زبان پایتون بهدلیل سادگی نحو و خوانایی بالا در سالهای اخیر به محبوبترین انتخاب برای توسعه سیستمهای هوش مصنوعی تبدیل شده است. این زبان دارای کتابخانهها و فریمورکهای گستردهای است که کار با داده و پیادهسازی الگوریتمهای یادگیری ماشین و یادگیری عمیق را بسیار تسهیل میکنند. در این مقاله با زبان ساده ولی دقیق، گامهای ابتدایی برای شروع کار با پایتون در حوزه هوش مصنوعی و کتابخانههای کلیدی آن را بررسی میکنیم.
آمادهسازی محیط پایتون
برای کار با پایتون در هوش مصنوعی ابتدا باید نسخهی جدید پایتون را نصب کنید و از Pip برای مدیریت کتابخانهها استفاده کنید. توصیه میشود از محیط مجازی (Virtual Environment) مثل venv یا conda استفاده کنید تا کتابخانههای پروژهها بهصورت جداگانه نصب شوند. ابزارهایی مانند Jupyter Notebook یا Google Colab برای شروع کار به مبتدیان بسیار مفید هستند، زیرا امکان آزمایش کد و مشاهده فوری نتایج را فراهم میکنند. پس از راهاندازی محیط، نصب کتابخانههای پایهای مثل NumPy و Pandas با دستورهایی نظیر pip install numpy pandas انجام میشود.
کتابخانههای ضروری پایتون برای هوش مصنوعی
کتابخانههای پایه و پردازش داده
NumPy: پایه محاسبات عددی
NumPy به طور گسترده به عنوان بهترین کتابخانه پایتون برای یادگیری ماشین و هوش مصنوعی شناخته میشود. این کتابخانه متنباز عملیات ریاضی مختلفی روی ماتریسهای مختلف انجام میدهد.
ویژگیهای کلیدی NumPy:
- آرایههای NumPy نسبت به لیستهای معمولی پایتون، فضای ذخیرهسازی کمتری نیاز دارند و سریعتر و راحتتر قابل استفاده هستند
- پشتیبانی از عملیات جبر خطی، تبدیل فوریه و اعداد تصادفی
- شکلدهی و تغییر شکل دادهها در ماتریس
import numpy as np
# ایجاد ماتریس ویژگی (X) و بردار هدف (y)
X = np.array([[1, 2], [3, 4], [5, 6]])
y = np.array([1, 2, 3])
# محاسبه میانگین هر ویژگی
mean = np.mean(X, axis=0)
print("میانگین ویژگیها:", mean)
Pandas: تحلیل و دستکاری داده
Pandas یکی از محبوبترین کتابخانههای پایتون برای یادگیری ماشین است که به عنوان کتابخانه تحلیل داده عمل میکند. این کتابخانه تحلیل و دستکاری دادهها را انجام میدهد و به توسعهدهندگان امکان کار آسان با دادههای چندبعدی ساختاریافته و مفاهیم سری زمانی را میدهد.
قابلیتهای Pandas:
- ارائه اشیاء DataFrame برای دستکاری داده با نمایهگذاری یکپارچه
- ابزار جامع برای دستکاری و تحلیل داده
- سهولت یادگیری و استفاده
Matplotlib: تجسم دادهها
Matplotlib یک کتابخانه بسیار محبوب پایتون برای تجسم دادهها است که مستقیماً با یادگیری ماشین ارتباط ندارد، اما زمانی که برنامهنویس میخواهد الگوهای موجود در دادهها را تجسم کند، بسیار مفید است.
کتابخانههای یادگیری ماشین
Scikit-learn: ابزار جامع یادگیری ماشین
Scikit-learn یک کتابخانه برتر برای یادگیری ماشین است که ابزارهای ساده و کارآمد برای دادهکاوی و تحلیل داده فراهم میکند. این کتابخانه طیف گستردهای از الگوریتمهای یادگیری نظارتشده و بدون نظارت ارائه میدهد.
مزایای Scikit-learn:
- پشتیبانی عالی جامعه و مستندات جامع
- ایدهآل برای دادههای ساختاریافته، رگرسیون یا کارهای طبقهبندی
- طراحی ساده برای تازهواردان به یادگیری ماشین
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# تقسیم دادهها
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# ایجاد و آموزش مدل
model = LinearRegression()
model.fit(X_train, y_train)
# پیشبینی
predictions = model.predict(X_test)
کتابخانههای یادگیری عمیق
TensorFlow: قدرت گوگل در یادگیری عمیق
TensorFlow که توسط گوگل توسعه یافته، یکی از قدرتمندترین کتابخانههای هوش مصنوعی و یادگیری ماشین است که برای یادگیری عمیق، مدلهای هوش مصنوعی مقیاس بزرگ و کاربردهای بلادرنگ طراحی شده است.
مزایای TensorFlow:
- مدیریت بارهای کاری سنگین هوش مصنوعی با سهولت – چه مدل هوش مصنوعی شما هزاران تصویر پزشکی را تحلیل کند یا مقادیر عظیمی از دادههای کاربر را پردازش کند
- آماده برای تولید، نه فقط تحقیق
- پشتیبانی از GPU و TPU برای محاسبات سریع
PyTorch: انعطاف در تحقیق
PyTorch یک فریمورک یادگیری ماشین متنباز است که توسط آزمایشگاه تحقیقات هوش مصنوعی فیسبوک (FAIR) توسعه یافته و فرآیند اشکالزدایی آسان و ساخت مدل شهودیتری نسبت به گرافهای استاتیک فراهم میکند.
ویژگیهای PyTorch:
- گراف محاسباتی پویا که توسعه و اشکالزدایی شهودی مدل را تسهیل میکند
- API پایتونی و کاربرپسند که آن را برای محققان و توسعهدهندگان قابل دسترس میکند
- محبوبیت در جامعه تحقیقاتی
Keras: سادگی در یادگیری عمیق
Keras یکی دیگر از کتابخانههای محبوب برای یادگیری ماشین و هوش مصنوعی است. این یک API سطح بالا برای شبکههای عصبی است که به زبان پایتون نوشته شده.
کتابخانههای تخصصی
NLTK و Hugging Face: پردازش زبان طبیعی
NLTK یک کتابخانه محبوب و قابل اعتماد NLP است که ابزارهای زیادی برای پردازش متن دارد و از stemming، lemmatization، تحلیل corpus و تقریباً هر کار سنتی NLP که میتوانید به آن فکر کنید، پشتیبانی میکند.
کتابخانه Transformers توسط Hugging Face مجموعهای محبوب از ابزارها برای کار با LLMها است که هزاران مدل از پیش آموزشدیده متنباز برای کارهای مختلف از جمله BERT، T5، Falcon، LLaMA و بسیاری موارد دیگر در دسترس قرار میدهد.
XGBoost و LightGBM: تقویت گرادیان
XGBoost یک الگوریتم یادگیری ماشین محبوب است که به دلیل عملکرد بالا و مقیاسپذیری شناخته شده است. LightGBM یک الگوریتم تقویت گرادیان سریع است که برای مجموعه دادههای بزرگ و دادههای چندبعدی طراحی شده است.
مقایسه کتابخانهها
در انتخاب بین کتابخانههای مختلف میتوان برخی نکات را در نظر گرفت:
Scikit-Learn در مقابل XGBoost/LightGBM: Scikit-Learn برای شروع کار با یادگیری ماشین سنتی ایدهآل است و رابط کاربری سادهای دارد. از طرفی XGBoost و LightGBM برای مسائل دادهمحور با حجم بالا، بهویژه در پروژههای رقابتی، عملکرد برتری ارائه میدهند. بهتر است از Scikit-Learn برای درک اولیه الگوریتمها شروع کنید و در پروژههای جدیتر سراغ XGBoost/LightGBM بروید.
TensorFlow در مقابل PyTorch: هر دو کتابخانه توان محاسباتی مشابهی دارند؛ اما در سبک برنامهنویسی فرقهایی دارند. PyTorch با گراف پویا راحتتر خطایابی میشود، در حالی که TensorFlow با امکانات بیشتر برای تولید مدل و اکوسیستم وسیعتر مشهور است. اگر مبتدی هستید، Keras (سطح بالای TensorFlow) میتواند شروع سادهتری باشد.
Keras: اگر میخواهید سریع مدلهای عصبی بسازید بدون درگیر شدن با جزئیات زیاد، Keras انتخاب خوبی است. میتوانید خیلی راحت یک شبکه عمیق با چند دستور تعریف کنید و آموزش دهید.
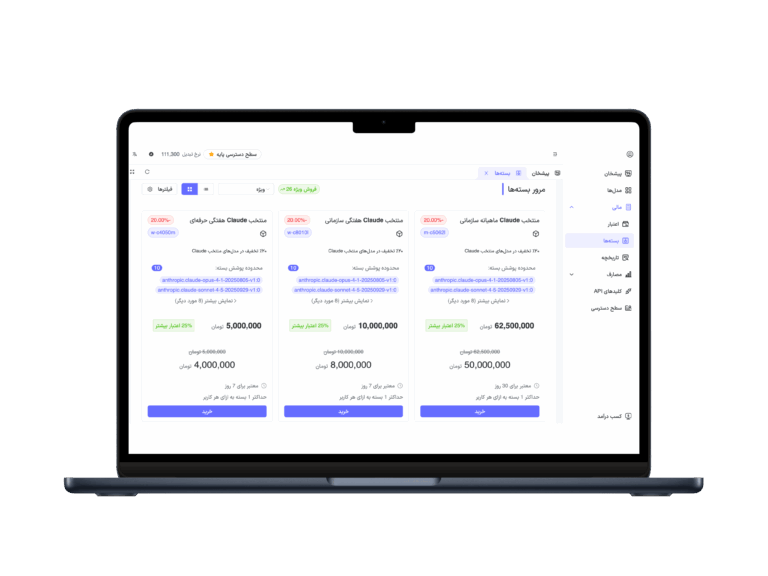
پلتفرم API یکپارچه (AvalAI)
یکی از چالشهای توسعهدهندگان این است که برای دسترسی به مدلهای هوش مصنوعی مختلف باید APIهای متفاوتی یاد بگیرند و احراز هویتهای مجزا مدیریت کنند. AvalAI یک پلتفرم API یکپارچه است که بیش از ۱۰ ارائهدهنده مطرح AI مانند OpenAI، Anthropic، XAI، Meta، Mistral AI، Cohere، Alibaba، Google (Gemini)، Stability AI و DeepSeek را در یکجا گردآوری کرده است. با AvalAI، کافی است یک کلید API داشته باشید تا از طریق یک API سازگار با OpenAI به همهی این سرویسها دسترسی پیدا کنید. مهمترین ویژگیهای این پلتفرم عبارتند از:
یک API، چندین ارائهدهنده: با یک کتابخانهی سازگار با OpenAI یا SDK رسمی Anthropic، میتوانید مدلهای مختلف را فراخوانی کنید. برای مثال میتوان با همان کد مورد استفاده برای OpenAI به مدلهای GPT-4o، Claude 3.5، Gemini و دیگر مدلها دسترسی داشت
یکپارچگی کامل: فرمت درخواستها و پاسخها در تمام ارائهدهندگان یکسان است، بنابراین نیازی نیست چندین روش متفاوت را یاد بگیرید. همچنین امکاناتی مانند گاردریل (محدودیت ایمن) و گزارش مصرف هزینه وجود دارد.
پشتیبانی از SDKهای دوگانه: میتوانید از SDKهای متنباز OpenAI برای دسترسی ادغامشده یا از SDK رسمی Anthropic برای مدلهای کلود استفاده کنید. این انعطافپذیری امکان تغییر راحت بین ارائهدهندگان مختلف را میدهد.
انتخاب مدل انعطافپذیر: به سادگی میتوانید بدون تغییر کد خود بین مدلهای مختلف (مثلاً GPT-4o، Claude 4، یا مدلهای Google Gemini) جابجا شوید و بهترین مدل را برای کاربرد خود انتخاب کنید.
کار با AvalAI این امکان را میدهد که پروژههای هوش مصنوعی را سریعتر آغاز کنید و بدون دغدغه مدیریت چند API مختلف، از جدیدترین مدلها استفاده کنید.
import openai
# تنظیم AvalAI
openai.api_base = "https://api.avalai.ir/v1"
openai.api_key = "YOUR_AVALAI_API_KEY"
# استفاده از مدلهای مختلف
response = openai.ChatCompletion.create(
model="gpt-4", # یا claude-3-sonnet، gemini-pro و غیره
messages=[
{"role": "user", "content": "سلام، چطوری؟"}
]
)
اولین گامها: شروع عملی
نصب و راهاندازی محیط
برای شروع کار با پایتون و هوش مصنوعی، ابتدا باید محیط کاری مناسب را آماده کنید:
# نصب کتابخانههای اصلی
pip install numpy pandas matplotlib scikit-learn
# نصب کتابخانههای یادگیری عمیق
pip install tensorflow torch
# نصب کتابخانههای NLP
pip install nltk transformers
# نصب کتابخانههای تقویت گرادیان
pip install xgboost lightgbm
پروژه عملی ساده: طبقهبندی دادهها
در ادامه نمونهای از یک پروژه ساده یادگیری ماشین ارائه میدهیم:
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# بارگذاری دادهها
iris = load_iris()
X, y = iris.data, iris.target
# تقسیم دادهها به مجموعه آموزش و تست
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# ایجاد و آموزش مدل
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# پیشبینی و ارزیابی
predictions = model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
print(f"دقت مدل: {accuracy:.2f}")
ایجاد چتبات ساده با هوش مصنوعی
با استفاده از تکنیکهای ساده، میتوان چتبات هوشمندی ایجاد کرد که از فهرستها برای ذخیره کلمات کلیدی و پاسخها استفاده میکند:
import random
# لیستهای احوالپرسی و خداحافظی
greetings = ["سلام", "درود", "سلام علیکم"]
goodbyes = ["خداحافظ", "فعلاً", "تا بعد"]
# کلمات کلیدی و پاسخها
keywords = ["هوا", "غذا", "ورزش"]
responses = [
"امروز هوا خیلی خوبه!",
"من به غذای ایرانی علاقه دارم",
"ورزش برای سلامتی مفیده"
]
def chatbot_response(user_input):
user_input = user_input.lower()
# بررسی احوالپرسی
for greeting in greetings:
if greeting in user_input:
return random.choice(greetings) + "! چطور میتونم کمکتون کنم؟"
# بررسی کلمات کلیدی
for i, keyword in enumerate(keywords):
if keyword in user_input:
return responses[i]
return "متوجه نشدم. میتونید سؤال دیگهای بپرسید؟"
# تست چتبات
print(chatbot_response("سلام"))
print(chatbot_response("هوا چطوره؟"))
ترندهای جدید و آینده
یادگیری تقویتی و مدلهای زبانی بزرگ
در سال 2025، شناخت کتابخانههای مناسب پایتون برای LLM و کارهای NLP برای ساخت برنامههای پیشرفته پردازش زبان و هوش مصنوعی ضروری است. کتابخانههایی مانند Transformers، LangChain، و SentenceTransformers در حال تبدیل شدن به ابزارهای اصلی این حوزه هستند.
ابزارهای بهینهسازی مدل
Optuna یک فریمورک بهینهسازی متنباز است که برای تنظیم hyperparameter در یادگیری ماشین طراحی شده است. این ابزار جستجو برای پارامترهای بهینه مدل را با استفاده از الگوریتمهایی مانند tree-structured Parzen estimators خودکار میکند.
جمعبندی و نتیجهگیری
با ادامه تکامل سریع یادگیری ماشین در سال 2025، مجهز بودن به ابزارهای مناسب مهمتر از همیشه است. پایتون با اکوسیستم غنی کتابخانههایش، از فریمورکهای بنیادی مانند TensorFlow و PyTorch تا ابزارهای تخصصی مانند Hugging Face Transformers و Optuna، توسعهدهندگان و محققان را قادر میسازد تا مدلهای پیشروی زمان را با کارایی و انعطاف بسازند، بهینهسازی کنند و به کار گیرند.
برای توسعهدهندگان مبتدی، مسیر یادگیری باید تدریجی و منطقی باشد. آغاز با کتابخانههای پایه مانند NumPy و Pandas، سپس حرکت به سمت Scikit-learn برای یادگیری ماشین کلاسیک، و در نهایت ورود به دنیای یادگیری عمیق با TensorFlow یا PyTorch، رویکردی مؤثر است.
استفاده از پلتفرمهایی مانند AvalAI که دسترسی یکپارچه به مدلهای مختلف هوش مصنوعی فراهم میکند، میتواند فرآیند توسعه را تسریع کند و پیچیدگیهای مدیریت API های مختلف را کاهش دهد.
نکات کلیدی و کاربردی
برای شروع:
- پایهریزی محکم: ابتدا NumPy و Pandas را به خوبی یاد بگیرید
- تمرین عملی: روزانه حداقل یک ساعت کدنویسی عملی انجام دهید
- پروژهمحوری: همیشه روی پروژههای کوچک و عملی کار کنید
انتخاب کتابخانه مناسب:
- دادههای ساختاریافته: Scikit-learn
- یادگیری عمیق: TensorFlow یا PyTorch
- پردازش زبان طبیعی: NLTK، spaCy، یا Transformers
- تجسم دادهها: Matplotlib یا Seaborn
بهترین روشها:
- همیشه دادهها را قبل از مدلسازی پاکسازی کنید
- مدلها را روی دادههای تست ارزیابی کنید
- از تکنیکهای Cross-validation استفاده کنید
- کد خود را مستندسازی کنید
منابع یادگیری مفید:
- مستندات رسمی کتابخانهها
- دورههای آنلاین معتبر
- پروژههای GitHub
- جامعههای علمی و حرفهای
جمعبندی و نتیجهگیری
پایتون به دلیل سادگی، خوانایی و وجود کتابخانههای قدرتمند، بهترین نقطه شروع برای هر توسعهدهنده مبتدی هوش مصنوعی است. با یادگیری کتابخانههای پایه مانند NumPy و Pandas میتوانید دادههای خود را آماده کنید و با Scikit-Learn مدلهای اولیه یادگیری ماشین را پیادهسازی نمایید. برای پروژههای پیچیدهتر و شبکههای عصبی، TensorFlow، Keras و PyTorch ابزارهای کاملی هستند که به شما امکان طراحی مدلهای عمیق را میدهند. همچنین با استفاده از پلتفرمهای یکپارچه مانند AvalAI میتوانید بدون کار اضافی به مدلهای پیشرفتهی مختلف دسترسی پیدا کنید. برای تسلط بیشتر، مثالهای عملی ساده بسازید، مستندات رسمی را مطالعه کنید و از منابع آموزشی آنلاین بهره ببرید.