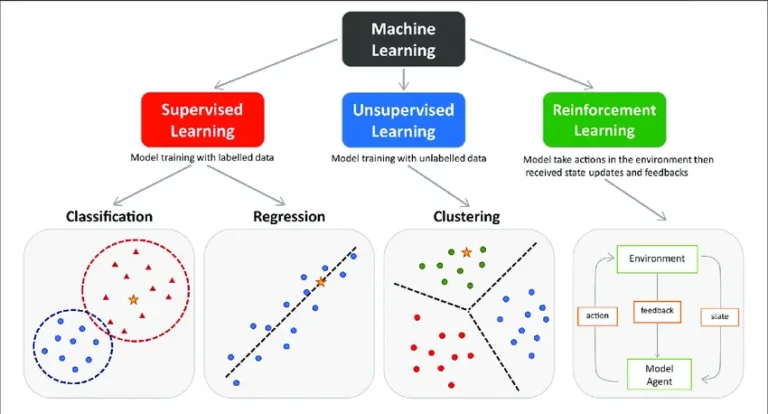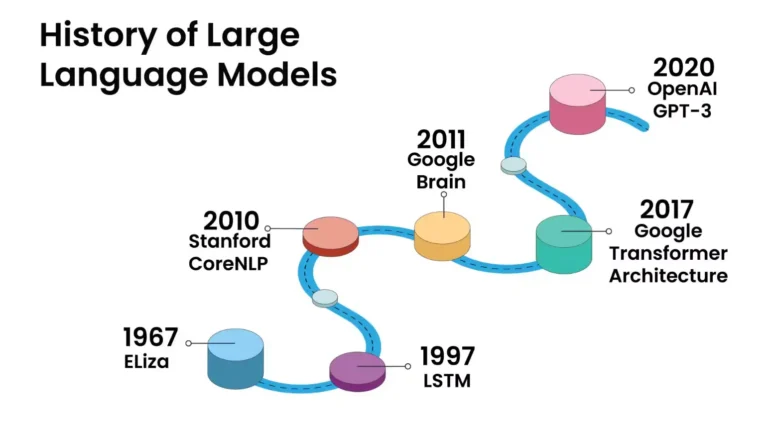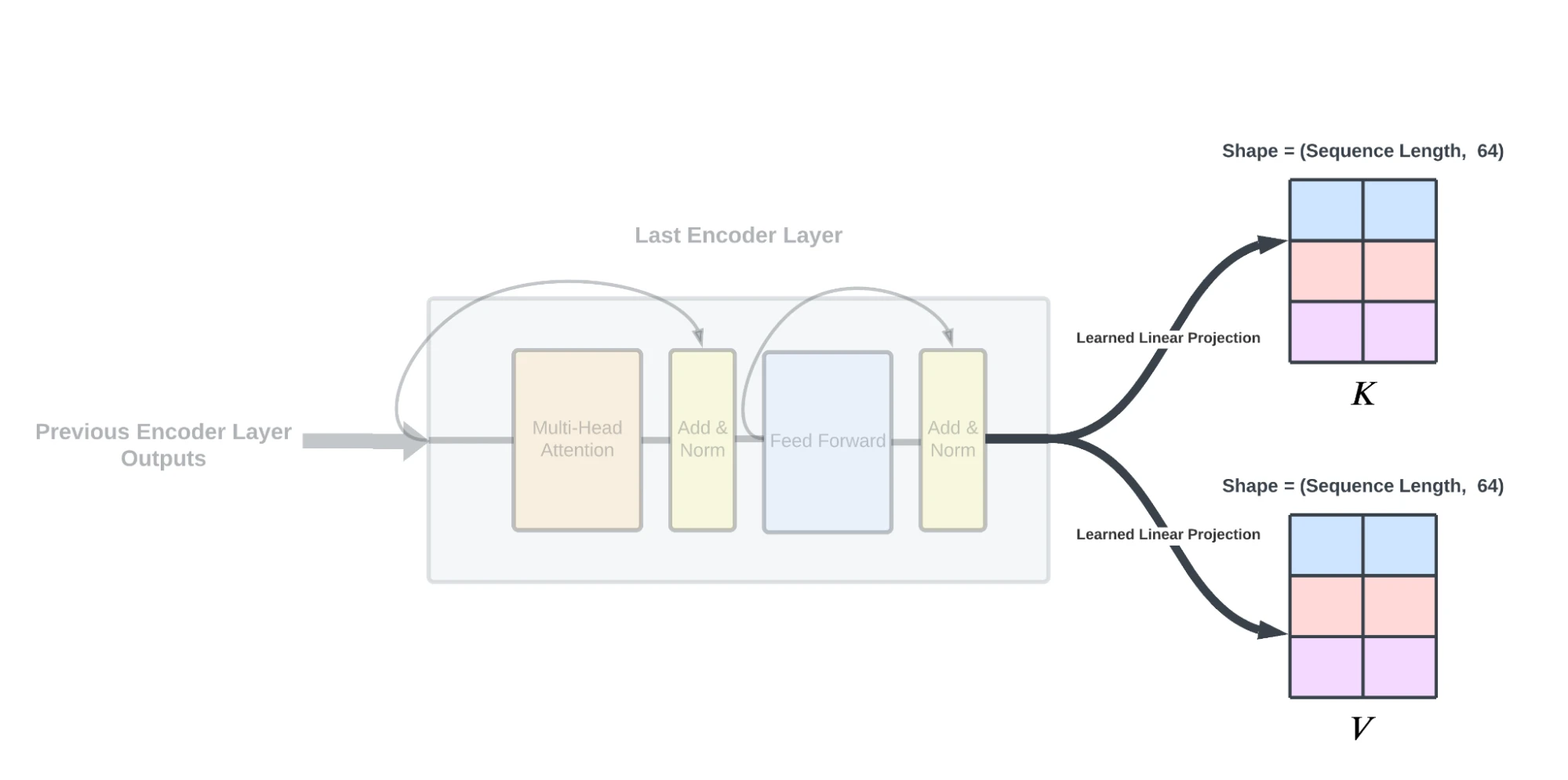
معماری Transformer که در سال ۲۰۱۷ معرفی شد، انقلابی شگرف در حوزه یادگیری عمیق ایجاد کرد و پایهگذار مدلهای زبانی بزرگ امروزی شد. با این حال، محدودیتهای ذاتی این معماری از جمله پیچیدگی محاسباتی درجه دوم و چالشهای پردازش توالیهای بلند، محققان را به سمت جستجوی معماریهای جایگزین سوق داده است. این مقاله به بررسی جامع تحولات معماریهای شبکههای عصبی از دوران Transformer تا معماریهای نوظهور میپردازد و آینده این حوزه را تحلیل میکند.
مقدمه
معماری Transformer که اولین بار در مقاله تأثیرگذار “Attention is All You Need” در سال ۲۰۱۷ توسط محققان گوگل معرفی شد، به یک نقطه عطف در یادگیری عمیق تبدیل شده است. این معماری با استفاده از مکانیسم خودتوجه (Self-Attention) توانست محدودیتهای شبکههای عصبی بازگشتی (RNN) را پشت سر بگذارد و راه را برای مدلهای زبانی بزرگی همچون GPT و BERT هموار کند.
برخلاف معماریهای RNN که از واحدهای بازگشتی استفاده میکردند و نیاز به زمان آموزش طولانیتری داشتند، Transformer بدون استفاده از بازگشت عمل میکند و امکان موازیسازی بهتری را فراهم میآورد.
بخش اول: معماری Transformer – پایهگذار انقلاب
مکانیسم خودتوجه
Transformer یک نوع شبکه عصبی است که با تحلیل الگوها در مقادیر زیادی از دادههای متنی، زمینه را درک کرده و دادههای جدیدی تولید میکند. قلب تپنده این معماری، مکانیسم خودتوجه است که به مدل اجازه میدهد تا روابط بین اجزای مختلف یک توالی ورودی را شناسایی کند.
مکانیسم خودتوجه به مدل امکان میدهد تا بر بخشهای مختلف توالی ورودی تمرکز کند و میزان توجه لازم به هر بخش را هنگام پردازش یک کلمه یا عنصر خاص تعیین نماید.
اجزای کلیدی
معماری استاندارد Transformer شامل اجزای زیر است:
۱. لایههای رمزگذار و رمزگشا
- رمزگذار (Encoder) وظیفه پردازش ورودی را بر عهده دارد
- رمزگشا (Decoder) خروجی نهایی را تولید میکند
۲. توجه چندسرِ (Multi-Head Attention) توجه چندسرِ به مدل اجازه میدهد تا به جنبههای مختلف ورودی توجه کند و نمایشهای متنوعی را یاد بگیرد.
۳. کدگذاری موقعیتی کدگذاری موقعیتی به مدل حسی از ترتیب کلمات یا عناصر در توالی میدهد، زیرا برخلاف RNN، Transformer دادهها را به ترتیب پردازش نمیکند.
مزایای Transformer
معماری Transformer مزایای قابل توجهی نسبت به مدلهای پردازش توالی قبلی دارد، از جمله توانایی پردازش موازی کل توالیها که سرعت آموزش و استنتاج را به طور قابل ملاحظهای افزایش میدهد.
بخش دوم: محدودیتهای بنیادین Transformer
پیچیدگی محاسباتی درجه دوم
یکی از اساسیترین مشکلات Transformer، پیچیدگی محاسباتی O(n²) آن است که با افزایش طول توالی ورودی، منابع محاسباتی مورد نیاز به صورت تصاعدی افزایش مییابد.
بسیاری از معماریهای زیردرجهدوم مانند توجه خطی، کانولوشن دروازهای، مدلهای بازگشتی و مدلهای فضای حالت ساختاریافته (SSM) برای رفع ناکارآمدی محاسباتی Transformer در توالیهای بلند توسعه یافتهاند، اما در مدالیتههای مهمی چون زبان به خوبی توجه عمل نکردهاند.
محدودیت حافظه و زمینه
گلوگاه درجه دوم اغلب عامل تأخیر آزاردهنده بین پرسیدن سؤال از مدل و دریافت پاسخ است و همچنین محاسبات زائد زیادی ایجاد میکند.
مدلهای فعلی کل پرامپت و خروجی را میخوانند، یک توکن را پیشبینی میکنند، دوباره همه چیز را میخوانند، توکن بعدی را پیشبینی میکنند و این روند تا رسیدن به پاسخ ادامه مییابد. آنها حافظه کوتاهمدت فوقالعادهای دارند، اما در حافظه بلندمدت ضعیف هستند.
مصرف انرژی و هزینه
با افزایش اندازه مدلها تا صدها میلیارد پارامتر، مصرف انرژی و هزینه آموزش و استنتاج به چالشی جدی تبدیل شده است که نیاز به معماریهای کارآمدتر را دوچندان میکند.
بخش سوم: تکامل داخلی Transformer (۲۰۱۷-۲۰۲۴)
بهینهسازیهای معماری
از سال ۲۰۱۷ تا ۲۰۲۴، معماری Transformer بهبودهای اساسی را برای رفع چالشهای مربوط به پایداری آموزش، کارایی محاسباتی و تنظیم دقیق تجربه کرده است.
تغییرات کلیدی در Transformer مدرن:
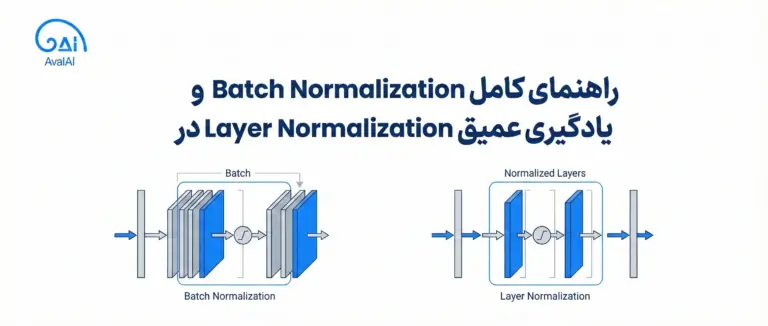
۱. نرمالسازی پیشین (Pre-Normalization) به جای رویکرد نرمالسازی پسین اولیه، معماریهای مدرن از نرمالسازی پیشین استفاده میکنند که لایههای نرمالسازی قبل از مکانیسم خودتوجه اعمال میشود.
۲. RMSNorm به جای LayerNorm RMSNorm محاسبات کمتری را در مقایسه با LayerNorm سنتی نیاز دارد و پایداری آموزش را حفظ میکند.
۳. توجه پرسوجوی گروهی (Grouped-Query Attention) این بهینهسازی با کاهش تعداد سرهای key-value، نیازهای حافظه را به طور چشمگیری کاهش میدهد.
۴. جاسازی چرخشی (Rotary Embeddings) روش پیشرفتهتری برای کدگذاری اطلاعات موقعیتی که عملکرد بهتری در وظایف متنوع ارائه میدهد.
تأثیر این تغییرات
این پیشرفتها صرفاً ظرافتهای نظری نیستند، بلکه چالشهای واقعی در مقیاسبندی مدلهای یادگیری عمیق را حل میکنند.
بخش چهارم: معماریهای جایگزین – دوران پسا-Transformer
مدلهای فضای حالت (State Space Models)
معرفی SSM
مدلهای فضای حالت برای دههها جهت مدلسازی سیستمهای دینامیک استفاده شدهاند و در رشتههای مهندسی برق، پردازش سیگنال، روباتیک و تئوری کنترل پایه و اساس هستند.
از یک سری مشاهدات، SSM یک حالت پنهان با اندازه ثابت محاسبه میکند که ویژگیهای اساسی سیستم را در خود جای میدهد. حالت را میتوان به عنوان خلاصهای از گذشته تصور کرد.
Mamba: نسل جدید SSM
Mamba یک معماری جدید مدل فضای حالت است که عملکرد امیدوارکنندهای در دادههای متراکم اطلاعاتی مانند مدلسازی زبان نشان میدهد.
ویژگیهای کلیدی Mamba:
۱. انتخابپذیری (Selectivity) انتخابپذیری به هر توکن اجازه میدهد به روشی منحصربهفرد و متناسب با نیازهای خودش به حالت تبدیل شود، و ما را از SSM معمولی (که ماتریسهای یکسان A و B را برای هر ورودی اعمال میکند) به Mamba، یعنی مدل فضای حالت انتخابپذیر، میبرد.
۲. پیچیدگی خطی Mamba از استنتاج سریع (با توان عملیاتی ۵ برابر بیشتر از Transformer) و مقیاسبندی خطی در طول توالی برخوردار است و عملکرد آن در دادههای واقعی تا توالیهایی با طول میلیونی بهبود مییابد.
۳. الگوریتم سختافزار-آگاه Mamba از یک الگوریتم سختافزار-آگاه استفاده میکند که از GPUها بهره میبرد و از ادغام هسته، اسکن موازی و محاسبه مجدد استفاده میکند.
معماری سادهشده
معماریهای مدل توالی عمیق قبلی را با ترکیب طراحی معماریهای SSM قبلی با بلوک MLP Transformer در یک بلوک واحد ساده کردیم و به یک طراحی معماری ساده و همگن (Mamba) رسیدیم.
RWKV: ترکیب RNN و Transformer
RWKV یک معماری مدل جدید به نام Receptance Weighted Key Value است که آموزش موازیپذیر Transformer را با استنتاج کارآمد RNN ترکیب میکند.
مزایای کلیدی:
در مقایسه با Transformer، RWKV توجه خطی و پیچیدگی محاسباتی و حافظه ثابت در طول استنتاج ارائه میدهد که آن را برای مدلهای مقیاس بزرگ کارآمدتر میسازد.
برای توسعهدهندگانی که بر روی دستگاههای لبه یا محیطهای حساس به تأخیر کار میکنند، RWKV جایگزینی مقرونبهصرفه و قدرتمند برای Transformer است.
RetNet: جانشین Transformer
در این کار، RetNet را به عنوان یک معماری پایه برای مدلهای زبانی بزرگ پیشنهاد میکنیم که به طور همزمان به موازیسازی آموزش، استنتاج کمهزینه و عملکرد خوب دست مییابد.
سه پارادایم محاسباتی:
مکانیسم نگهداری (Retention) برای مدلسازی توالی سه پارادایم محاسباتی را پشتیبانی میکند: موازی، بازگشتی و بازگشتی تکهای. نمایش موازی امکان موازیسازی آموزش را فراهم میکند، نمایش بازگشتی استنتاج O(1) کمهزینه را ممکن میسازد، و نمایش بازگشتی تکهای مدلسازی کارآمد توالیهای بلند با پیچیدگی خطی را تسهیل میکند.
RetNet تمایل دارد وقتی اندازه مدل بیشتر از ۲ میلیارد پارامتر باشد، از Transformer بهتر عمل کند.
بخش پنجم: معماریهای ترکیبی و MoE
Mixture of Experts (MoE)
Mixture of Experts یک رویکرد یادگیری ماشینی است که یک مدل هوش مصنوعی را به زیرشبکههای جداگانه (یا متخصصان) تقسیم میکند که هر کدام در زیرمجموعهای از دادههای ورودی تخصص دارند.
مزایای کلیدی:
مقیاس یکی از مهمترین محورهای کیفیت بهتر مدل است. با یک بودجه محاسباتی ثابت، آموزش یک مدل بزرگتر با مراحل کمتر بهتر از آموزش یک مدل کوچکتر با مراحل بیشتر است.
معماریهای MoE مدلهای مقیاس بزرگ، حتی آنهایی با میلیاردها پارامتر، را قادر میسازند تا هزینههای محاسباتی را در طول پیشآموزش به طور چشمگیری کاهش دهند و عملکرد سریعتری در زمان استنتاج داشته باشند.
معماریهای ترکیبی
Jamba: ترکیب Transformer و Mamba
Jamba یک معماری ترکیبی Transformer-Mamba MoE است که لایههای استاندارد Transformer را با ماژول تقویتشده حافظه (لایههای Mamba) درهم میآمیزد و MoE را در برخی لایهها برای گسترش ظرفیت وارد میکند.
این طراحی منجر به یک LLM قدرتمند شد که روی یک GPU تکی ۸۰ گیگابایتی جا میشود اما نتایج پیشرو در هم معیارهای استاندارد و هم وظایف زمینه بسیار طولانی (تا ۲۵۶ هزار توکن) به دست آورد.
Bamba: نوآوری IBM
تیم IBM Research به همراه خالقان Mamba، Gu و Dao، و همچنین پروفسور Zhang، معماری Mamba2 NVIDIA را انتخاب کردند و تقریباً همه چیز مرتبط با Bamba را متنباز کردند.
Bamba-9B نشان داده که میتواند حداقل دو برابر سریعتر از Transformerهای با اندازه مشابه اجرا شود، در حالی که دقت آنها را همتراز میکند.
DeepSeek-V3 و آینده MoE
DeepSeek-V3 یک استراتژی بدون تلفات کمکی برای تعادل بار را پیشگام است و نشان میدهد که معماری و مقداردهی اولیه دقیق میتواند تعادل متخصصان را بدون تلفات اضافی حفظ کند.
بخش ششم: آینده معماریهای شبکه عصبی
روندهای نوظهور
۱. معماریهای الهامگرفته از مغز ما پیشنهاد میکنیم که فراتر از معماریهای معمولی با معرفی بعد از طریق لینکهای درونلایه و دینامیک از طریق حلقههای بازخورد گسترش یابیم.
۲. یادگیری چندوجهی Transformerها به طور چشمگیری از ریشههای اولیه پردازش زبان طبیعی تکامل یافتهاند و به عنوان یک معماری همهکاره ظهور کردهاند که قابلیتهای هوش مصنوعی را در چندین حوزه بازتعریف میکند.
۳. جستجوی معماری عصبی (NAS) NAS یک رویکرد پیشگام برای هوش مصنوعی است که ماشینها معماریهای شبکه عصبی خود را طراحی میکنند، مانند دادن این توانایی به هوش مصنوعی که معمار خود شود.
چالشها و فرصتها
چالشها:
- کاهش سربار ارتباطی در آموزش توزیعشده MoE
- گسترش MoE به مدالیتهها و وظایف متنوع
- تعادل متخصصان بدون تلفات کمکی
- استفاده بهینه از سختافزار
فرصتها: با موفقیتهای مدلهای MoE متنباز در سال ۲۰۲۴، میتوان انتظار داشت که در سال ۲۰۲۵ تصفیه بیشتری از مدلهای متخصص را شاهد باشیم.
سناریوهای آینده
این پایان کار برای Transformerها نیست. اثربخشی بالای آنها دقیقاً همان چیزی است که برای بسیاری از وظایف مورد نیاز است. اما اکنون Transformerها تنها گزینه نیستند. معماریهای دیگر واقعاً امکانپذیر هستند.
ما در دوران پسا-Transformer نیستیم، بلکه برای اولین بار در دوران پسا-فقط-Transformer زندگی میکنیم و این امکانات را برای مدلسازی توالی با طول زمینه بسیار زیاد و حافظه بلندمدت بومی کاملاً باز میکند.
نتیجهگیری
خلاصه یافتهها
تحول معماریهای شبکه عصبی از Transformer به سمت راهحلهای متنوعتر و کارآمدتر نشاندهنده بلوغ حوزه یادگیری عمیق است. در حالی که Transformer همچنان ستون فقرات بسیاری از مدلهای پیشرفته باقی مانده، معماریهای نوظهور مانند Mamba، RWKV و RetNet نشان میدهند که راهحلهای جایگزین نه تنها امکانپذیر، بلکه در برخی موارد برتر هستند.
پیامدهای عملی
تکامل از Transformer سال ۲۰۱۷ به همتای آن در سال ۲۰۲۴ بر سرعت بیوقفه نوآوری در یادگیری عمیق تأکید میکند. هر تصفیه، چه نرمالسازی پیشین، توجه پرسوجوی گروهی یا جاسازی چرخشی باشد، گلوگاههای حیاتی را حل میکند و در عین حال امکانات جدیدی را برای کاربردهای هوش مصنوعی باز میکند.
دیدگاه آینده
دستیابی به هوش مصنوعی عمومی همچنان جام مقدس باقی میماند و چالشهای متعددی را ارائه میدهد که برای غلبه بر آنها نیاز به بینشهای جدید است.
آینده معماریهای شبکه عصبی احتمالاً ترکیبی از رویکردهای مختلف خواهد بود، جایی که هر معماری برای وظایف خاص بهینه شده و در کنار یکدیگر به کار گرفته میشود. این تنوع معماری نه تنها کارایی را افزایش میدهد، بلکه راه را برای ایجاد سیستمهای هوشمند انعطافپذیرتر و قدرتمندتر هموار میسازد.
توصیهها برای محققان و توسعهدهندگان
برای محققان:
- بررسی ترکیب معماریهای مختلف برای بهرهبرداری از نقاط قوت هر یک
- تمرکز بر کاهش پیچیدگی محاسباتی بدون کاهش عملکرد
- توسعه روشهای جدید برای ارزیابی و مقایسه معماریهای مختلف
برای توسعهدهندگان:
- انتخاب معماری متناسب با نیازهای خاص پروژه
- استفاده از مدلهای متنباز برای آزمایش و توسعه
- توجه به تعادل بین عملکرد و کارایی محاسباتی
پیوست: مفاهیم کلیدی و واژهنامه
Attention Mechanism (مکانیسم توجه)
الگوریتمی که به مدل کمک میکند تعیین کند در هر لحظه خاص باید بر کدام بخش از توالی داده تمرکز کند.
Self-Attention (خودتوجه)
نوع خاصی از مکانیسم توجه که به مدل اجازه میدهد روابط بین اجزای مختلف یک توالی ورودی را تحلیل کند.
State Space Model (مدل فضای حالت)
مدلهای ریاضی که برای نمایش سیستمهای دینامیک استفاده میشوند و حالت پنهانی سیستم را در طول زمان ردیابی میکنند.
Mixture of Experts (ترکیب متخصصان)
رویکردی که در آن چندین شبکه عصبی کوچکتر (متخصصان) به طور موازی کار میکنند و یک شبکه دروازهبان تصمیم میگیرد کدام متخصص برای هر ورودی فعال شود.
Quadratic Complexity (پیچیدگی درجه دوم)
پیچیدگی محاسباتی که به صورت n² با افزایش اندازه ورودی رشد میکند، که یکی از محدودیتهای اصلی Transformer است.
Linear Complexity (پیچیدگی خطی)
پیچیدگی محاسباتی که به صورت n با افزایش اندازه ورودی رشد میکند، هدف اصلی معماریهای جایگزین.
Selective SSM (SSM انتخابپذیر)
نسخه پیشرفته مدلهای فضای حالت که پارامترهای آن بر اساس ورودی تغییر میکند و امکان انتخابی نگهداری یا فراموشی اطلاعات را فراهم میآورد.
Token (توکن)
واحد پایه پردازش در مدلهای زبانی که میتواند یک کلمه، بخشی از کلمه یا یک کاراکتر باشد.
Pre-Normalization (نرمالسازی پیشین)
تکنیکی در معماریهای مدرن که لایه نرمالسازی قبل از لایههای اصلی اعمال میشود تا پایداری آموزش را بهبود بخشد.
Rotary Embeddings (جاسازی چرخشی)
روش پیشرفته کدگذاری موقعیت که از تبدیلات چرخشی برای نمایش موقعیت نسبی توکنها استفاده میکند.
نتیجهگیری نهایی
تحول پارادایم
چشمانداز هوش مصنوعی در سال ۲۰۲۵ با نوآوریهای شتابان تعریف میشود، جایی که هوش مصنوعی، هوش مصنوعی تولیدی، سیستمهای عاملی، محاسبات ابری و کوانتومی، امنیت سایبری، AR/VR، بلاکچین و پایداری، همگی تغییرات بنیادی را در صنایع و زندگی روزمره هدایت میکنند.
چالش باقیمانده
با وجود پیشرفتهای قابل توجه، چالشهای اساسی همچنان باقی میمانند:
- نیاز به مدلهایی که بتوانند با دادههای کمتر یاد بگیرند
- کاهش مصرف انرژی و هزینههای محاسباتی
- بهبود قابلیت تفسیر و شفافیت مدلها
- توسعه معماریهایی که بتوانند به طور مداوم یاد بگیرند
امید به آینده
جامعه هوش مصنوعی در حال حرکت فراتر از مدلهای یکپارچه به سمت ترکیب متخصصان، Transformerهای چندوجهی و معماریهای مدولار است که به صورت پویا محاسبات را مسیریابی میکنند.
برای توسعهدهندگانی که سیستمهای هوش مصنوعی میسازند، چالش دیگر یادگیری نحوه کارکرد Transformer نیست، بلکه یادگیری این است که کدام نوع، کدام بهینهسازی و کدام جایگزین برای وظیفه مورد نظر بهترین خدمت را ارائه میدهد.
پیام پایانی
تسلط بر این اکوسیستم چیزی است که برتری مهندسی هوش مصنوعی را در این دوران تعریف میکند. حتی در سال ۲۰۲۵، Transformer در قلب هوش مصنوعی تولیدی، پردازش زبان طبیعی و سیستمهای چندوجهی باقی میماند، اما این یک Transformer دگرگونشده است: مجهز به FlashAttention، فشردهشده با SlimAttention، مقیاسبندیشده توسط Scalable Softmax، و گاهی حتی با مدلهای سادهتر و وظیفهمحور مانند Mamba و RWKV جایگزین شده است.
آینده یادگیری عمیق در تنوع، انعطافپذیری و یکپارچگی نهفته است. ما شاهد دورانی هستیم که در آن معماریهای متفاوت نه رقیب، بلکه مکمل یکدیگرند و هر کدام بهترین کارایی را در زمینه خاص خود ارائه میدهند.