یکی از چالشهای اساسی در یادگیری ماشین، مواجهه با مجموعه دادههای نامتعادل است که در آن تعداد نمونههای یک کلاس به طور قابل توجهی کمتر از کلاسهای دیگر میباشد. این عدم تعادل باعث میشود مدلهای یادگیری ماشین به سمت کلاس اکثریت سوگیری پیدا کرده و عملکرد ضعیفی در شناسایی کلاس اقلیت داشته باشند. الگوریتم SMOTE (تکنیک نمونهبرداری بیش از حد مصنوعی اقلیت) به عنوان یکی از موثرترین روشهای مقابله با این مشکل شناخته میشود.
تعریف مسئله عدم تعادل در دادهها
عدم تعادل در دادهها زمانی رخ میدهد که توزیع کلاسها در مجموعه داده به طور یکسان نباشد. در مسائل طبقهبندی دودویی، این مشکل زمانی بروز میکند که تعداد نمونههای یک کلاس (کلاس اکثریت) به مراتب بیشتر از کلاس دیگر (کلاس اقلیت) باشد. نسبت عدم تعادل میتواند از 1:10 تا حتی 1:1000 یا بیشتر متغیر باشد.
کاربردهای واقعی مسائل نامتعادل
این مشکل در بسیاری از کاربردهای واقعی دنیا رایج است:
- تشخیص تقلب مالی: تعداد تراکنشهای کلاهبردارانه بسیار کمتر از تراکنشهای معتبر است
- تشخیص پزشکی: بیماریهای نادر نسبت به افراد سالم در اقلیت هستند
- تشخیص اسپم: ایمیلهای هرزنامه نسبت به ایمیلهای عادی کمتر هستند
- تشخیص نقص در سیستمهای صنعتی: خرابیهای دستگاه نسبت به عملکرد عادی نادر است
الگوریتم SMOTE: مفاهیم بنیادی
تاریخچه و پیشینه
الگوریتم SMOTE در سال 2002 توسط Nitesh V. Chawla، Kevin W. Bowyer، Lawrence O. Hall و W. Philip Kegelmeyer در مقالهای با عنوان “SMOTE: Synthetic Minority Over-sampling Technique” معرفی شد. این الگوریتم برای حل مشکلات نمونهبرداری تصادفی ساده طراحی شده است که باعث بیشبرازش میشود.
اصول کار SMOTE
SMOTE به جای تکرار ساده نمونههای موجود، نمونههای مصنوعی جدید برای کلاس اقلیت تولید میکند. این کار از طریق درونیابی بین نمونههای کلاس اقلیت انجام میشود.
مراحل الگوریتم SMOTE:
مرحله 1: انتخاب نمونه اقلیت
- یک نمونه از کلاس اقلیت به صورت تصادفی انتخاب میشود
2: یافتن نزدیکترین همسایگان
- با استفاده از الگوریتم k-نزدیکترین همسایه (KNN)، k همسایه نزدیک به نمونه انتخابی در فضای ویژگی پیدا میشوند
- معمولاً k=5 در نظر گرفته میشودمرحله 3: تولید نمونه مصنوعی
- یکی از k همسایه به صورت تصادفی انتخاب میشود
- نمونه مصنوعی جدید در امتداد خط بین نمونه اصلی و همسایه انتخاب شده ایجاد میشود
- فرمول تولید نمونه جدید:
x_new = x_i + λ × (x_k - x_i)
که در آن:
- x_i: نمونه اصلی از کلاس اقلیت
- x_k: یکی از k همسایه نزدیک
- λ: عدد تصادفی بین 0 و 1
- x_new: نمونه مصنوعی جدید
مرحله 4: تکرار
- این فرآیند تا رسیدن به تعادل مطلوب بین کلاسها تکرار میشود
تفاوت SMOTE با روشهای سنتی
نمونهبرداری تصادفی ساده:
- تکرار دقیق نمونههای موجود
- منجر به بیشبرازش میشود
- اطلاعات جدیدی اضافه نمیکند
SMOTE:
- ایجاد نمونههای مصنوعی جدید
- کاهش بیشبرازش
- تنوع بیشتر در دادههای آموزشی
پیادهسازی عملی SMOTE در پایتون
نصب کتابخانههای مورد نیاز
# نصب کتابخانه imbalanced-learn
pip install imbalanced-learn
# نصب کتابخانههای پایه
pip install numpy pandas scikit-learn matplotlib
مثال کامل پیادهسازی
# وارد کردن کتابخانههای مورد نیاز
import numpy as np
import pandas as pd
from collections import Counter
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.metrics import precision_score, recall_score, f1_score
from imblearn.over_sampling import SMOTE
import matplotlib.pyplot as plt
# ایجاد مجموعه داده نامتعادل
X, y = make_classification(
n_samples=10000,
n_features=20,
n_informative=15,
n_redundant=5,
n_classes=2,
weights=[0.95, 0.05], # 95% کلاس اکثریت، 5% کلاس اقلیت
random_state=42
)
# نمایش توزیع اولیه کلاسها
print("توزیع کلاسها قبل از SMOTE:")
print(Counter(y))
# خروجی: Counter({0: 9500, 1: 500})
# تقسیم داده به آموزش و آزمون
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# اعمال SMOTE فقط روی دادههای آموزشی
smote = SMOTE(
sampling_strategy='auto', # متعادلسازی کامل
k_neighbors=5,
random_state=42
)
X_train_resampled, y_train_resampled = smote.fit_resample(
X_train, y_train
)
# نمایش توزیع بعد از SMOTE
print("\nتوزیع کلاسها بعد از SMOTE:")
print(Counter(y_train_resampled))
# خروجی: Counter({0: 7600, 1: 7600})
# آموزش مدل بدون SMOTE
model_without_smote = LogisticRegression(random_state=42)
model_without_smote.fit(X_train, y_train)
y_pred_without = model_without_smote.predict(X_test)
# آموزش مدل با SMOTE
model_with_smote = LogisticRegression(random_state=42)
model_with_smote.fit(X_train_resampled, y_train_resampled)
y_pred_with = model_with_smote.predict(X_test)
# مقایسه نتایج
print("\n=== نتایج بدون SMOTE ===")
print(classification_report(y_test, y_pred_without))
print("\n=== نتایج با SMOTE ===")
print(classification_report(y_test, y_pred_with))
# محاسبه معیارهای ارزیابی
def evaluate_model(y_true, y_pred, model_name):
precision = precision_score(y_true, y_pred)
recall = recall_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)
print(f"\n{model_name}:")
print(f"دقت (Precision): {precision:.3f}")
print(f"بازخوانی (Recall): {recall:.3f}")
print(f"امتیاز F1: {f1:.3f}")
evaluate_model(y_test, y_pred_without, "مدل بدون SMOTE")
evaluate_model(y_test, y_pred_with, "مدل با SMOTE")
استفاده از SMOTE با Pipeline
برای جلوگیری از نشت داده (data leakage)، باید SMOTE را فقط روی دادههای آموزشی اعمال کنیم:
from sklearn.pipeline import Pipeline
from sklearn.model_selection import cross_val_score
# ایجاد Pipeline
pipeline = Pipeline([
('smote', SMOTE(random_state=42)),
('classifier', DecisionTreeClassifier(random_state=42))
])
# ارزیابی با اعتبارسنجی متقاطع
scores = cross_val_score(
pipeline, X_train, y_train,
cv=5, scoring='f1'
)
print(f"میانگین امتیاز F1: {scores.mean():.3f} (±{scores.std():.3f})")
معیارهای ارزیابی برای دادههای نامتعادل
چرا دقت (Accuracy) کافی نیست؟
در مجموعه دادههای نامتعادل، دقت کلی معیار مناسبی نیست. به عنوان مثال، یک مدل که همیشه کلاس اکثریت را پیشبینی کند، میتواند دقت بالایی داشته باشد اما کاملاً بیفایده باشد.
معیارهای مناسب
1. دقت (Precision)
Precision = TP / (TP + FP)
نشان میدهد از بین موارد پیشبینی شده مثبت، چند درصد واقعاً مثبت هستند.
2. بازخوانی (Recall)
Recall = TP / (TP + FN)
نشان میدهد از بین موارد واقعاً مثبت، چند درصد را شناسایی کردهایم.
3. امتیاز F1
F1 = 2 × (Precision × Recall) / (Precision + Recall)
میانگین هارمونیک دقت و بازخوانی است و تعادل بین آنها را نشان میدهد.
4. منحنی ROC و AUC
- سطح زیر منحنی ROC معیار مناسبی برای ارزیابی عملکرد کلی مدل است
- مقدار نزدیک به 1 عملکرد بهتر را نشان میدهد
5. ماتریس درهمریختگی (Confusion Matrix) نمایش کامل True Positives، True Negatives، False Positives و False Negatives
انتخاب معیار مناسب
- تشخیص تقلب: بازخوانی بالا (نباید تقلبی را از دست بدهیم)
- تشخیص اسپم: دقت بالا (نباید ایمیل معتبر را اسپم تشخیص دهیم)
- تشخیص پزشکی: F1 متعادل (هم دقت و هم بازخوانی مهم هستند)
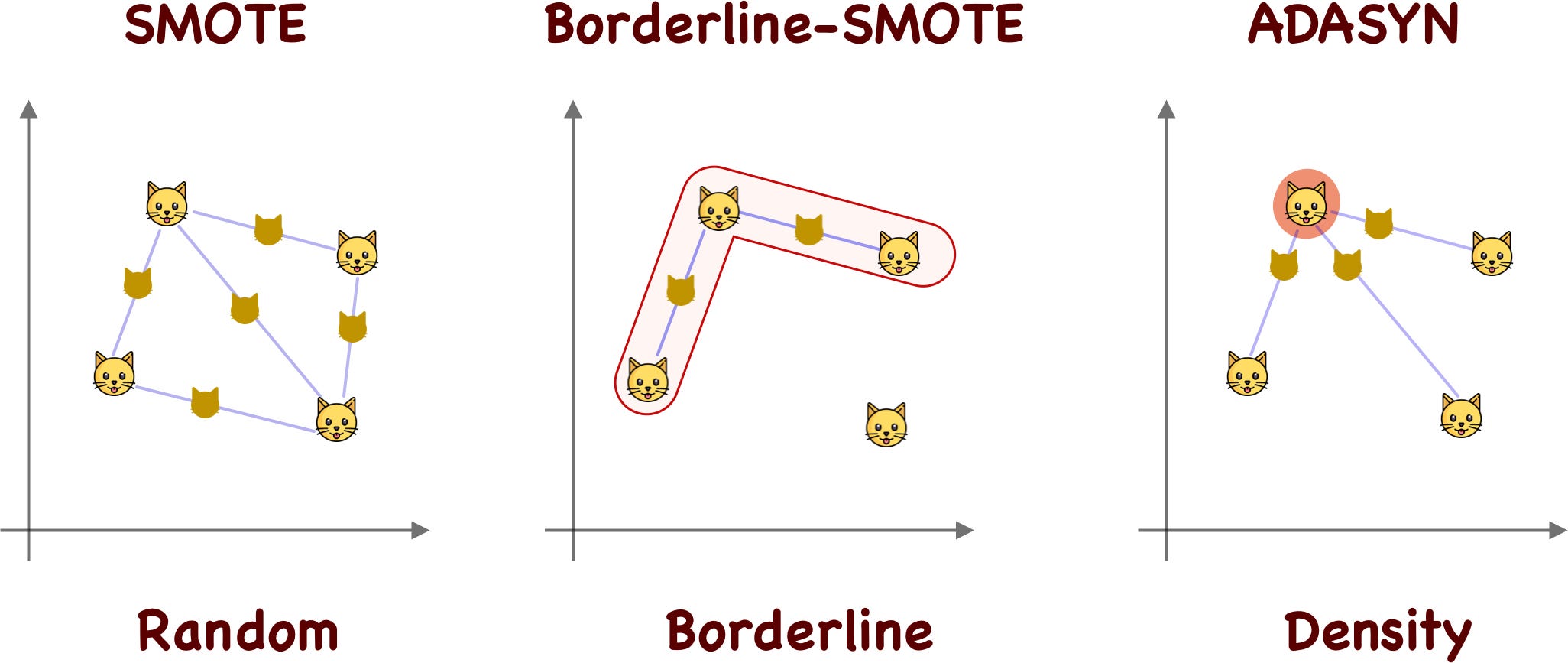
انواع بهبود یافته SMOTE
1. Borderline-SMOTE
این روش فقط روی نمونههای مرزی کلاس اقلیت تمرکز میکند که احتمال طبقهبندی نادرست آنها بیشتر است.
انواع Borderline-SMOTE:
- Borderline-SMOTE1: نمونههای مصنوعی بین نمونههای اقلیت ایجاد میکند
- Borderline-SMOTE2: نمونههای مصنوعی بین نمونههای اقلیت و اکثریت ایجاد میکند
from imblearn.over_sampling import BorderlineSMOTE
# استفاده از Borderline-SMOTE
borderline_smote = BorderlineSMOTE(
kind='borderline-1',
k_neighbors=5,
random_state=42
)
X_resampled, y_resampled = borderline_smote.fit_resample(X_train, y_train)
2. ADASYN (Adaptive Synthetic Sampling)
ADASYN به صورت تطبیقی نمونههای مصنوعی بیشتری در مناطقی تولید میکند که یادگیری آنها دشوارتر است.
ویژگیهای ADASYN:
- توزیع چگالی را در نظر میگیرد
- در مناطق با چگالی کم، نمونههای بیشتری تولید میکند
- مرز تصمیمگیری را به سمت نمونههای دشوار منتقل میکند
from imblearn.over_sampling import ADASYN
adasyn = ADASYN(
n_neighbors=5,
random_state=42
)
X_resampled, y_resampled = adasyn.fit_resample(X_train, y_train)
3. SMOTE-NC (Nominal Continuous)
برای مجموعه دادههایی که ترکیبی از ویژگیهای پیوسته و گسسته دارند.
from imblearn.over_sampling import SMOTENC
# مشخص کردن ایندکس ویژگیهای گسسته
categorical_features = [0, 3, 5]
smote_nc = SMOTENC(
categorical_features=categorical_features,
random_state=42
)
X_resampled, y_resampled = smote_nc.fit_resample(X_train, y_train)
4. SMOTE-Tomek
ترکیبی از SMOTE و Tomek Links که پس از نمونهبرداری بیش از حد، نمونههای همپوشان را حذف میکند.
from imblearn.combine import SMOTETomek
smote_tomek = SMOTETomek(random_state=42)
X_resampled, y_resampled = smote_tomek.fit_resample(X_train, y_train)
5. K-Means SMOTE
از خوشهبندی K-Means برای شناسایی مناطق پراکنده و تولید نمونه در آن مناطق استفاده میکند.
from imblearn.over_sampling import KMeansSMOTE
kmeans_smote = KMeansSMOTE(
kmeans_estimator=5,
k_neighbors=5,
random_state=42
)
X_resampled, y_resampled = kmeans_smote.fit_resample(X_train, y_train)
مزایا و محدودیتهای SMOTE
مزایای SMOTE
1. بهبود عملکرد مدل
- افزایش توانایی مدل در شناسایی کلاس اقلیت
- بهبود متریکهای بازخوانی و F1
2. کاهش بیشبرازش
- با ایجاد نمونههای متنوع، بیشبرازش کاهش مییابد
- مدل بهتر تعمیم مییابد
3. انعطافپذیری
- قابل تنظیم برای نسبتهای مختلف متعادلسازی
- سازگار با اکثر الگوریتمهای یادگیری ماشین
4. سهولت پیادهسازی
- کتابخانههای آماده در پایتون و R
- مستندات کامل و جامعه فعال
محدودیتهای SMOTE
1. مشکل در فضاهای با ابعاد بالا
- در دادههای با ابعاد بالا، فاصله اقلیدسی معنای خود را از دست میدهد
- نمونههای مصنوعی ممکن است واقعگرایانه نباشند
2. نادیده گرفتن کلاس اکثریت
- SMOTE فقط کلاس اقلیت را در نظر میگیرد
- ممکن است نمونههای مصنوعی در مناطق همپوشانی ایجاد شود
3. افزایش نویز
- اگر داده اصلی حاوی نویز باشد، نمونههای مصنوعی نیز نویزی خواهند بود
- در مناطق با همپوشانی کلاس، مشکلساز است
4. هزینه محاسباتی
- الگوریتم KNN برای یافتن همسایگان زمانبر است
- برای مجموعه دادههای بزرگ میتواند کند باشد
5. حساسیت به پارامتر k
- انتخاب نادرست k میتواند به نتایج ضعیف منجر شود
- نیاز به تنظیم دقیق پارامترها
6. محدودیت در متغیرهای گسسته
- SMOTE اصلی فقط برای متغیرهای پیوسته مناسب است
- نیاز به انواع خاص مانند SMOTE-NC برای دادههای مختلط
بهترین شیوههای کاری (Best Practices)
1. زمان اعمال SMOTE
انجام دهید:
- SMOTE را فقط روی دادههای آموزشی اعمال کنید
- از Pipeline استفاده کنید تا از نشت داده جلوگیری شود
انجام ندهید:
- SMOTE را روی کل مجموعه داده قبل از تقسیم اعمال نکنید
- SMOTE را روی دادههای آزمون اعمال نکنید
2. تنظیم پارامترها
# آزمایش مقادیر مختلف k
for k in [3, 5, 7, 10]:
smote = SMOTE(k_neighbors=k, random_state=42)
X_res, y_res = smote.fit_resample(X_train, y_train)
model = LogisticRegression(random_state=42)
model.fit(X_res, y_res)
score = f1_score(y_test, model.predict(X_test))
print(f"k={k}: F1-Score = {score:.3f}")
3. پیشپردازش داده
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
# ترکیب استانداردسازی با SMOTE
pipeline = Pipeline([
('scaler', StandardScaler()),
('smote', SMOTE(random_state=42)),
('classifier', LogisticRegression(random_state=42))
])
pipeline.fit(X_train, y_train)
4. ترکیب با سایر تکنیکها
# ترکیب SMOTE با نمونهبرداری کمتر (Undersampling)
from imblearn.combine import SMOTEENN
smote_enn = SMOTEENN(random_state=42)
X_resampled, y_resampled = smote_enn.fit_resample(X_train, y_train)
5. حذف نویز قبل از SMOTE
from sklearn.neighbors import LocalOutlierFactor
# شناسایی و حذف نویز
lof = LocalOutlierFactor()
mask = lof.fit_predict(X_train) == 1
X_train_clean = X_train[mask]
y_train_clean = y_train[mask]
# سپس SMOTE را اعمال کنید
smote = SMOTE(random_state=42)
X_resampled, y_resampled = smote.fit_resample(X_train_clean, y_train_clean)
موارد استفاده واقعی
مطالعه موردی 1: تشخیص تقلب کارت اعتباری
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
# بارگذاری داده
# فرض: دادهای با 99.8% تراکنش معتبر و 0.2% تقلب
# اعمال SMOTE با نسبت سفارشی
smote = SMOTE(sampling_strategy=0.5, random_state=42) # تعادل 50%
X_resampled, y_resampled = smote.fit_resample(X_train, y_train)
# آموزش مدل Random Forest
model = RandomForestClassifier(
n_estimators=100,
class_weight='balanced',
random_state=42
)
model.fit(X_resampled, y_resampled)
# ارزیابی با تمرکز بر Recall
y_pred = model.predict(X_test)
print(f"Recall: {recall_score(y_test, y_pred):.3f}")
مطالعه موردی 2: تشخیص بیماری
# استفاده از ADASYN برای دادههای پزشکی
from imblearn.over_sampling import ADASYN
adasyn = ADASYN(n_neighbors=5, random_state=42)
X_resampled, y_resampled = adasyn.fit_resample(X_train, y_train)
# مدل با وزندهی کلاس
from sklearn.svm import SVC
model = SVC(
kernel='rbf',
class_weight='balanced',
probability=True,
random_state=42
)
model.fit(X_resampled, y_resampled)
جایگزینهای SMOTE
1. نمونهبرداری کمتر (Undersampling)
from imblearn.under_sampling import RandomUnderSampler
rus = RandomUnderSampler(random_state=42)
X_resampled, y_resampled = rus.fit_resample(X_train, y_train)
2. یادگیری حساس به هزینه (Cost-Sensitive Learning)
from sklearn.ensemble import RandomForestClassifier
# تعریف وزن کلاسها
class_weights = {0: 1, 1: 10} # کلاس اقلیت 10 برابر مهمتر
model = RandomForestClassifier(
class_weight=class_weights,
random_state=42
)
model.fit(X_train, y_train)
3. روشهای مبتنی بر Ensemble
from imblearn.ensemble import BalancedRandomForestClassifier
model = BalancedRandomForestClassifier(
n_estimators=100,
random_state=42
)
model.fit(X_train, y_train)
مقایسه تجربی روشهای مختلف
کد کامل مقایسه
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.tree import DecisionTreeClassifier
from imblearn.over_sampling import SMOTE, BorderlineSMOTE, ADASYN
from imblearn.under_sampling import RandomUnderSampler
from imblearn.combine import SMOTEENN
# ایجاد داده نامتعادل
X, y = make_classification(
n_samples=5000,
n_features=20,
n_classes=2,
weights=[0.95, 0.05],
random_state=42
)
# تعریف روشهای مختلف
methods = {
'بدون متعادلسازی': None,
'SMOTE': SMOTE(random_state=42),
'Borderline-SMOTE': BorderlineSMOTE(random_state=42),
'ADASYN': ADASYN(random_state=42),
'SMOTE-ENN': SMOTEENN(random_state=42),
'Random Undersampling': RandomUnderSampler(random_state=42)
}
# ارزیابی هر روش
results = {}
for name, method in methods.items():
if method is None:
X_res, y_res = X, y
else:
X_res, y_res = method.fit_resample(X, y)
clf = DecisionTreeClassifier(random_state=42)
# محاسبه F1-Score با اعتبارسنجی متقاطع
scores = cross_val_score(
clf, X_res, y_res,
cv=5, scoring='f1'
)
results[name] = {
'میانگین F1': scores.mean(),
'انحراف معیار': scores.std(),
'تعداد نمونه': len(y_res)
}
print(f"{name}:")
print(f" F1-Score: {scores.mean():.3f} (±{scores.std():.3f})")
print(f" تعداد نمونه: {len(y_res)}")
print()
# نمایش بهترین روش
best_method = max(results.items(), key=lambda x: x[1]['میانگین F1'])
print(f"بهترین روش: {best_method[0]} با F1-Score: {best_method[1]['میانگین F1']:.3f}")
بحث و انتقادات علمی
انتقادات اصلی به SMOTE
1. تغییر توزیع احتمال محققانی چون Christoph Molnar استدلال میکنند که این الگوریتم توزیع اصلی داده را تغییر میدهد و این میتواند منجر به مدلهای نادرست کالیبره شود.
2. عملکرد ضعیف در دادههای با ابعاد بالا مطالعات نشان دادهاند که در فضاهای با ابعاد بالا، نمونههای مصنوعی SMOTE به نمونههای تست نزدیکتر از نمونههای اصلی اقلیت هستند، که میتواند تصمیمگیری را تحت تأثیر قرار دهد.
3. عدم استفاده در مسابقات Kaggle جالب است که این الگوریتم به ندرت در راهحلهای برنده مسابقات Kaggle استفاده میشود. دلایل احتمالی:
- ایجاد داده مصنوعی لزوماً اطلاعات جدید اضافه نمیکند
- روشهایی مانند class weighting سادهتر و مؤثرتر هستند
- خطر data leakage در صورت استفاده نادرست
پاسخ به انتقادات
دفاع از SMOTE:
- در بسیاری از مطالعات علمی، این الگوریتم بهبود قابل توجهی در معیارهای ارزیابی نشان داده است
- برای دادههای با ابعاد پایین تا متوسط، همچنان مؤثر است
- انواع بهبود یافته آن مانند Borderline-SMOTE و ADASYN بسیاری از محدودیتها را برطرف کردهاند
توصیهها:
- SMOTE را به عنوان یک ابزار در کنار سایر روشها استفاده کنید
- همیشه عملکرد را با روشهای جایگزین مقایسه کنید
- از اعتبارسنجی دقیق و معیارهای مناسب استفاده کنید
تحقیقات و پیشرفتهای اخیر
الگوریتمهای نوین
1. ISMOTE (Improved SMOTE) یک الگوریتم بهبود یافته که فضای تولید نمونه را گسترش میدهد و ویژگیهای چگالی و توزیع محلی را در نظر میگیرد.
2. G-SMOTE (Geometric SMOTE) به جای درونیابی خطی، از مناطق هندسی (کرهها یا بیضیها) برای تولید نمونه استفاده میکند.
3. Deep Learning و SMOTE استفاده از شبکههای عصبی مولد (GANs) برای تولید نمونههای مصنوعی واقعگرایانهتر.
جهتهای تحقیقاتی آینده
- SMOTE برای دادههای Big Data: الگوریتمهای مقیاسپذیر برای مجموعه دادههای بزرگ
- SMOTE برای دادههای غیرساختاری: تصویر، متن و صوت
- یادگیری انتقالی: استفاده از دانش دامنههای دیگر
- SMOTE تطبیقی: تنظیم خودکار پارامترها بر اساس ویژگیهای داده
راهنمای گام به گام برای پروژه واقعی
گام 1: تحلیل داده
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# بارگذاری داده
df = pd.read_csv('your_data.csv')
# بررسی توزیع کلاسها
class_distribution = df['target'].value_counts()
print("توزیع کلاسها:")
print(class_distribution)
print(f"\nنسبت عدم تعادل: 1:{class_distribution[0]/class_distribution[1]:.2f}")
# تصویرسازی
plt.figure(figsize=(8, 5))
class_distribution.plot(kind='bar')
plt.title('توزیع کلاسهای هدف')
plt.xlabel('کلاس')
plt.ylabel('تعداد')
plt.show()
2: انتخاب روش مناسب
def select_resampling_method(imbalance_ratio, n_features, n_samples):
"""
انتخاب روش متعادلسازی بر اساس ویژگیهای داده
"""
if imbalance_ratio < 5:
return "نیازی به متعادلسازی نیست، از class_weight استفاده کنید"
elif imbalance_ratio < 20 and n_features < 50:
return "SMOTE"
elif imbalance_ratio < 20 and n_features >= 50:
return "Borderline-SMOTE یا ADASYN"
elif imbalance_ratio >= 20:
return "ترکیب SMOTE با Undersampling"
return "SMOTE"
# محاسبه نسبت عدم تعادل
ir = class_distribution[0] / class_distribution[1]
recommendation = select_resampling_method(ir, X.shape[1], X.shape[0])
print(f"توصیه: {recommendation}")
3: پیادهسازی و ارزیابی
from sklearn.model_selection import StratifiedKFold
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, roc_auc_score
def evaluate_with_cv(X, y, method, n_splits=5):
"""
ارزیابی با اعتبارسنجی متقاطع
"""
skf = StratifiedKFold(n_splits=n_splits, shuffle=True, random_state=42)
scores = {
'f1': [],
'recall': [],
'precision': [],
'roc_auc': []
}
for train_idx, test_idx in skf.split(X, y):
X_train_fold, X_test_fold = X[train_idx], X[test_idx]
y_train_fold, y_test_fold = y[train_idx], y[test_idx]
# اعمال SMOTE
if method is not None:
X_train_fold, y_train_fold = method.fit_resample(
X_train_fold, y_train_fold
)
# آموزش مدل
clf = RandomForestClassifier(random_state=42)
clf.fit(X_train_fold, y_train_fold)
# پیشبینی
y_pred = clf.predict(X_test_fold)
y_pred_proba = clf.predict_proba(X_test_fold)[:, 1]
# محاسبه معیارها
scores['f1'].append(f1_score(y_test_fold, y_pred))
scores['recall'].append(recall_score(y_test_fold, y_pred))
scores['precision'].append(precision_score(y_test_fold, y_pred))
scores['roc_auc'].append(roc_auc_score(y_test_fold, y_pred_proba))
# میانگین نتایج
return {k: np.mean(v) for k, v in scores.items()}
# مقایسه روشها
methods_to_test = {
'بدون SMOTE': None,
'SMOTE': SMOTE(random_state=42),
'ADASYN': ADASYN(random_state=42)
}
for name, method in methods_to_test.items():
print(f"\n=== {name} ===")
results = evaluate_with_cv(X, y, method)
for metric, value in results.items():
print(f"{metric}: {value:.3f}")
4: تنظیم دقیق و بهینهسازی
from sklearn.model_selection import GridSearchCV
# تنظیم پارامترهای SMOTE و مدل با هم
param_grid = {
'smote__k_neighbors': [3, 5, 7],
'smote__sampling_strategy': [0.5, 0.75, 1.0],
'classifier__max_depth': [10, 20, None],
'classifier__n_estimators': [50, 100, 200]
}
pipeline = Pipeline([
('smote', SMOTE(random_state=42)),
('classifier', RandomForestClassifier(random_state=42))
])
grid_search = GridSearchCV(
pipeline,
param_grid,
cv=5,
scoring='f1',
n_jobs=-1,
verbose=1
)
grid_search.fit(X_train, y_train)
print("بهترین پارامترها:")
print(grid_search.best_params_)
print(f"\nبهترین امتیاز F1: {grid_search.best_score_:.3f}")
نتیجهگیری
خلاصه یافتهها
الگوریتم SMOTE یکی از پرکاربردترین و مؤثرترین روشهای مقابله با عدم تعادل دادهها است. این الگوریتم با تولید نمونههای مصنوعی برای کلاس اقلیت، امکان آموزش بهتر مدلهای یادگیری ماشین را فراهم میکند.
نکات کلیدی:
- این الگوریتم برای دادههای با ابعاد پایین تا متوسط و نسبت عدم تعادل متوسط بسیار مؤثر است
- باید همیشه فقط روی دادههای آموزشی اعمال شود
- انتخاب معیارهای ارزیابی مناسب (F1، Recall، Precision) حیاتی است
- انواع بهبود یافته مانند Borderline-SMOTE و ADASYN میتوانند عملکرد بهتری داشته باشند
چشمانداز آینده
با پیشرفت هوش مصنوعی و یادگیری عمیق، انتظار میرود روشهای جدیدتر و هوشمندتری برای مقابله با عدم تعادل دادهها توسعه یابند. استفاده از شبکههای عصبی مولد (GANs) و روشهای یادگیری انتقالی میتوانند راهحلهای نوینی ارائه دهند.
منابع آموزشی تکمیلی
- مستندات رسمی imbalanced-learn
- آموزشهای Machine Learning Mastery
- دورههای Coursera و edX در زمینه یادگیری ماشین
- مقالات و آموزشهای GeeksforGeeks و Towards Data Science
کدهای نمونه
تمامی کدهای این مقاله در مخزن GitHub زیر در دسترس است:
https://github.com/imbalanced-learn/imbalanced-learn