هوش مصنوعی (AI) امروز به یکی از مهم ترین ابزارهای توسعه فناوری تبدیل شده است. ساخت اولین پروژه هوش مصنوعی می تواند دریچه ای به دنیای نوآوری و بهینه سازی فرآیندها باز کند. در این مقاله، به صورت علمی و عملی، مراحل ساخت اولین پروژه هوش مصنوعی را با زبانی ساده و روان توضیح می دهم. همچنین نکات فنی مهم و ابزارهای کاربردی را معرفی می کنم تا شما بتوانید با اطمینان قدم در این مسیر بگذارید.
تعریف هدف و نیاز پروژه هوش مصنوعی
قبل از شروع، باید هدف پروژه را مشخص کنید. به سوالات زیر پاسخ دهید:
- می خواهم چه مشکلی را حل کنم؟
- چه داده هایی در اختیار دارم یا باید جمع آوری کنم؟
- کاربران نهایی پروژه چه کسانی هستند؟
تعریف دقیق هدف و نیازها، مسیر توسعه پروژه را روشن می کند و از اتلاف وقت جلوگیری می کند.
انتخاب ابزار و فناوری مناسب
برای ساخت پروژه های هوش مصنوعی، ابزارهای متعددی وجود دارد که هر کدام برای کاربردهای خاص مناسب اند. مهم ترین و محبوب ترین ابزارها عبارت اند از:
- TensorFlow: یک کتابخانه متن باز برای یادگیری ماشین و یادگیری عمیق که توسط گوگل توسعه یافته است.
- PyTorch: کتابخانه ای برای یادگیری عمیق با امکانات پویا و انعطاف پذیر که توسط فیس بوک ارائه شده است.
- Scikit-learn: مناسب برای الگوریتم های یادگیری ماشین کلاسیک و پروژه های سبک تر.
همچنین انتخاب زبان برنامه نویسی نقش مهمی دارد. زبان Python به دلیل سادگی و گستردگی کتابخانه ها، بهترین گزینه برای شروع است.
جمع آوری و آماده سازی داده ها
هوش مصنوعی بدون داده معنی ندارد. داده ها پایه و اساس مدل های AI هستند. مراحل اصلی شامل:
- جمع آوری داده های مرتبط با مسئله
- پاک سازی و اصلاح داده ها (حذف داده های ناقص یا اشتباه)
- تبدیل داده ها به فرمت قابل استفاده برای مدل (مثلاً نرمال سازی یا کدگذاری)
دقت در این مرحله کیفیت پروژه را تضمین می کند.
انتخاب مدل و الگوریتم مناسب
بسته به نوع مسئله (طبقه بندی، پیش بینی، خوشه بندی و…) باید مدل مناسب را انتخاب کنید. برای مثال:
- برای مسائل طبقه بندی می توانید از الگوریتم هایی مانند درخت تصمیم، ماشین بردار پشتیبان (SVM) یا شبکه های عصبی استفاده کنید.
- برای مسائل پیش بینی سری های زمانی، مدل های RNN یا LSTM مناسب اند.
توصیه می کنم ابتدا با مدل های ساده شروع کنید و به تدریج به مدل های پیچیده تر بروید.
آموزش مدل و ارزیابی عملکرد
با استفاده از داده های آماده شده، مدل را آموزش دهید. در این مرحله باید:
- داده ها را به مجموعه های آموزش و تست تقسیم کنید.
- مدل را با داده های آموزش آموزش دهید.
- عملکرد مدل را با داده های تست ارزیابی کنید (مثلاً با استفاده از معیارهایی مثل دقت، صحت، F1-score).
اگر مدل عملکرد مناسبی نداشت، باید تنظیم پارامترها (Hyperparameter Tuning) انجام دهید یا مدل را تغییر دهید.
پیاده سازی و استفاده از مدل در پروژه
پس از آموزش و ارزیابی، مدل را در محیط واقعی یا نرم افزار هدف پیاده سازی کنید. می توانید از فریم ورک هایی مانند Flask یا FastAPI برای ایجاد API استفاده کنید که مدل را در اختیار برنامه ها یا کاربران قرار دهد. همچنین می توانید مدل را در برنامه های دسکتاپ، وب یا موبایل به کار ببرید.
۱. تعریف پروژه هوش مصنوعی
قبل از شروع به کار، باید پروژه خود را بهخوبی تعریف کنید. این شامل تعیین اهداف، نیازها و الزامات پروژه است. به سوالات زیر پاسخ دهید:
هدف نهایی پروژه چیست؟
چه مشکلی را حل میکند؟
کاربران هدف چه کسانی هستند؟
۲. انتخاب ابزار و فناوریهای مناسب
برای ساخت پروژههای هوش مصنوعی، انتخاب ابزار و فناوریهای مناسب از اهمیت بالایی برخوردار است. برخی از ابزارهای محبوب شامل:
TensorFlow: یک کتابخانه متنباز برای یادگیری ماشین.
PyTorch: یک کتابخانه دیگر برای یادگیری عمیق.
Scikit-learn: برای الگوریتمهای یادگیری ماشین.
۲.۱. انتخاب زبان برنامهنویسی
زبانهای برنامهنویسی مختلفی وجود دارد که میتوانید برای پروژههای هوش مصنوعی از آنها استفاده کنید. Python یکی از محبوبترین زبانها بهخاطر سادگی و کتابخانههای گستردهاش است.
۳. جمعآوری دادهها
دادهها مهمترین رکن هوش مصنوعی هستند. برای آموزش مدلهای خود، به دادههای باکیفیت نیاز دارید. مراحل جمعآوری دادهها شامل:
شناسایی منابع داده: آیا دادهها را از اینترنت جمعآوری میکنید یا از پایگاههای داده موجود استفاده میکنید؟
پاکسازی دادهها: دادهها باید تمیز و بدون خطا باشند.
۴. آموزش مدل
پس از جمعآوری و پاکسازی دادهها، نوبت به آموزش مدل میرسد. این مرحله شامل:
انتخاب مختلفی وجود دارند که میتوانید برای آموزش مدل خود انتخاب کنید. انتخاب الگوریتم مناسب بستگی به نوع دادهها و هدف پروژه دارد.
تنظیم پارامترها: تنظیم پارامترهای مدل میتواند تأثیر زیادی بر دقت آن داشته باشد.
۵. ارزیابی مدل
پس از آموزش مدل، باید آن را ارزیابی کنید. این کار شامل:
تقسیم دادهها: دادهها را به دو بخش آموزش و تست تقسیم کنید.
استفاده از معیارهای ارزیابی: معیارهایی مانند دقت، یادآوری و F1-score میتوانند به شما کمک کنند تا عملکرد مدل را بسنجید.
۶. بهینهسازی مدل
پس از ارزیابی، ممکن است نیاز به بهینهسازی مدل داشته باشید. این کار شامل:
تنظیم مجدد پارامترها: با تغییر پارامترها میتوانید عملکرد مدل را بهبود بخشید.
استفاده از تکنیکهای پیشرفته: تکنیکهایی مانند Dropout و Regularization میتوانند به جلوگیری از Overfitting کمک کنند.
۷. پیادهسازی پروژه
پس از بهینهسازی مدل، نوبت به پیادهسازی پروژه میرسد. این مرحله شامل:
توسعه رابط کاربری: اگر پروژه شما نیاز به رابط کاربری دارد، باید آن را طراحی و توسعه دهید.
یکپارچگی با سیستمهای دیگر: ممکن است لازم باشد پروژه خود را با سیستمهای دیگر یکپارچه کنید.
۸. تست و عیبیابی
پس از پیادهسازی، پروژه باید تست شود. این مرحله شامل:
تست عملکرد: بررسی کنید که آیا پروژه به درستی کار میکند یا خیر.
شناسایی و رفع اشکالات: هرگونه اشکالی که در حین تست مشاهده میشود باید برطرف شود.
۹. راهاندازی و نگهداری
پس از اتمام مراحل بالا، پروژه شما آماده راهاندازی است. اما نگهداری و بهروزرسانی پروژه نیز از اهمیت بالایی برخوردار است. این شامل:
نظارت بر عملکرد: عملکرد پروژه را بهطور مداوم نظارت کنید.
بهروزرسانی دادهها و مدل: با گذشت زمان، دادهها و نیازها تغییر میکنند. بنابراین، باید مدل و دادهها را بهروزرسانی کنید.
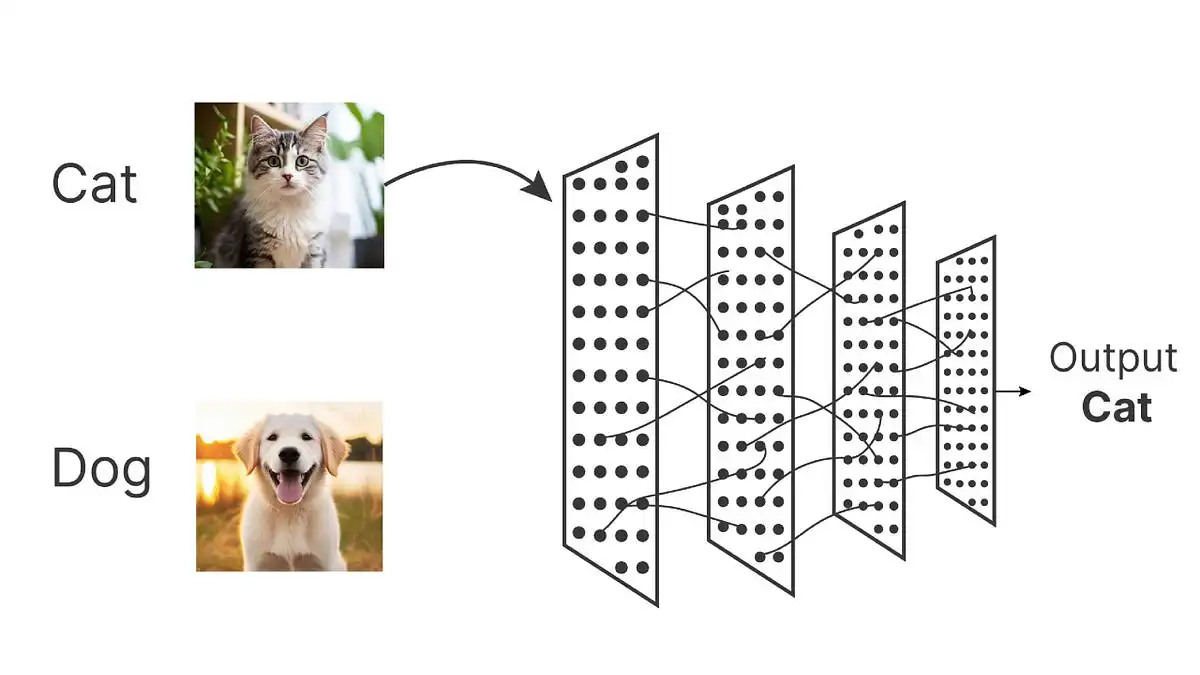
مثال عملی: ساخت یک پروژه هوش مصنوعی برای تشخیص تصاویر
در این بخش، یک مثال عملی از ساخت یک پروژه هوش مصنوعی برای تشخیص تصاویر را بررسی خواهیم کرد. هدف ما این است که یک مدل یادگیری عمیق برای تشخیص و طبقهبندی تصاویر حیوانات (مانند گربهها و سگها) بسازیم. این پروژه شامل مراحل جمعآوری داده، آموزش مدل، ارزیابی و پیادهسازی خواهد بود.
۱. تعریف پروژه
هدف پروژه ما تشخیص و طبقهبندی تصاویر بین دو نوع حیوان (گربه و سگ) است. این پروژه میتواند بهعنوان یک اپلیکیشن موبایل یا وب برای کمک به کاربران در شناسایی حیوانات مختلف استفاده شود.
۲. انتخاب ابزار و فناوریهای مناسب
برای این پروژه، ما از ابزارها و کتابخانههای زیر استفاده خواهیم کرد:
- زبان برنامهنویسی: Python
- کتابخانه یادگیری عمیق: TensorFlow و Keras
- کتابخانه پردازش تصویر: OpenCV
- پایگاه داده: مجموعه دادههای CIFAR-10 (که شامل تصاویر گربهها و سگها است)
۳. جمعآوری دادهها
ما از مجموعه دادههای CIFAR-10 استفاده خواهیم کرد که شامل ۶۰۰۰۰ تصویر در ۱۰ کلاس مختلف است. برای این پروژه، ما فقط به دو کلاس (گربه و سگ) نیاز داریم.
۳.۱. بارگذاری دادهها
import tensorflow as tf
from tensorflow.keras.datasets import cifar10
# بارگذاری مجموعه دادهها
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
# فیلتر کردن فقط کلاسهای گربه و سگ
import numpy as np
cat_dog_indices = np.where((y_train == 3) | (y_train == 5))
x_train = x_train[cat_dog_indices]
y_train = y_train[cat_dog_indices]
cat_dog_indices_test = np.where((y_test == 3) | (y_test == 5))
x_test = x_test[cat_dog_indices_test]
y_test = y_test[cat_dog_indices_test]
# تغییر برچسبها به 0 و 1
y_train[y_train == 3] = 0
y_train[y_train == 5] = 1
y_test[y_test == 3] = 0
y_test[y_test == 5] = 1
۴. آموزش مدل
۴.۱. ساخت مدل
ما از یک مدل شبکه عصبی کانولوشنی (CNN) برای تشخیص تصاویر استفاده خواهیم کرد.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),
MaxPooling2D(pool_size=(2, 2)),
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D(pool_size=(2, 2)),
Flatten(),
Dense(128, activation='relu'),
Dense(1, activation='sigmoid') # خروجی 0 یا 1
])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
۴.۲. آموزش مدل
model.fit(x_train, y_train, epochs=10, batch_size=64, validation_data=(x_test, y_test))
۵. ارزیابی مدل
پس از آموزش مدل، باید آن را ارزیابی کنیم.
test_loss, test_accuracy = model.evaluate(x_test, y_test)
print(f"Test accuracy: {test_accuracy}")
۶. بهینهسازی مدل
اگر دقت مدل پایین باشد، میتوانیم از تکنیکهای بهینهسازی مانند افزایش دادهها (Data Augmentation) استفاده کنیم.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest'
)
datagen.fit(x_train)
model.fit(datagen.flow(x_train, y_train, batch_size=64), epochs=10, validation_data=(x_test, y_test))
۷. پیادهسازی پروژه
۷.۱. توسعه رابط کاربری
برای پیادهسازی این پروژه، میتوانیم از فریمورکهای وب مانند Flask یا Django استفاده کنیم. در اینجا یک مثال ساده از یک اپلیکیشن Flask آورده شده است:
from flask import Flask, request, jsonify
import numpy as np
import cv2
app = Flask(__name__)
@app.route('/predict', methods=['POST'])
def predict():
file = request.files['image']
img = cv2.imdecode(np.fromstring(file.read(), np.uint8), cv2.IMREAD_COLOR)
img = cv2.resize(img, (32, 32))
img = img / 255.0 # نرمالسازی
img = np.expand_dims(img, axis=0)
prediction = model.predict(img)
label = 'Cat' if prediction[0][0] < 0.5 else 'Dog'
return jsonify({'prediction': label})
if __name__ == '__main__':
app.run(debug=True)
۸. تست و عیبیابی
پس از پیادهسازی، باید اپلیکیشن را تست کنیم. میتوانیم با استفاده از ابزارهایی مانند Postman یا curl، درخواستهایی به سرور ارسال کنیم و بررسی کنیم که آیا پیشبینیها به درستی انجام میشوند یا خیر.
۹. راهاندازی و نگهداری
پس از اطمینان از عملکرد صحیح پروژه، میتوانیم آن را در یک سرور واقعی راهاندازی کنیم. همچنین باید بهطور منظم عملکرد مدل را نظارت کنیم و در صورت نیاز آن را بهروزرسانی کنیم.
نتیجهگیری
با دنبال کردن مراحل ذکر شده و استفاده از ابزارهای مناسب، توانستیم یک پروژه هوش مصنوعی برای تشخیص تصاویر گربهها و سگها بسازیم. این پروژه نهتنها به ما کمک میکند تا با مفاهیم هوش مصنوعی آشنا شویم، بلکه میتواند بهعنوان یک اپلیکیشن کاربردی در دنیای واقعی نیز مورد استفاده قرار گیرد.