در زمینه یادگیری عمیق (Deep Learning)، همیشه دسترسی به دادههای انبوه برای هر کلاس امکانپذیر نیست. شبکههای عصبی Siamese یا دوقلو، پاسخی قدرتمند به چالش یادگیری با نمونههای کم (Few-Shot Learning) هستند. این مقاله به بررسی تخصصی معماری شبکههای Siamese، ریاضیات پشت توابع هزینه Contrastive و Triplet، و نحوه آموزش آنها برای تشخیص شباهت معنایی در تصاویر و متون میپردازد.
۱. مقدمه: چرا طبقهبندی سنتی کافی نیست؟
در روشهای کلاسیک یادگیری ماشین، برای اینکه یک مدل بتواند چهره یک فرد خاص یا امضای او را تشخیص دهد، نیاز به هزاران تصویر از آن فرد دارد. اما در دنیای واقعی، سیستمهای امنیتی یا بانکی ممکن است تنها یک نمونه از تصویر یا امضای کاربر را در اختیار داشته باشند. اینجاست که شبکههای عصبی استاندارد (مانند CNNهای معمولی) با شکست مواجه میشوند.
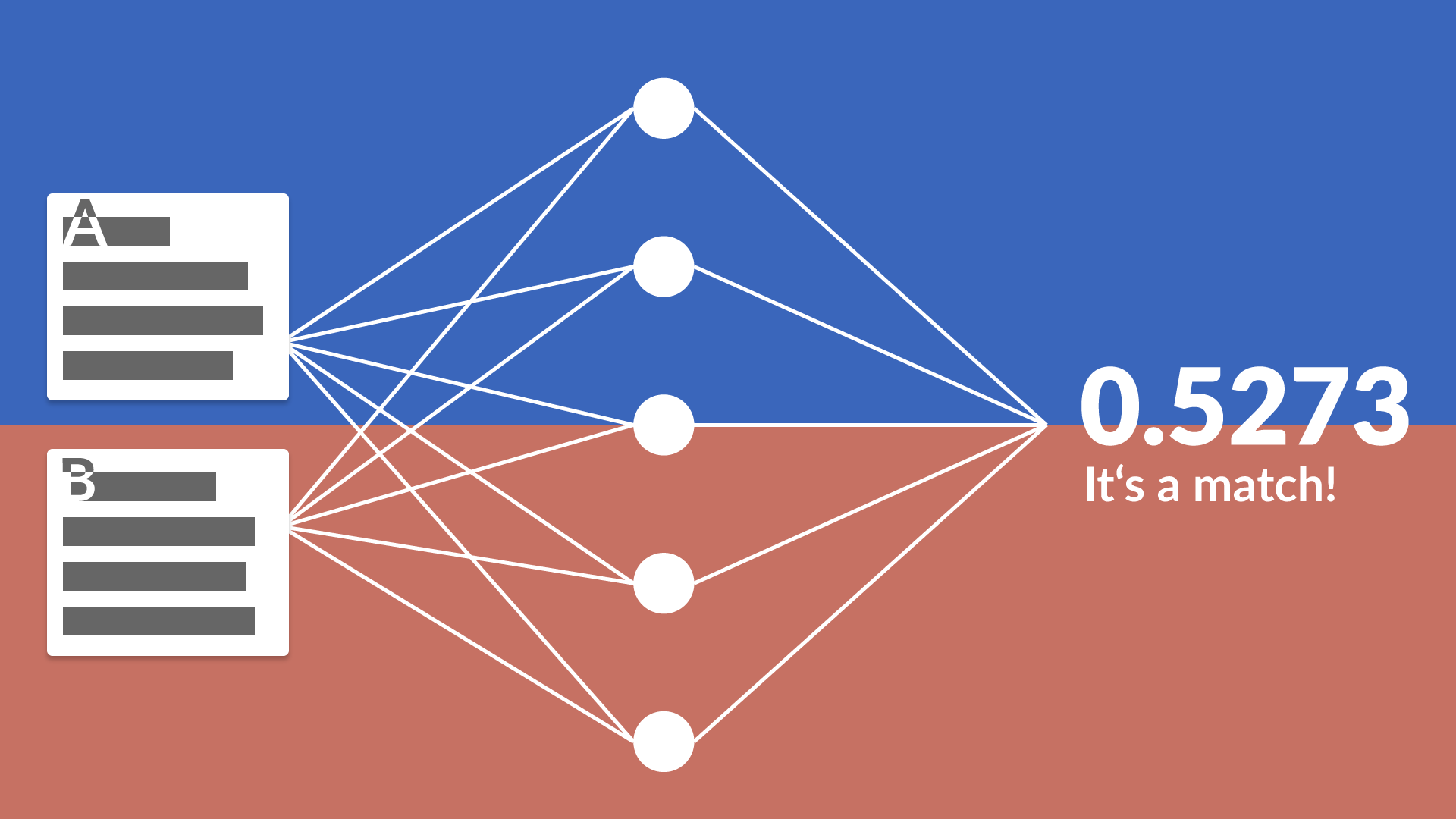
شبکههای Siamese رویکرد مسئله را تغییر میدهند: به جای اینکه بپرسند «این تصویر متعلق به چه کلاسی است؟»، میپرسند «این دو تصویر چقدر به هم شباهت دارند؟». این تغییر پارادایم، امکان پیادهسازی سیستمهای One-Shot Learning را فراهم میکند.
۲. معماری شبکههای Siamese (شبکههای دوقلو)
اصطلاح “Siamese” از دوقلوهای به هم چسبیده گرفته شده است. در یادگیری ماشین، این معماری شامل دو زیرشبکه (Sub-network) کاملاً یکسان است.
۲.۱. ویژگیهای کلیدی معماری
دو ویژگی حیاتی این شبکهها را از سایر معماریها متمایز میکند:
وزنهای مشترک (Shared Weights): هر دو زیرشبکه دارای پارامترها، وزنها و بایاسهای دقیقاً یکسانی هستند. اگر وزنهای شبکه اول در طی فرآیند Backpropagation بهروز شود، وزنهای شبکه دوم نیز دقیقاً به همان صورت تغییر میکند. این تضمین میکند که دو تصویر بسیار مشابه، توسط یک فضای ویژگی یکسان پردازش شوند.
فضای تعبیه (Embedding Space): هدف زیرشبکهها تبدیل دادههای ورودی (مانند تصویر خام) به یک بردار ویژگی فشرده (Vector) در فضایی با ابعاد پایین است.
۲.۲. فرآیند پردازش (Forward Pass)
فرض کنید دو ورودی $X_1$ و $X_2$ داریم.
شبکه این ورودیها را پردازش کرده و دو بردار ویژگی $G(X_1)$ و $G(X_2)$ تولید میکند.
سپس فاصله بین این دو بردار محاسبه میشود. اگر فاصله کم باشد، ورودیها مشابه و اگر زیاد باشد، متفاوت هستند.
۳. ریاضیات و توابع فاصله (Distance Metrics)
برای آموزش شبکه جهت تشخیص شباهت، باید بتوانیم فاصله بین بردارهای خروجی را کمیسازی کنیم. رایجترین معیار، فاصله اقلیدسی (Euclidean Distance) است:
در برخی کاربردها (بهویژه در پردازش متن)، از شباهت کسینوسی (Cosine Similarity) نیز استفاده میشود که زاویه بین دو بردار را اندازه میگیرد، نه طول آنها را.
۴. توابع هزینه (Loss Functions): قلب تپنده آموزش
انتخاب تابع هزینه مناسب، مهمترین بخش در آموزش شبکههای Siamese است. دو تابع هزینه اصلی در این حوزه وجود دارد: Contrastive Loss و Triplet Loss.
۴.۱. تابع هزینه Contrastive Loss
این تابع هزینه توسط «یان لیکان» (Yann LeCun) معرفی شد و بر روی جفت دادهها کار میکند.
فرض کنید $Y$ برچسب داده باشد:
اگر دو تصویر متعلق به یک کلاس باشند (مشابه)، $Y=0$.
اگر دو تصویر متفاوت باشند، $Y=1$.
فرمول ریاضی آن به صورت زیر است:
تفسیر: اگر تصاویر مشابه باشند (بخش اول فرمول)، شبکه تلاش میکند فاصله ($D$) را به صفر برساند. اگر تصاویر متفاوت باشند (بخش دوم فرمول)، شبکه تلاش میکند فاصله را حداقل به اندازه مارجین $m$ افزایش دهد.
نکته فنی: پارامتر $m$ (Margin) بسیار حیاتی است. این پارامتر تعیین میکند که شبکه تا چه حد باید نمونههای غیرمشابه را از هم دور کند. بدون $m$، شبکه ممکن است یاد نگیرد که نمونههای مختلف را به اندازه کافی از هم جدا کند.
۴.۲. تابع هزینه Triplet Loss
این روش که توسط گوگل در مدل FaceNet محبوب شد، قدرتمندتر اما پیچیدهتر است. در اینجا به جای جفت، با سه ورودی سر و کار داریم:
Anchor (A): تصویر پایه.
Positive (P): تصویری مشابه با Anchor.
Negative (N): تصویری متفاوت با Anchor.
هدف آموزش این است که فاصله بین $A$ و $P$ کمتر از فاصله بین $A$ و $N$ باشد:
فرمول تابع هزینه Triplet Loss:
۵. استراتژیهای آموزش و چالشها
آموزش شبکههای Siamese دشوارتر از شبکههای معمولی است. دلیل اصلی آن نامتوازن بودن دادههاست (تعداد جفتهای غیرمشابه بسیار بیشتر از جفتهای مشابه است).
۵.۱. انتخاب جفتها و دادهکاوی سخت (Hard Mining)
اگر بهصورت تصادفی جفتها یا تریپلتها را انتخاب کنید، مدل به سرعت یاد میگیرد زیرا اکثر جفتهای غیرمشابه “آسان” هستند (مثلاً تفاوت تصویر فیل و ماشین کاملاً واضح است). این باعث میشود گرادیانها به صفر میل کنند و یادگیری متوقف شود.
برای حل این مشکل از تکنیک Hard Triplet Mining استفاده میشود:
Hard Positives: پیدا کردن نمونههای مشابهی که شبکه به اشتباه آنها را دور از هم قرار میدهد.
Hard Negatives: پیدا کردن نمونههای متفاوتی که شبکه به اشتباه آنها را شبیه به هم میبیند (مثلاً دو چهره متفاوت که هر دو عینک دارند).
| نوع استراتژی | توضیحات | مزایا/معایب |
| Batch Random | انتخاب تصادفی جفتها | همگرایی سریع در ابتدا، اما دقت نهایی پایین |
| Batch Hard | انتخاب سختترین نمونهها در هر Batch | همگرایی کندتر اما بسیار دقیقتر |
| Semi-Hard | انتخاب نمونههایی که کمی اشتباه هستند | تعادل مناسب بین سرعت و دقت |
۵.۲. نرمالسازی (Normalization)
بسیار مهم است که بردارهای خروجی (Embedding Vectors) نرمال شوند (معمولاً L2 Normalization). اگر بردارها نرمال نشوند، شبکه ممکن است سعی کند با بزرگ کردن طول بردارها، فاصله را به طور مصنوعی زیاد کند که باعث ناپایداری در آموزش میشود.
۶. کاربردهای عملی در صنعت
شبکههای Siamese فراتر از تشخیص چهره کاربرد دارند. در اینجا به برخی از مهمترین کاربردها اشاره میکنیم:
تایید هویت بیومتریک: تشخیص امضا، اثر انگشت و چهره (مانند FaceID).
سیستمهای توصیهگر (Recommender Systems): یافتن کالاهای مشابه در فروشگاههای آنلاین (مثلاً پیشنهاد لباسی که شبیه به عکس آپلود شده کاربر است).
پردازش زبان طبیعی (NLP): تشخیص شباهت معنایی جملات (STS). برای مثال در سیستمهای پشتیبانی مشتری، برای یافتن سوالات تکراری کاربران.
تشخیص ناهنجاری (Anomaly Detection): در خطوط تولید صنعتی، شبکه میتواند یاد بگیرد قطعات “سالم” چه شکلی هستند. هر قطعهای که فاصلهی زیادی با نمونههای سالم داشته باشد، معیوب تلقی میشود.
۷. نتیجهگیری و آینده پژوهش
شبکههای Siamese پل ارتباطی میان یادگیری عمیق و محیطهایی با دادههای محدود هستند. با استفاده از اشتراک وزنها و انتقال مسئله از «طبقهبندی» به «سنجش فاصله»، این شبکهها قابلیت تعمیمپذیری (Generalization) فوقالعادهای دارند.
تحقیقات اخیر به سمت ترکیب این شبکهها با یادگیری خود-نظارتی (Self-Supervised Learning) مانند معماریهای SimCLR و MoCo حرکت کرده است که نیاز به دادههای برچسبدار را بیش از پیش کاهش میدهد. برای پیادهسازی موفق، تمرکز بر روی استراتژی انتخاب دادهها (Data Mining) و تنظیم دقیق پارامتر Margin در تابع هزینه، کلید موفقیت است.