
جمعبندی و نتیجهگیری
نرخ یادگیری یکی از مهمترین هایپرپارامترها در آموزش مدلهای یادگیری ماشین است که تأثیر مستقیمی بر سرعت، پایداری و کیفیت همگرایی مدل دارد. انتخاب یک نرخ یادگیری خیلی کوچک میتواند منجر به آموزش بسیار کند و گیر افتادن در مینیممهای محلی شود، در حالی که Learning Rate خیلی بزرگ میتواند باعث عدم همگرایی و نوسانات شدید در عملکرد مدل گردد.
درک عمیق این مفهوم و تسلط بر روشهای تنظیم آن، یک مهارت کلیدی برای هر متخصص یادگیری ماشین و عاملی تعیینکننده در موفقیت پروژههای هوش مصنوعی است. با پیشرفت تحقیقات در زمینه بهینهسازی، انتظار میرود روشهای هوشمندانهتر و خودکارتر برای تنظیم Learning Rate در آینده پدیدار شوند.