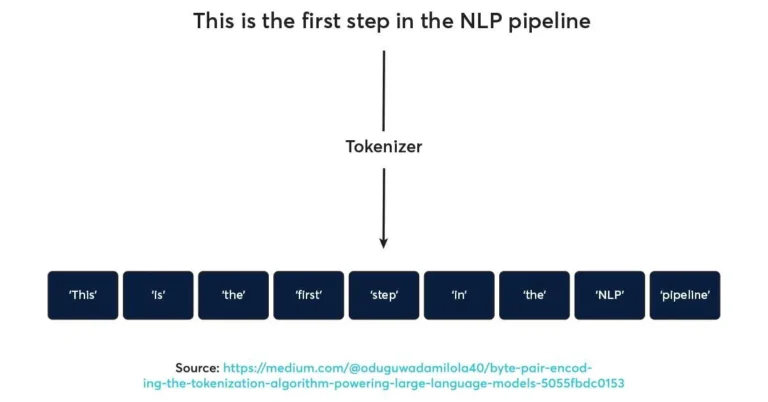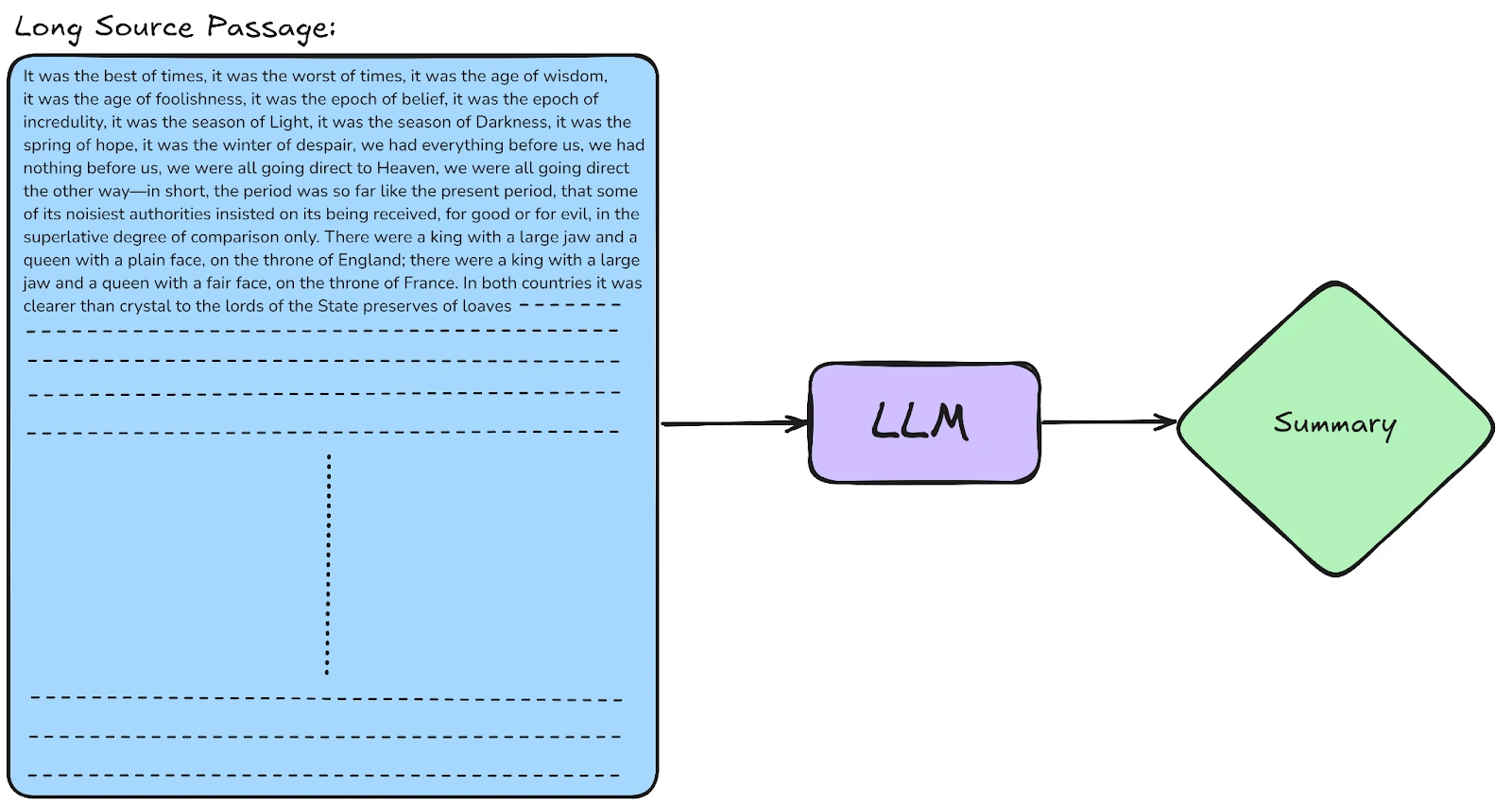
طول زمینه به حداکثر تعداد توکنها (Tokens) اشاره دارد که یک مدل زبانی میتواند در یک ورودی پردازش کند. توکنها، واحدهای اساسی متن هستند که مدل میتواند آنها را درک کند. این واحدها ممکن است کلمات، زیرکلمات یا حتی کاراکترها باشند. برای مثال، جملهی “هوش مصنوعی در حال پیشرفت است” ممکن است به توکنهایی مانند “هوش”، “مصنوعی”، “در”، “حال”، “پیشرفت”، “است” شکسته شود.
در واقع، Context Length مانند حافظه کوتاهمدت مدل عمل میکند و تعیین میکند که مدل تا چه اندازه میتواند اطلاعات یک متن را به طور همزمان پردازش و تحلیل کند.
در این مقاله، Context Length مدلهای هوش مصنوعی مختلف مانند GPT-4، Claude، Gemini، DeepSeek و Qwen بررسی و با یکدیگر مقایسه میشود.
طول زمینه (Context Length) چیست؟
طول زمینه به تعداد توکنها (Tokens) اشاره دارد که یک مدل زبانی میتواند به طور همزمان در یک ورودی پردازش کند. توکنها به قطعات کوچکی از متن شکسته میشوند که میتوانند کلمات، زیرکلمات یا حتی کاراکترها باشند. هرچه Context Length بیشتر باشد، مدل میتواند اطلاعات بیشتری از متن را درک کند و به پردازش متون پیچیدهتر بپردازد.
برای مثال، اگر Context Length یک مدل 2048 توکن باشد، این مدل تنها میتواند متنی به اندازه 2048 توکن را پردازش کند. اگر متن ورودی طولانیتر از این مقدار باشد، مدل باید اطلاعات قدیمیتر را فراموش کند یا آنها را نادیده بگیرد.
اهمیت Context Length در مدلهای زبانی بزرگ
طول زمینه یکی از عوامل کلیدی در عملکرد مدلهای زبانی است و تأثیر مستقیمی بر خروجی این مدلها دارد. در زیر به برخی از جنبههای اهمیت آن اشاره شده است:
1. درک بهتر متنهای طولانی
مدلهای زبانی با Context Length بیشتر، توانایی بیشتری در پردازش متنهای بلند دارند. این ویژگی در کاربردهایی مانند نوشتن مقالات، تحلیل متون پیچیده یا مکالمات طولانی اهمیت ویژهای دارد.
2. افزایش دقت در پاسخدهی
مدلهایی با Context Length بلندتر میتوانند اطلاعات بیشتری را در نظر بگیرند و پاسخهای دقیقتر و مرتبطتری ارائه دهند. برای مثال، در یک متن علمی، مدل میتواند به اطلاعات ارائهشده در بخشهای ابتدایی متن رجوع کند و در نتیجه تحلیل عمیقتری داشته باشد.
3. پشتیبانی از زمینههای پیچیده
در مکالمات یا متون چندبخشی، مدل باید بتواند ارتباط بین بخشهای مختلف متن را حفظ کند. Context Length بیشتر به مدل اجازه میدهد تا ساختار و انسجام متن را بهتر درک کند.
محدودیتهای طول زمینه
با وجود اهمیت Context Length، این مفهوم محدودیتهایی نیز دارد که در طراحی و استفاده از مدلهای زبانی باید مورد توجه قرار گیرد:
1. هزینه محاسباتی بالا
افزایش Context Length مستلزم پردازش تعداد بیشتری از توکنهاست که منجر به افزایش زمان و منابع محاسباتی میشود. این موضوع به خصوص در مدلهای بزرگ مانند GPT-4 یا GPT-3 قابل توجه است.
2. افزایش پیچیدگی مدل
مدلهایی با Context Length بلندتر نیازمند معماریهای پیچیدهتری هستند که ممکن است منجر به مشکلاتی مانند کاهش سرعت پردازش یا افزایش احتمال خطا شود.
کاربردهای عملی طول زمینه در مدلهای زبانی
طول زمینه در بسیاری از کاربردهای روزمره هوش مصنوعی نقش اساسی دارد. برخی از این کاربردها عبارتاند از:
- ترجمه ماشینی: ترجمه دقیقتر متنهای بلند با حفظ ساختار معنایی.
- پشتیبانی از مکالمات: ارائه پاسخهای مرتبط در گفتگوهای طولانی.
- تولید محتوا: تولید مقالهها و داستانهای طولانی با حفظ انسجام متن.
- تحلیل دادههای متنی: پردازش و تحلیل گزارشهای طولانی یا دادههای متنی حجیم.
چگونه طول زمینه در مدلهای زبانی تنظیم میشود؟
طول زمینه در مرحلهی طراحی مدل و آموزش آن تعیین میشود. برای مثال، مدل GPT-3 با Context Length معادل 2048 توکن دارد، در حالی که GPT-4 این عدد را به طور قابل توجهی افزایش داده است. این افزایش به مدل اجازه میدهد تا متنهای طولانیتر و پیچیدهتری را پردازش کند.
یکی از تکنیکهای رایج برای مدیریت Context Length، استفاده از مکانیزم توجه (Attention Mechanism) است. این مکانیزم به مدل کمک میکند تا بخشهای مهم متن را شناسایی و بر آنها تمرکز کند، حتی اگر Context Length محدود باشد.
آینده طول زمینه در مدلهای زبانی
با پیشرفت سریع در حوزه هوش مصنوعی، انتظار میرود که Context Length در مدلهای زبانی به طور مداوم افزایش یابد. این پیشرفت، امکان پردازش حجم بیشتری از دادهها را فراهم میکند و کاربردهای جدیدی مانند تحلیل اسناد حقوقی یا متون تاریخی را ممکن میسازد.
همچنین، تحقیقات در زمینه کاهش هزینههای محاسباتی و بهینهسازی عملکرد مدلها ادامه دارد تا استفاده از مدلهای با Context Length بالا برای کاربران و سازمانها مقرونبهصرفهتر شود.
مقایسه طول زمینه در مدلهای مختلف هوش مصنوعی
در این بخش، Context Length مدلهای معروف هوش مصنوعی بررسی و مقایسه میشود:
1. GPT-4 (OpenAI)
- توسعهدهنده: OpenAI
- طول زمینه: 32,768 توکن (در نسخههای پیشرفتهتر)
- ویژگیها:
- GPT-4 یکی از پیشرفتهترین مدلهای زبانی است که از Context Length بسیار بالایی برخوردار است.
- این مدل با طول زمینه 32,768 توکن میتواند متون بلند مانند اسناد علمی، کتابها و مکالمات طولانی را به خوبی پردازش کند.
- مناسب برای کاربردهای تجاری، تولید محتوا و تحلیل دادههای متنی.
2. Claude (Anthropic)
- توسعهدهنده: Anthropic
- طول زمینه: 100,000 توکن (در Claude 3)
- ویژگیها:
- Claude با طول زمینه 100,000 توکن، یکی از مدلهایی است که بیشترین توانایی را در پردازش متون طولانی دارد.
- این ویژگی به Claude اجازه میدهد تا اسناد بسیار طولانی و پیچیده را به طور کامل پردازش کند.
- تمرکز بر ایمنی و کاهش سوگیریها در پاسخدهی.
3. Gemini (Google DeepMind)
- توسعهدهنده: Google DeepMind
- طول زمینه: حدود 8,192 توکن (براساس گزارشهای موجود)
- ویژگیها:
- Gemini برای حل مسائل پیچیده و علمی طراحی شده و از Context Length نسبتاً متوسطی برخوردار است.
- این مدل برای کاربردهای تحقیقاتی و پردازش دادههای علمی مناسب است.
4. DeepSeek
- توسعهدهنده: DeepSeek
- طول زمینه: 16,384 توکن (در نسخه DeepSeek V3)
- ویژگیها:
- DeepSeek با تمرکز بر بهینهسازی منابع و کاهش هزینهها طراحی شده است.
- طول زمینه 16,384 توکن این مدل، آن را برای پردازش متون بلند و تحلیلهای جامع مناسب میسازد.
- هزینه پردازش در این مدل بسیار پایینتر از رقبای مشابه است.
5. Qwen (Ali Baba)
- توسعهدهنده: Ali Baba
- طول زمینه: بیش از 20,000 توکن
- ویژگیها:
- Qwen یک مدل چندمنظوره است که علاوه بر پردازش متون، قابلیت تحلیل تصاویر و ویدیوها را نیز دارد.
- طول زمینه بالای این مدل، آن را برای کاربردهای پیچیده مانند تحلیل دادههای چندرسانهای مناسب میسازد.
جدول مقایسه طول زمینه مدلهای هوش مصنوعی
| مدل | توسعهدهنده | طول زمینه (توکن) | ویژگیهای کلیدی |
|---|---|---|---|
| GPT-4 | OpenAI | 32,768 | تولید محتوا، مکالمات طولانی |
| Claude | Anthropic | 100,000 | پردازش اسناد بسیار طولانی، ایمنی بالا |
| Gemini | Google DeepMind | 8,192 | حل مسائل علمی، پردازش دادههای پیچیده |
| DeepSeek | DeepSeek | 16,384 | کاهش هزینهها، پردازش متون بلند |
| Qwen | Ali Baba | 20,000+ | تحلیل دادههای متنی و چندرسانهای |
تحلیل مقایسهای Context Length
Claude پیشرو در پردازش متون فوقبلند: با طول زمینه 100,000 توکن، Claude قابلیت منحصربهفردی در پردازش اسناد بسیار طولانی دارد و برای کاربردهایی مانند تحلیل اسناد حقوقی و تاریخی ایدهآل است.
GPT-4 برای کاربردهای عمومی و تجاری: با طول زمینه 32,768 توکن، GPT-4 انتخابی مناسب برای تولید محتوا، مکالمات طولانی و کاربردهای عمومی است.
DeepSeek و تمرکز بر بهینهسازی: با طول زمینه 16,384 توکن، DeepSeek علاوه بر توانایی پردازش متون بلند، هزینههای محاسباتی را نیز بهینه کرده است.
Qwen و تحلیل چندرسانهای: با طول زمینه بیش از 20,000 توکن، Qwen علاوه بر پردازش متون، قابلیتهای چندرسانهای پیشرفتهای نیز ارائه میدهد.
Gemini و تمرکز بر تحقیقات علمی: با طول زمینه 8,192 توکن، Gemini برای کاربردهای تحقیقاتی و حل مسائل پیچیده مناسب است.
نتیجهگیری
طول زمینه (Context Length) یکی از عوامل تعیینکننده در عملکرد مدلهای هوش مصنوعی است که تأثیر مستقیمی بر توانایی آنها در پردازش متون بلند و پیچیده دارد. مدلهایی مانند Claude با طول زمینه 100,000 توکن، در صدر این رقابت قرار دارند و برای کاربردهای تخصصی ایدهآل هستند. از سوی دیگر، مدلهایی مانند GPT-4 و DeepSeek نیز با Context Length قابل توجه و هزینههای بهینه، برای کاربردهای عمومی و تجاری مناسب هستند.
با پیشرفت مداوم در فناوری هوش مصنوعی، انتظار میرود که Context Length مدلها همچنان افزایش یابد و امکان پردازش دادههای بزرگتر و پیچیدهتر را فراهم کند. این پیشرفتها به توسعه کاربردهای جدیدی در حوزههایی مانند تحلیل اسناد حقوقی، تولید محتوا و مکالمات پیچیده کمک خواهد کرد.