در AvalAI، ما به شفافیت کامل و ارائه عملکرد در سطح سازمانی به کاربران خود متعهدیم. هدف ما ارائه یک API قدرتمند و یکپارچه است که نه تنها دسترسی به طیف وسیعی از مدلهای هوش مصنوعی را ساده میکند، بلکه عملکردی رقابتی و در بسیاری موارد، برتر ارائه میدهد. این تعهد شامل مدل قیمتگذاری ما نیز میشود—ما ۱۰۰٪ با نرخهای پایه ارائهدهندگان خود همسو هستیم و هیچ سودی از خدمات اصلی آنها نمیبریم.
این صفحه نگاهی دقیق و صادقانه به عملکرد API ما، با تمرکز بر مقایسه تأخیر با استفاده مستقیم از ارائهدهندگان، ارائه میدهد.
تأثیر حفاظهای امنیتی (Guardrails)
برای اطمینان از یک مقایسه منصفانه و عادلانه، تمامی تستهای بنچمارک در این صفحه با ویژگی حفاظ امنیتی (Guardrail) غیرفعال انجام شدهاند.
حفاظ امنیتی AvalAI یک ویژگی امنیتی قدرتمند است که به طور خودکار دادههای حساس (مانند کلیدهای API و رمزهای عبور) را در درخواستهای شما شناسایی و حذف میکند. در حالی که ما اکیداً توصیه میکنیم این ویژگی را برای اکثر برنامهها فعال نگه دارید، این لایه امنیتی تأخیر جزئی در حدود ۲۰۰ تا ۳۰۰ میلیثانیه را به همراه دارد. با غیرفعال کردن آن برای این تستها، میتوانیم اندازهگیری خالصی از عملکرد زیرساخت اصلی خود ارائه دهیم.
کاربران میتوانند بر اساس نیازهای برنامه خود، بین حداکثر سرعت یا امنیت پیشرفته یکی را انتخاب کنند.
بررسی دقیق تأخیر منطقهای
تأخیر یک عدد ثابت نیست؛ بلکه به شدت تحت تأثیر موقعیت جغرافیایی کاربر و مرکز داده قرار دارد. برای ارائه تصویری واضح، ما تستهایی را از دو منطقه متمایز که کاربران ما در آنجا متمرکز هستند، انجام دادهایم.
عملکرد مرکز داده اروپا (EU)
این تست از یک ماشین مجازی میزبان در یک مرکز داده Azure در اتحادیه اروپا انجام شد و عملکرد AvalAI را با فراخوانی مستقیم API OpenAI از همان مکان مقایسه کرد.
محیط تست:
- مدل:
gpt-4o-mini - ارائهدهنده ابری: Microsoft Azure
- مکان: اروپا
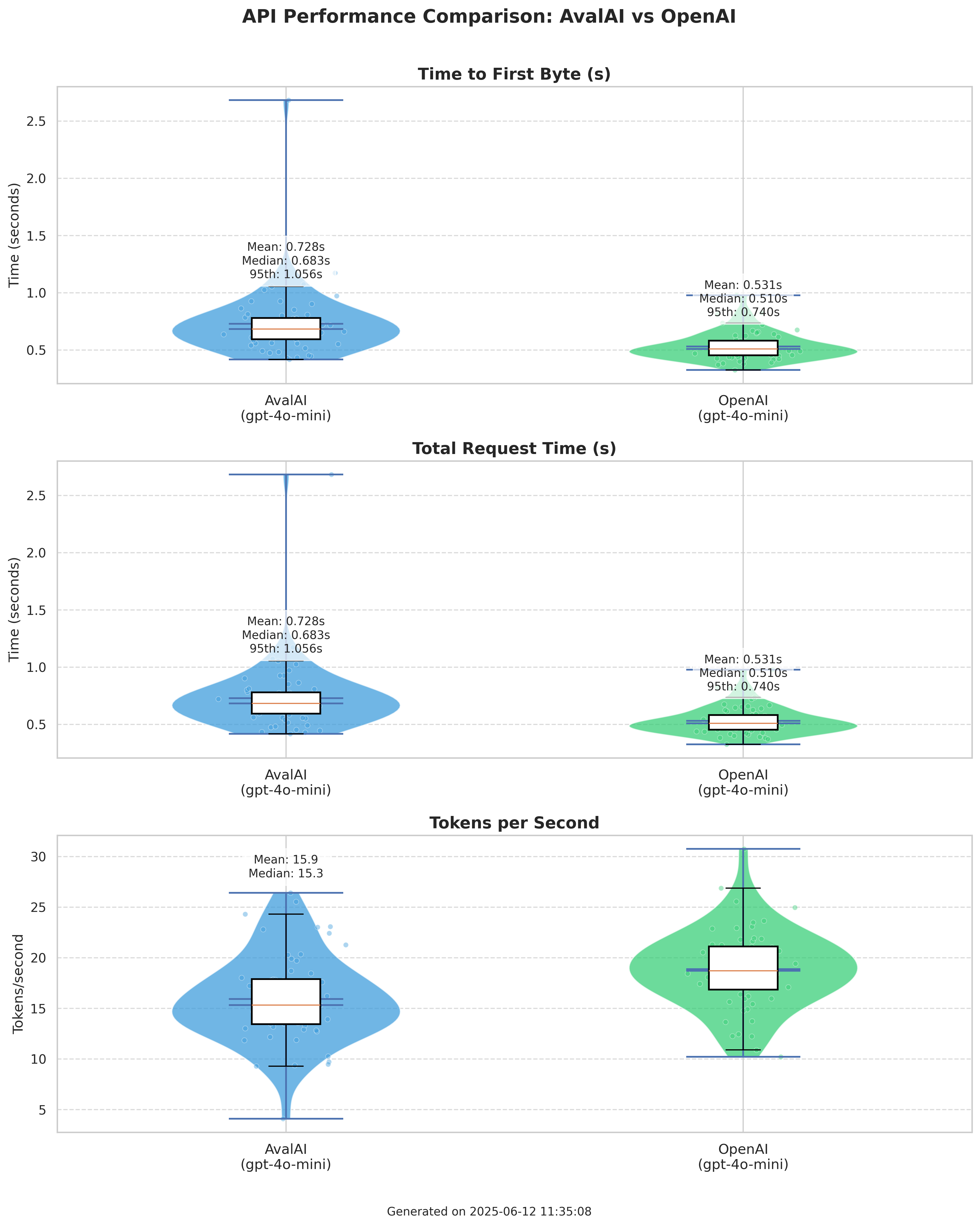
نتایج عملکرد اروپا
| معیار | AvalAI (gpt-4o-mini) | OpenAI (gpt-4o-mini) |
|---|---|---|
| میانگین TTFB (ثانیه) | 0.728 | 0.531 |
| میانه TTFB (ثانیه) | 0.683 | 0.510 |
| صدک ۹۵ TTFB (ثانیه) | 1.056 | 0.740 |
| میانگین توکن در ثانیه | 15.9 | 18.9 |
| نرخ موفقیت | 100.00% | 100.00% |
تحلیل
در مرکز داده ما در اتحادیه اروپا، AvalAI تأخیر جزئی در حدود ۲۰۰ میلیثانیه نسبت به فراخوانی مستقیم OpenAI اضافه میکند. این امر قابل پیشبینی است، زیرا سرورهای OpenAI عمدتاً بر روی Azure میزبانی میشوند که کمترین تأخیر ممکن را هنگام دسترسی از یک مرکز داده Azure برای آنها فراهم میکند. سربار جزئی در سمت AvalAI نتیجه مستقیم خدمات ارزش افزودهای است که ما ارائه میدهیم، مانند مسیریابی API یکپارچه، لایههای امنیتی قوی و پشتیبانی از چند ارائهدهنده. برای برنامههایی که دسترسی یکپارچه و انعطافپذیری کلیدی است، این تفاوت کوچک، سادهسازی قابل توجهی در توسعه را فراهم میکند.
عملکرد مرکز داده خاورمیانه (ME)
این تست از یک ماشین مجازی میزبان در یک مرکز داده Arvancloud در خاورمیانه انجام شد و عملکرد AvalAI را با فراخوانی مستقیم API OpenAI از همان مکان مقایسه کرد.
محیط تست:
- مدل:
gpt-4o-mini - ارائهدهنده ابری: Arvancloud
- مکان: خاورمیانه
نتایج عملکرد خاورمیانه
| معیار | AvalAI (gpt-4o-mini) | OpenAI (gpt-4o-mini) |
|---|---|---|
| میانگین TTFB (ثانیه) | 0.993 | 1.095 |
| میانه TTFB (ثانیه) | 0.929 | 0.951 |
| صدک ۹۵ TTFB (ثانیه) | 1.479 | 1.386 |
| میانگین توکن در ثانیه | 11.4 | 9.6 |
| نرخ موفقیت | 100.00% | 100.00% |
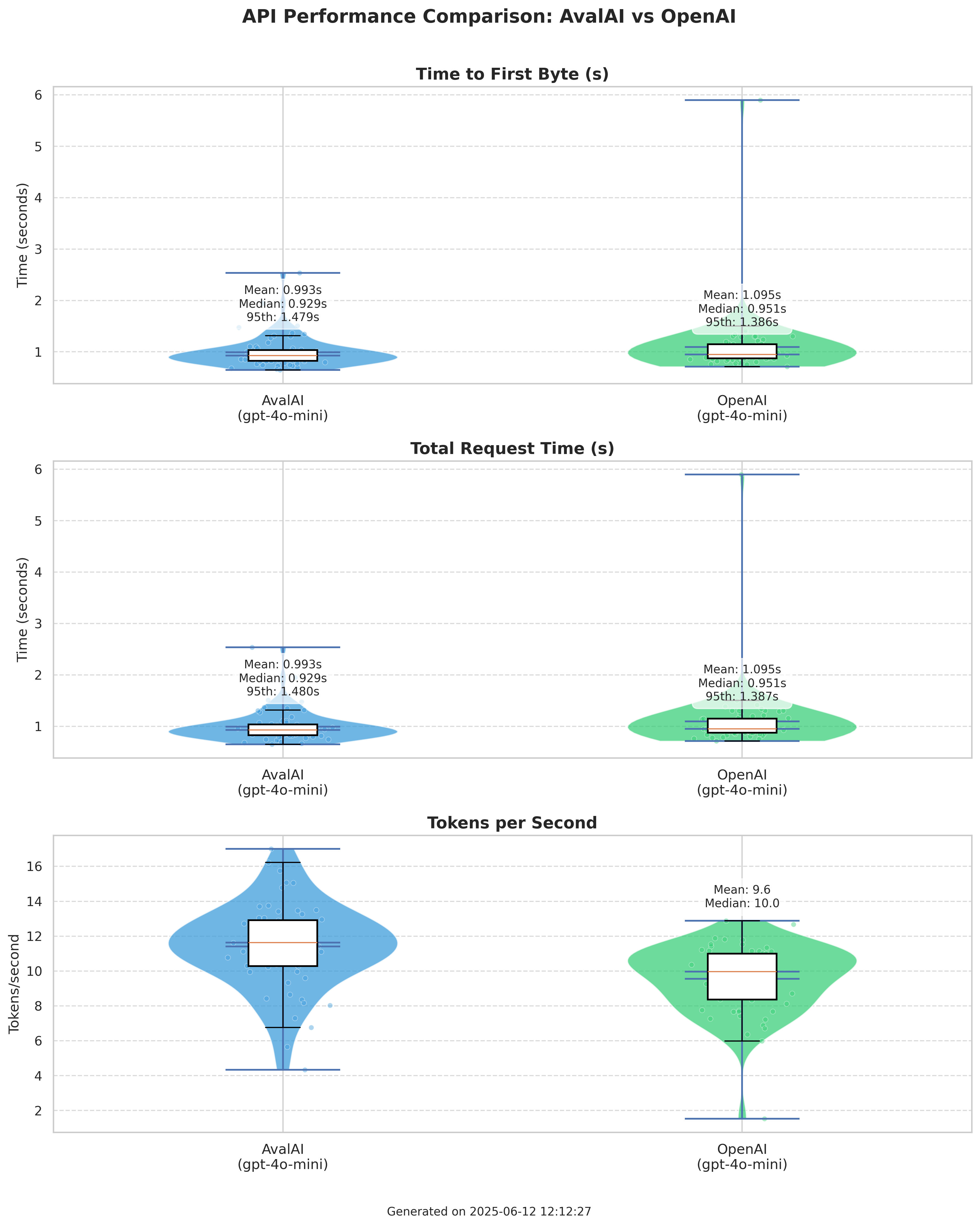
تحلیل
برای کاربران و برنامههای میزبان در خاورمیانه، AvalAI مزیت عملکردی رقابتی را ارائه میدهد. زیرساخت ما برای کاربران منطقهای بهینهسازی شده است که به ما امکان میدهد تا به تأخیر کمتر و توان عملیاتی توکن بالاتر در مقایسه با برقراری تماس مستقیم با سرورهای بینالمللی OpenAI دست یابیم، در حالی که کاربران جهانی نیز از کمترین سربار ممکن بهرهمند میشوند. این نشاندهنده تعهد ما به ارائه تجربهای برتر برای تمامی کاربرانمان است.
نتایج ما را بازتولید کنید
ما به شفافیت کامل اعتقاد داریم. شما میتوانید از اسکریپت پایتون زیر برای اجرای این تستهای عملکردی خودتان استفاده کنید. لطفاً اطمینان حاصل کنید که کتابخانههای لازم (requests, numpy, matplotlib, seaborn, tabulate, tqdm) را نصب کردهاید.
import os
import requests
import time
import numpy as np
import matplotlib.pyplot as plt
import json
from tabulate import tabulate
from tqdm import tqdm
from datetime import datetime
import seaborn as sns
def test_api_performance(api_name, api_url, api_key, model, num_requests=10, prompt="Say hi"):
"""Test API performance and collect comprehensive metrics"""
headers = {"Content-Type": "application/json", "Authorization": f"Bearer {api_key}"}
data = {
"model": model,
"messages": [{"role": "user", "content": prompt}]
}
ttfb_times = []
total_times = []
token_counts = []
tokens_per_second = []
errors = 0
print(f"Testing {api_name} API with {num_requests} requests...")
for _ in tqdm(range(num_requests)):
try:
start_time = time.time()
response = requests.post(api_url, headers=headers, json=data, timeout=(10, 30))
response_time = time.time()
# Process the response
response_json = response.json()
end_time = time.time()
# Calculate metrics
ttfb = response_time - start_time
total_time = end_time - start_time
# Try to get token count if available
try:
usage = response_json.get("usage", {})
total_tokens = usage.get("total_tokens", 0)
completion_tokens = usage.get("completion_tokens", 0)
token_counts.append(total_tokens)
# Calculate tokens per second (using completion tokens)
if completion_tokens > 0 and total_time > 0:
tokens_per_second.append(completion_tokens / total_time)
else:
tokens_per_second.append(0)
except:
token_counts.append(0)
tokens_per_second.append(0)
ttfb_times.append(ttfb)
total_times.append(total_time)
# Add a small delay to avoid rate limiting
time.sleep(0.5)
except Exception as e:
print(f"Error on request: {e}")
errors += 1
return {
'name': api_name,
'url': api_url,
'model': model,
'average_ttfb': np.mean(ttfb_times) if ttfb_times else None,
'median_ttfb': np.median(ttfb_times) if ttfb_times else None,
'p95_ttfb': np.percentile(ttfb_times, 95) if ttfb_times else None,
'average_total': np.mean(total_times) if total_times else None,
'median_total': np.median(total_times) if total_times else None,
'p95_total': np.percentile(total_times, 95) if total_times else None,
'ttfb_times': ttfb_times,
'total_times': total_times,
'token_counts': token_counts,
'avg_tokens': np.mean(token_counts) if token_counts and any(token_counts) else None,
'tokens_per_second': tokens_per_second,
'avg_tokens_per_second': np.mean([t for t in tokens_per_second if t > 0]) if tokens_per_second and any(tokens_per_second) else None,
'median_tokens_per_second': np.median([t for t in tokens_per_second if t > 0]) if tokens_per_second and any(tokens_per_second) else None,
'success_rate': len(ttfb_times) / (len(ttfb_times) + errors) if (len(ttfb_times) + errors) > 0 else 0,
'error_count': errors
}
def print_comparison_table(results_avalai, results_openai):
"""Print comparison table between two APIs"""
headers = ["Metric", f"AvalAI ({results_avalai['model']})", f"OpenAI ({results_openai['model']})"]
data = [
["Average TTFB (s)", f"{results_avalai['average_ttfb']:.3f}", f"{results_openai['average_ttfb']:.3f}"],
["Median TTFB (s)", f"{results_avalai['median_ttfb']:.3f}", f"{results_openai['median_ttfb']:.3f}"],
["95th Percentile TTFB (s)", f"{results_avalai['p95_ttfb']:.3f}", f"{results_openai['p95_ttfb']:.3f}"],
["Average Total Time (s)", f"{results_avalai['average_total']:.3f}", f"{results_openai['average_total']:.3f}"],
["Median Total Time (s)", f"{results_avalai['median_total']:.3f}", f"{results_openai['median_total']:.3f}"],
["95th Percentile Total (s)", f"{results_avalai['p95_total']:.3f}", f"{results_openai['p95_total']:.3f}"],
["Success Rate", f"{results_avalai['success_rate']:.2%}", f"{results_openai['success_rate']:.2%}"]
]
# Add token metrics if available
if results_avalai['avg_tokens'] is not None and results_openai['avg_tokens'] is not None:
data.append(["Avg Tokens per Response", f"{results_avalai['avg_tokens']:.1f}", f"{results_openai['avg_tokens']:.1f}"])
# Add tokens per second metrics if available
if results_avalai['avg_tokens_per_second'] is not None and results_openai['avg_tokens_per_second'] is not None:
data.append(["Avg Tokens per Second", f"{results_avalai['avg_tokens_per_second']:.1f}", f"{results_openai['avg_tokens_per_second']:.1f}"])
data.append(["Median Tokens per Second", f"{results_avalai['median_tokens_per_second']:.1f}", f"{results_openai['median_tokens_per_second']:.1f}"])
print("\nAPI Performance Comparison:")
print(tabulate(data, headers=headers, tablefmt="grid"))
def plot_comparison(results_avalai, results_openai, output_file=None):
"""Create improved visualization plots for API comparison"""
# Set the style
sns.set(style="whitegrid")
# Create figure with subplots - adding a third subplot for tokens per second
fig, axes = plt.subplots(3, 1, figsize=(12, 15))
# Define metrics to plot
metrics = [
('ttfb_times', 'Time to First Byte (s)'),
('total_times', 'Total Request Time (s)'),
('tokens_per_second', 'Tokens per Second')
]
# Define colors for each API
colors = {'AvalAI': '#3498db', 'OpenAI': '#2ecc71'}
for i, (metric, title) in enumerate(metrics):
# Create violin plots with individual points
ax = axes[i]
# Prepare data for plotting
data_to_plot = []
labels = []
for result, label in [(results_avalai, 'AvalAI'), (results_openai, 'OpenAI')]:
# Filter out zeros for tokens per second
if metric == 'tokens_per_second':
data_to_plot.append([t for t in result[metric] if t > 0])
else:
data_to_plot.append(result[metric])
labels.append(f"{label}\n({result['model']})")
# Create violin plot
parts = ax.violinplot(data_to_plot, showmeans=True, showmedians=True)
# Customize violin plots
for pc, color_key in zip(parts['bodies'], colors.keys()):
pc.set_facecolor(colors[color_key])
pc.set_alpha(0.7)
# Add boxplot inside violin
bp = ax.boxplot(data_to_plot, positions=range(1, len(data_to_plot)+1),
widths=0.15, patch_artist=True, showfliers=False)
# Customize boxplots
for box, color_key in zip(bp['boxes'], colors.keys()):
box.set(color='black', linewidth=1.5)
box.set(facecolor='white')
# Add scatter points with jitter
for j, data in enumerate([
results_avalai[metric] if metric != 'tokens_per_second' else [t for t in results_avalai[metric] if t > 0],
results_openai[metric] if metric != 'tokens_per_second' else [t for t in results_openai[metric] if t > 0]
]):
# Add jitter to x position
x = np.random.normal(j+1, 0.05, size=len(data))
ax.scatter(x, data, alpha=0.4, s=20, color=list(colors.values())[j], edgecolor='white', linewidth=0.5)
# Set labels and title
ax.set_title(title, fontsize=14, fontweight='bold')
if metric == 'tokens_per_second':
ax.set_ylabel('Tokens/second', fontsize=12)
else:
ax.set_ylabel('Time (seconds)', fontsize=12)
ax.set_xticks(range(1, len(labels)+1))
ax.set_xticklabels(labels, fontsize=12)
# Add horizontal grid lines
ax.yaxis.grid(True, linestyle='--', alpha=0.7)
# Add stats as text
for j, (result, label) in enumerate([(results_avalai, 'AvalAI'), (results_openai, 'OpenAI')]):
if metric == 'tokens_per_second':
if result['avg_tokens_per_second'] is not None:
stats = f"Mean: {result['avg_tokens_per_second']:.1f}\n" \
f"Median: {result['median_tokens_per_second']:.1f}"
max_val = max([t for t in result[metric] if t > 0]) if any(t > 0 for t in result[metric]) else 0
ax.annotate(stats, xy=(j+1, max_val*1.05),
ha='center', va='bottom', fontsize=10,
bbox=dict(boxstyle='round,pad=0.5', fc='white', alpha=0.7))
else:
stats = f"Mean: {result[f'average_{metric.split("_")[0]}']:.3f}s\n" \
f"Median: {result[f'median_{metric.split("_")[0]}']:.3f}s\n" \
f"95th: {result[f'p95_{metric.split("_")[0]}']:.3f}s"
ax.annotate(stats, xy=(j+1, result[f'p95_{metric.split("_")[0]}']*1.05),
ha='center', va='bottom', fontsize=10,
bbox=dict(boxstyle='round,pad=0.5', fc='white', alpha=0.7))
# Add title and timestamp
plt.suptitle(f'API Performance Comparison: AvalAI vs OpenAI',
fontsize=16, fontweight='bold')
plt.figtext(0.5, 0.01, f'Generated on {datetime.now().strftime("%Y-%m-%d %H:%M:%S")}',
ha='center', fontsize=10)
plt.tight_layout(rect=[0, 0.03, 1, 0.97])
if output_file:
plt.savefig(output_file, dpi=300, bbox_inches='tight')
print(f"Plot saved to {output_file}")
else:
plt.show()
def save_results(results_avalai, results_openai, filename):
"""Save results to JSON file"""
# Convert numpy arrays to lists for JSON serialization
results_avalai_copy = results_avalai.copy()
results_openai_copy = results_openai.copy()
for key in ['ttfb_times', 'total_times', 'token_counts']:
if key in results_avalai_copy:
results_avalai_copy[key] = [float(x) for x in results_avalai_copy[key]]
if key in results_openai_copy:
results_openai_copy[key] = [float(x) for x in results_openai_copy[key]]
data = {
'timestamp': time.strftime('%Y-%m-%d %H:%M:%S'),
'results': {
'avalai': results_avalai_copy,
'openai': results_openai_copy
}
}
with open(filename, 'w') as f:
json.dump(data, f, indent=2)
print(f"Results saved to {filename}")
def main():
# API configuration
model_name = "gpt-4o-mini"
url_avalai = "https://api.avalai.ir/v1/chat/completions"
api_key_avalai = os.getenv("AVALAI_API_KEY") # Replace with actual key
url_openai = "https://api.openai.com/v1/chat/completions"
api_key_openai = os.getenv("OPENAI_API_KEY") # Replace with actual key
# Number of requests to make for each API
num_requests = 60
# Test prompt
prompt = "Say hi"
# Run the tests
results_avalai = test_api_performance("AvalAI", url_avalai, api_key_avalai, model_name, num_requests, prompt)
results_openai = test_api_performance("OpenAI", url_openai, api_key_openai, model_name, num_requests, prompt)
# Print comparison table
print_comparison_table(results_avalai, results_openai)
# Generate visualization
plot_comparison(results_avalai, results_openai, "api_performance_comparison.png")
# Save results
save_results(results_avalai, results_openai, "api_performance_results.json")
if __name__ == "__main__":
main()