امروزه، یادگیری با ناظر به عنوان پرکاربردترین زیرشاخه یادگیری ماشین شناخته میشود. به طور معمول، افراد جدید وارد دنیای یادگیری ماشین با آشنایی با الگوریتمهای یادگیری با نظارت مقدمه مینمایند.
در این مقاله، ما قصد داریم یادگیری با نظارت را معرفی کنیم، نحوه عملکرد آن را تشریح نماییم، دو زیرمجموعه اصلی آن را بررسی کنیم، و در نهایت با مزایا و معایب این رویکرد آشنا شویم.
قبل از بحث در مورد یادگیری با نظارت به عنوان یکی از زیرشاخههای یادگیری ماشین، مفهوم یادگیری ماشین و نحوه عملکرد آن را مورد بررسی قرار دهیم.
ماشین لرنینگ چیست ؟
یادگیری ماشین (Machine Learning) شاخهای از هوش مصنوعی است که به ماشینها اجازه میدهد بدون برنامهریزی صریح، از روی دادهها و تجربیات گذشته یاد بگیرند و الگوهایی را برای پیشبینی شناسایی کنند. ماشین لرنینگ در طیف گستردهای از کاربردها، از جمله مالی محاسباتی، بینایی کامپیوتر، زیست شناسی محاسباتی، خودروسازی، هوافضا و تولید و پردازش زبان طبیعی استفاده میشود.
یادگیری ماشین با استفاده از الگوریتمها برای شناسایی الگوها و یادگیری در یک فرآیند تکراری، اطلاعات و بینش مفیدی را از حجم زیادی از داده به دست میآورد. الگوریتمهای یادگیری ماشین از روشهای محاسباتی برای یادگیری مستقیم از دادهها استفاده میکنند. عملکرد الگوریتمهای ML به طور تطبیقی با افزایش تعداد نمونههای موجود در طول فرآیندهای “یادگیری” بهبود مییابد.
انواع یادگیری ماشین
یادگیری ماشین به دو دسته کلی تقسیم میشود:
- یادگیری با ناظر (Supervised Learning): در یادگیری با ناظر، ماشین با دادههای برچسبدار آموزش میبیند. دادههای برچسبدار دادههایی هستند که در آن خروجی مورد انتظار برای هر ورودی مشخص شده است. به عنوان مثال، دادههای برچسبدار برای تشخیص چهره ممکن است شامل تصاویری از چهرههای انسان با برچسبهای مربوط به سن، جنسیت و احساسات باشد.
- یادگیری بدون ناظر (Unsupervised Learning): در یادگیری بدون ناظر، ماشین با دادههای بدون برچسب آموزش میبیند. دادههای بدون برچسب دادههایی هستند که در آن خروجی مورد انتظار برای هر ورودی مشخص نشده است. به عنوان مثال، یک مدل یادگیری بدون ناظر میتواند از دادههای بدون برچسب برای شناسایی الگوهای مشترک در دادهها استفاده کند.
کاربردهای یادگیری ماشین
ماشین لرنینگ در طیف گستردهای از کاربردها مورد استفاده قرار میگیرد، از جمله:
- مالی محاسباتی (Computational Finance): یادگیری ماشین برای ارزیابی ریسک اعتباری، معاملات الگوریتمی و مدیریت سبد سهام استفاده میشود.
- بینایی کامپیوتر (Computer Vision): یادگیری ماشین برای تشخیص چهره، ردیابی حرکت و تشخیص اشیا استفاده میشود.
- زیست شناسی محاسباتی (Computational Biology): یادگیری ماشین برای توالی یابی DNA، تشخیص تومور مغزی و کشف دارو استفاده میشود.
- خودروسازی، هوافضا و تولید (Automotive, Aerospace and Manufacturing): یادگیری ماشین برای تعمیر و نگهداری پیشبینی شده، کنترل فرآیند و طراحی محصولات استفاده میشود.
- پردازش زبان طبیعی (Natural Language Processing): یادگیری ماشین برای تشخیص گفتار، ترجمه متن و پاسخ به سؤالات استفاده میشود.
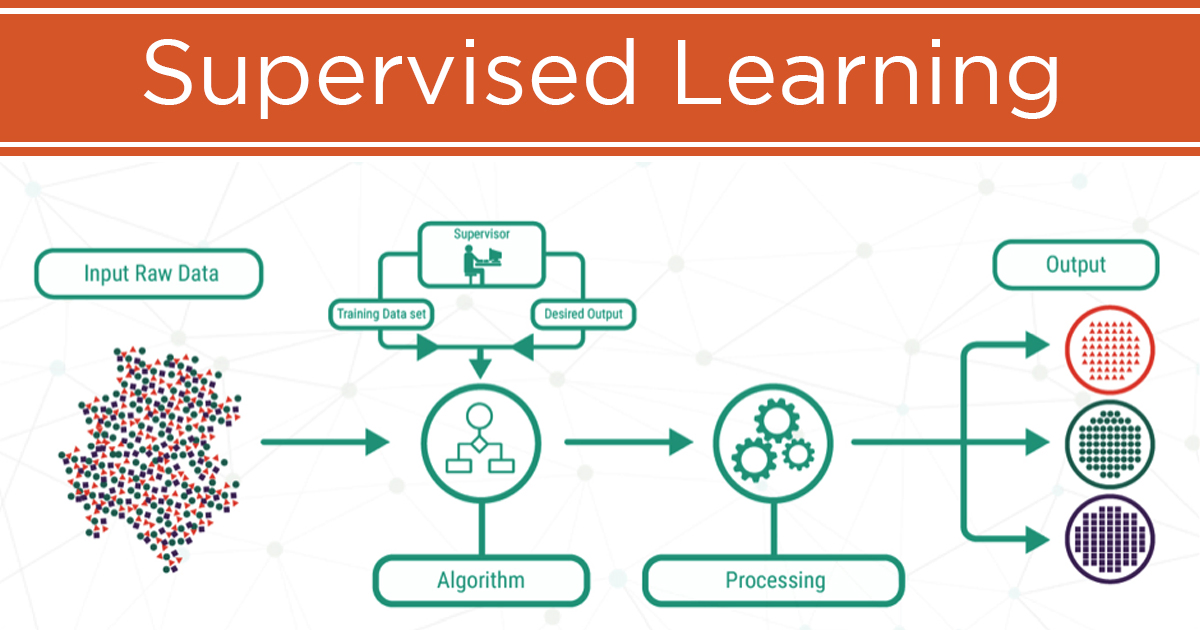
یادگیری با ناظر چیست ؟
یادگیری نظارت شده (Supervised Learning) یکی از دو دسته اصلی یادگیری ماشین است. در یادگیری با ناظر، به ماشین دادههای برچسبدار داده میشود. دادههای برچسبدار دادههایی هستند که در آن خروجی مورد انتظار برای هر ورودی مشخص شده است. به عنوان مثال، دادههای برچسبدار برای تشخیص چهره ممکن است شامل تصاویری از چهرههای انسان با برچسبهای مربوط به سن، جنسیت و احساسات باشد.
در یادگیری با ناظر، ماشین از دادههای برچسبدار برای یادگیری یک تابع استفاده میکند که میتواند خروجی مورد انتظار را برای ورودیهای جدید پیشبینی کند. این تابع معمولاً یک مدل آماری است که میتوان از آن برای پیشبینی، طبقهبندی یا رگرسیون استفاده کرد.
تعریف و مبانی یادگیری با ناظر
یادگیری با ناظر روشی است که در آن مدل هوش مصنوعی از مجموعهای از دادههای برچسبدار برای یادگیری استفاده میکند. هر نمونه در این دادهها به صورت یک جفت ورودی و خروجی ارائه میشود؛ به عبارت دیگر، سیستم در طی فرآیند آموزش به دنبال یافتن یک تابع یا نگاشت ریاضی است که بتواند ورودیها را به خروجیهای مربوطه متصل کند.
اصول کلی یادگیری با ناظر شامل موارد زیر است:
- دادههای برچسبدار: دادههایی که برای هر ورودی، خروجی صحیح مشخص میشود.
- تابع هدف: تابعی که به دنبال یافتن نگاشت درست بین ورودی و خروجی است.
- معیار ارزیابی: از جمله معیارهایی مانند خطای میانگین مربعات (MSE) برای مسائل رگرسیونی و آمار دقت (Accuracy) برای مسائل دستهبندی، جهت سنجش عملکرد مدل استفاده میشود.
- مرحله آموزش و آزمون: مجموعه دادهها به دو دسته تقسیم میشوند؛ یکی برای آموزش مدل (Training) و دیگری برای ارزیابی عملکرد آن (Testing).
فرایند یادگیری با ناظر
یادگیری با ناظر در چهار مرحله انجام میشود:
- جمعآوری دادهها: اولین قدم در یادگیری با ناظر جمعآوری دادههای برچسبدار است. این دادهها میتوانند از منابع مختلفی، مانند آزمایشها، مشاهدات یا منابع موجود جمعآوری شوند.
- پیشپردازش دادهها: قبل از آموزش مدل، دادهها باید پیشپردازش شوند. این فرآیند ممکن است شامل حذف دادههای ناقص یا نامعتبر، تبدیل دادهها به یک فرمت مناسب و استانداردسازی دادهها باشد.
- انتخاب الگوریتم: در مرحله بعدی، باید یک الگوریتم یادگیری با ناظر انتخاب شود. الگوریتمهای یادگیری با ناظر مختلف برای کاربردهای مختلف مناسب هستند.
- آموزش مدل: مرحله آخر آموزش مدل است. در این مرحله، مدل با استفاده از دادههای برچسبدار آموزش میبیند.
الگوریتمهای یادگیری با ناظر
الگوریتمهای یادگیری با ناظر مختلفی وجود دارد که هر کدام برای کاربردهای خاصی مناسب هستند. برخی از الگوریتمهای یادگیری با ناظر رایج عبارتند از:
- رگرسیون (Regression): رگرسیون برای پیشبینی مقادیر پیوسته استفاده میشود. به عنوان مثال، یک مدل رگرسیون میتواند برای پیشبینی قیمت سهام یا آب و هوا استفاده شود.
- طبقهبندی (Classification): طبقهبندی برای تخصیص دادههای جدید به یکی از چندین کلاس استفاده میشود. به عنوان مثال، یک مدل طبقهبندی میتواند برای تشخیص چهره، تشخیص بیماری یا طبقهبندی ایمیلها استفاده شود.
- بازگشتی (Recurrent): بازگشتی برای مدلسازی دادههای زمانی استفاده میشود. به عنوان مثال، یک مدل بازگشتی میتواند برای پیشبینی قیمت سهام در آینده یا تشخیص گفتار استفاده شود.
رگرسیون (Regression)
رگرسیون یک تکنیک یادگیری ماشین است که برای پیشبینی مقادیر پیوسته استفاده میشود. به عنوان مثال، یک مدل رگرسیون میتواند برای پیشبینی قیمت سهام یا آب و هوا استفاده شود.
در رگرسیون، ما یک تابع ریاضی ایجاد میکنیم که رابطه بین مقادیر ورودی (متغیرهای مستقل) و مقدار خروجی (متغیر وابسته) را توصیف میکند. این تابع میتواند برای پیشبینی مقادیر خروجی برای دادههای جدید استفاده شود.
انواع مختلفی از الگوریتمهای رگرسیون وجود دارد، از جمله:
- رگرسیون خطی: سادهترین نوع رگرسیون است که از یک تابع خطی برای توصیف رابطه بین مقادیر ورودی و خروجی استفاده میکند.
- رگرسیون چندگانه: از چند متغیر مستقل برای پیشبینی مقدار خروجی استفاده میکند.
- رگرسیون غیرخطی: از یک تابع غیرخطی برای توصیف رابطه بین مقادیر ورودی و خروجی استفاده میکند.
طبقهبندی (Classification)
طبقهبندی یک تکنیک یادگیری ماشین است که برای تخصیص دادههای جدید به یکی از چندین کلاس استفاده میشود. به عنوان مثال، یک مدل طبقهبندی میتواند برای تشخیص چهره، تشخیص بیماری یا طبقهبندی ایمیلها استفاده شود.
در طبقهبندی، ما یک مدل ایجاد میکنیم که میتواند دادههای جدید را به کلاس صحیح خود طبقهبندی کند. این مدل معمولاً بر اساس یک تابع احتمال ساخته میشود که احتمال اینکه یک داده خاص به یک کلاس خاص تعلق داشته باشد را محاسبه میکند.
انواع مختلفی از الگوریتمهای طبقهبندی وجود دارد، از جمله:
- درختان تصمیم: از یک درخت تصمیم برای تقسیم دادهها به کلاسهای مختلف استفاده میکنند.
- ماشینهای بردار پشتیبانی (SVM): از یک تابع مرزی برای جداسازی دادههای کلاسهای مختلف استفاده میکنند.
- شبکههای عصبی مصنوعی: از یک شبکه عصبی برای یادگیری رابطه بین دادههای ورودی و کلاسهای خروجی استفاده میکنند.
بازگشتی (Recurrent)
بازگشتی یک تکنیک یادگیری ماشین است که برای مدلسازی دادههای زمانی استفاده میشود. به عنوان مثال، یک مدل بازگشتی میتواند برای پیشبینی قیمت سهام در آینده یا تشخیص گفتار استفاده شود.
در بازگشتی، ما یک مدل ایجاد میکنیم که میتواند رابطه بین مقادیر دادههای زمانی را در طول زمان مدلسازی کند. این مدل میتواند برای پیشبینی مقادیر آینده دادههای زمانی استفاده شود.
انواع مختلفی از الگوریتمهای بازگشتی وجود دارد، از جمله:
- شبکههای عصبی بازگشتی: از یک شبکه عصبی برای مدلسازی رابطه بین مقادیر دادههای زمانی استفاده میکنند.
- مدلهای حرکتی: از یک تابع ریاضی برای توصیف رابطه بین مقادیر دادههای زمانی استفاده میکنند.
- مدلهای پیشبینی زمانی: از یک تابع احتمال برای محاسبه احتمال مقادیر آینده دادههای زمانی استفاده میکنند.
مقایسه الگوریتمهای یادگیری با ناظر
جدول زیر مقایسهای از الگوریتمهای یادگیری با ناظر رایج را نشان میدهد:
| ویژگی | رگرسیون | طبقهبندی | بازگشتی |
|---|---|---|---|
| نوع خروجی | مقادیر پیوسته | مقادیر گسسته | مقادیر پیوسته یا گسسته |
| کاربردها | پیشبینی قیمت سهام، آب و هوا، … | تشخیص چهره، تشخیص بیماری، … | پیشبینی قیمت سهام در آینده، تشخیص گفتار، … |
| انواع الگوریتمها | رگرسیون خطی، رگرسیون چندگانه، رگرسیون غیرخطی، … | درختان تصمیم، ماشینهای بردار پشتیبانی (SVM)، شبکههای عصبی مصنوعی، … | شبکههای عصبی بازگشتی، مدلهای حرکتی، مدلهای پیشبینی زمانی، … |
انتخاب الگوریتم یادگیری با ناظر مناسب برای یک کاربرد خاص به عوامل مختلفی بستگی دارد، از جمله نوع خروجی مورد نظر، کاربرد مورد نظر و حجم و کیفیت دادههای آموزشی.
مزایای یادگیری با ناظر
- دقت بالا: یادگیری با ناظر میتواند دقت بالایی در پیشبینی یا طبقهبندی دادههای جدید داشته باشد. این به این دلیل است که این روش از دادههای آموزشی برای یادگیری رابطه بین دادههای ورودی و خروجی استفاده میکند.
- کاربردهای متنوع: یادگیری با ناظر در طیف وسیعی از کاربردها استفاده میشود، از جمله پیشبینی قیمت سهام، تشخیص چهره، تشخیص بیماری و طبقهبندی ایمیلها.
- توانایی یادگیری از دادههای گذشته: یادگیری با ناظر میتواند از دادههای گذشته برای بهبود عملکرد خود استفاده کند. این به این دلیل است که این روش میتواند از دادههای آموزشی برای شناسایی الگوها و روابط بین دادههای ورودی و خروجی استفاده کند.
معایب یادگیری با ناظر
- نیاز به دادههای آموزشی برچسبدار: یادگیری با ناظر برای آموزش به دادههای آموزشی برچسبدار نیاز دارد. این بدان معناست که برای هر نمونه داده، باید خروجی صحیح آن نیز مشخص باشد. جمعآوری دادههای آموزشی برچسبدار میتواند زمانبر و پرهزینه باشد.
- حساسیت به دادههای آموزشی: یادگیری با ناظر به کیفیت دادههای آموزشی حساس است. اگر دادههای آموزشی ناقص یا نادرست باشند، ممکن است مدل یادگیری شده نیز ناقص یا نادرست باشد.
- توانایی محدود در یادگیری از دادههای جدید: یادگیری با ناظر ممکن است در یادگیری از دادههای جدید محدود باشد. این به این دلیل است که این روش بر اساس رابطه بین دادههای ورودی و خروجی در دادههای آموزشی آموزش دیده است. اگر دادههای جدید با دادههای آموزشی متفاوت باشند، مدل یادگیری شده ممکن است عملکرد خوبی نداشته باشد.