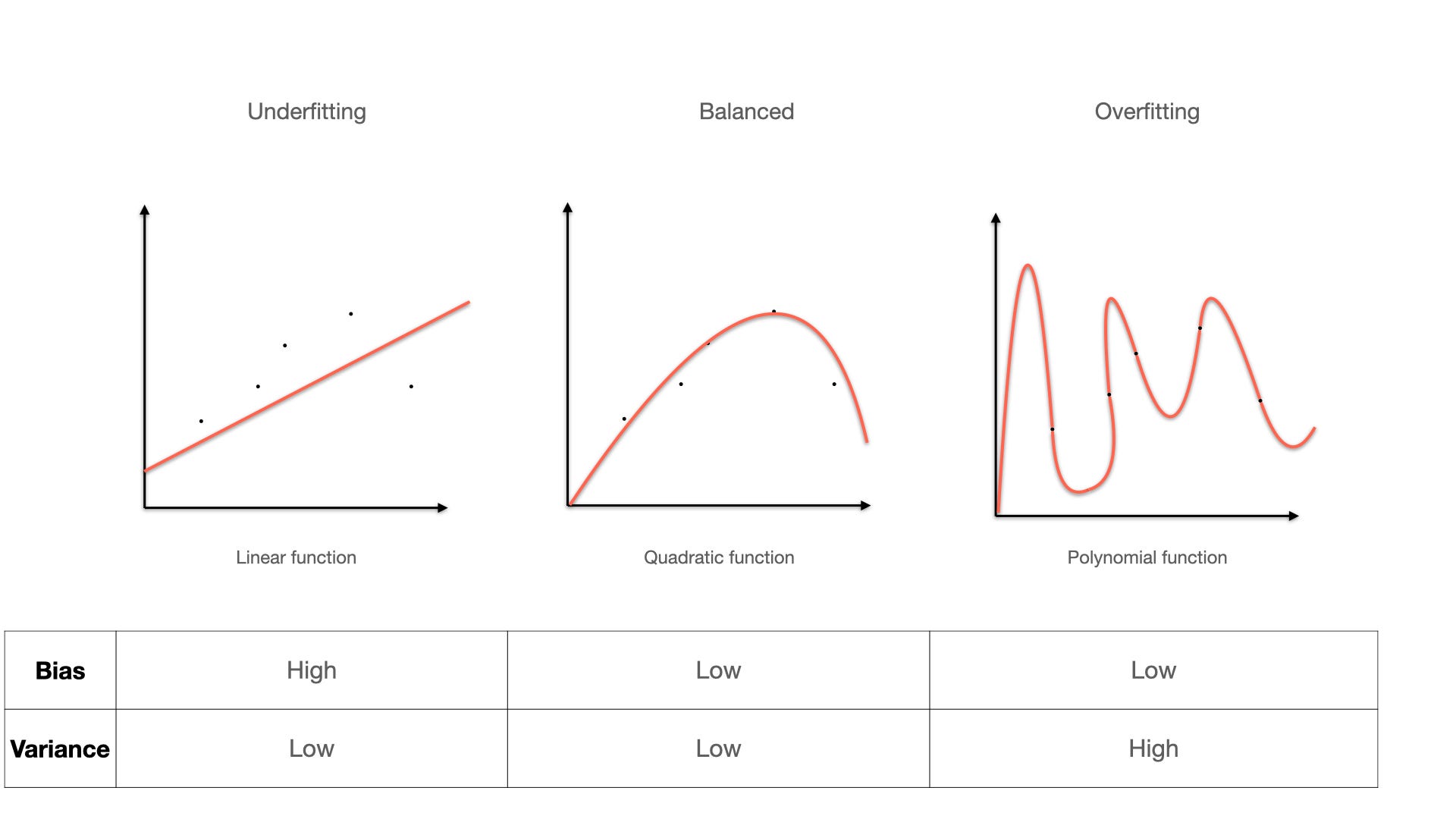
بیشبرازش یا Overfitting یکی از چالشهای اساسی در آموزش شبکههای عصبی عمیق است که زمانی رخ میدهد که مدل بهجای یادگیری الگوهای کلی، دادههای آموزشی را حفظ میکند و در نتیجه عملکرد ضعیفی روی دادههای جدید دارد. این مقاله به بررسی جامع تکنیکهای پیشگیری از بیشبرازش میپردازد و روشهایی همچون منظمسازی، Dropout، نرمالسازی دستهای، اعتبارسنجی متقاطع و توقف زودهنگام را با جزئیات کامل تشریح میکند.
مقدمه
شبکههای عصبی عمیق با میلیونها پارامتر قابل تنظیم، ابزارهای قدرتمندی برای حل مسائل پیچیده هستند. این قدرت محاسباتی همان عاملی است که میتواند منجر به بیشبرازش شود. بیشبرازش زمانی اتفاق میافتد که مدل الگوهای پیچیدهای را یاد میگیرد که تنها در دادههای آموزشی معتبر هستند و قابلیت تعمیم به دادههای جدید را ندارند.
برای درک بهتر این مفهوم، تصور کنید که به یک کودک مفهوم دایره را آموزش میدهید. اگر تنها دایرههای قرمز رنگ به او نشان دهید، ممکن است کودک فکر کند که رنگ قرمز جزئی از تعریف دایره است. این دقیقاً همان چیزی است که در بیشبرازش اتفاق میافتد – مدل جزئیات غیرضروری و نویز دادههای آموزشی را به عنوان الگوهای معتبر یاد میگیرد.
بخش اول: درک بیشبرازش
تعریف و مفاهیم پایه
بیشبرازش پدیدهای است که در آن مدل یادگیری ماشین عملکرد عالی روی دادههای آموزشی اما عملکرد ضعیف روی دادههای تست دارد. در اصطلاحات ریاضی، این وضعیت زمانی رخ میدهد که واریانس مدل بسیار بالا و بایاس آن پایین باشد.
علائم تشخیص بیشبرازش
شناسایی بیشبرازش از طریق چند روش امکانپذیر است:
۱. تحلیل منحنی یادگیری: زمانی که خطای آموزش به مقدار بسیار کمی میرسد اما خطای اعتبارسنجی افزایش مییابد، نشانهای از بیشبرازش است. در یک مدل سالم، هر دو منحنی باید روند مشابهی داشته باشند.
۲. اختلاف قابل توجه در دقت: اگر دقت مدل روی دادههای آموزشی ۹۵٪ و روی دادههای تست ۵۵٪ باشد، مدل دچار بیشبرازش شدید است.
۳. پیچیدگی بیش از حد: مدلهایی با تعداد پارامترهای بسیار بیشتر از نمونههای آموزشی مستعد بیشبرازش هستند.
عوامل ایجادکننده بیشبرازش
عوامل متعددی میتوانند منجر به بیشبرازش شوند:
- پیچیدگی بیش از حد مدل: شبکههای عمیق با لایههای زیاد و نورونهای فراوان ظرفیت بالایی برای حفظ کردن دادهها دارند
- دادههای آموزشی محدود: زمانی که تعداد نمونههای آموزشی کافی نباشد
- نویز در دادهها: وجود دادههای نامعتبر یا پرت در مجموعه آموزشی
- آموزش طولانیمدت: ادامه آموزش بیش از حد معمول
بخش دوم: تکنیکهای منظمسازی (Regularization)
منظمسازی مجموعهای از تکنیکهاست که با افزودن قیدهایی به فرآیند آموزش، مدل را وادار به سادگی بیشتر میکند.
L2 (Ridge Regularization)
منظمسازی L2، که اغلب با نام Weight Decay نیز شناخته میشود، یکی از رایجترین روشهای منظمسازی است. در این روش، یک جمله جریمه به تابع هزینه اضافه میشود:
L_total = L_original + λ * Σ(w²)
که در آن:
- L_total: تابع هزینه کل
- L_original: تابع هزینه اصلی
- λ: ضریب منظمسازی (معمولاً بین ۰.۰۰۰۱ تا ۰.۱)
- w: وزنهای شبکه
مکانیزم عملکرد: منظمسازی L2 با جریمه کردن وزنهای بزرگ، مدل را تشویق میکند که از وزنهای کوچکتر استفاده کند. این کار باعث میشود مدل به هیچ ویژگی خاصی وابستگی زیادی نداشته باشد.
نکات کلیدی:
- وزنها به سمت صفر کشیده میشوند اما هرگز دقیقاً صفر نمیشوند
- مناسب برای شبکههای عصبی و یادگیری عمیق
- مقادیر معمول λ: ۰.۰۰۰۵، ۰.۰۰۱، ۰.۰۱
منظمسازی L1 (Lasso Regularization)
در منظمسازی L1، مجموع قدر مطلق وزنها به تابع هزینه اضافه میشود:
L_total = L_original + λ * Σ|w|
تفاوت کلیدی با L2: منظمسازی L1 میتواند وزنهای برخی ویژگیها را دقیقاً صفر کند، در حالی که L2 تنها آنها را کوچک میکند. این ویژگی L1 را به ابزاری مناسب برای انتخاب ویژگی تبدیل میکند.
کاربردها:
- زمانی که ویژگیهای زیادی دارید و میخواهید مهمترینها را شناسایی کنید
- ایجاد مدلهای پراکنده (Sparse Models)
- کاهش پیچیدگی محاسباتی
منظمسازی Elastic Net
Elastic Net ترکیبی از L1 و L2 است:
L_total = L_original + λ₁ * Σ|w| + λ₂ * Σ(w²)
این روش مزایای هر دو تکنیک را ترکیب میکند و برای مسائل با ویژگیهای همخط (Collinear) مناسب است.
تفاوت Weight Decay و منظمسازی L2
اگرچه برای الگوریتم SGD ساده این دو معادل هستند، اما در بهینهسازهای پیشرفته مانند Adam تفاوت دارند:
منظمسازی L2: جمله منظمسازی را به گرادیان اضافه میکند Weight Decay: مستقیماً در مرحله بهروزرسانی وزنها اعمال میشود
برای استفاده با Adam، نسخه AdamW (Adam با Weight Decay) توصیه میشود که عملکرد بهتری دارد.
بخش سوم: Dropout – منظمسازی از طریق حذف تصادفی
مفهوم و اصول Dropout
Dropout یکی از موثرترین تکنیکهای منظمسازی برای شبکههای عصبی عمیق است که در سال ۲۰۱۴ توسط Srivastava و همکاران معرفی شد. در این روش، در طول آموزش، بخشی از نورونها بهصورت تصادفی غیرفعال میشوند.
مکانیزم عملکرد: در هر مرحله آموزش، هر نورون با احتمال p فعال میماند و با احتمال (1-p) حذف میشود. این باعث میشود که شبکه نتواند به نورونهای خاصی وابسته شود.
چرا Dropout موثر است؟
۱. جلوگیری از همسازگاری (Co-adaptation): نورونها نمیتوانند روی یکدیگر تکیه کنند و باید بهصورت مستقل ویژگیهای مفید یاد بگیرند.
۲. اثر مجموعهسازی (Ensemble Effect): Dropout معادل آموزش چندین شبکه مختلف و میانگینگیری از نتایج آنهاست.
۳. کاهش پیچیدگی موثر: در هر تکرار، شبکه کوچکتری آموزش میبیند.
پیادهسازی Dropout
در مرحله آموزش:
# هر نورون با احتمال p نگهداشته میشود
output = input * mask / p
# که mask آرایهای از اعداد ۰ و ۱ است
در مرحله استنتاج: از تمام نورونها استفاده میشود بدون هیچ تغییری (یا در روش Inverted Dropout، مقیاسبندی در آموزش انجام میشود).
انتخاب نرخ Dropout
نرخ Dropout معمولاً بین ۰.۲ تا ۰.۵ انتخاب میشود:
- ۰.۲ تا ۰.۳: برای لایههای اولیه و لایههای کانولوشنی
- ۰.۵: برای لایههای کاملاً متصل (Fully Connected)
- بالاتر از ۰.۵: معمولاً توصیه نمیشود زیرا ممکن است مانع یادگیری شود
ملاحظات مهم
- Dropout زمان آموزش را افزایش میدهد زیرا شبکه برای همگرایی به تکرارهای بیشتری نیاز دارد
- برای لایههای کانولوشنی، نرخ Dropout پایینتر استفاده میشود
- در شبکههای بازگشتی (RNN/LSTM)، Dropout باید با دقت بیشتری اعمال شود
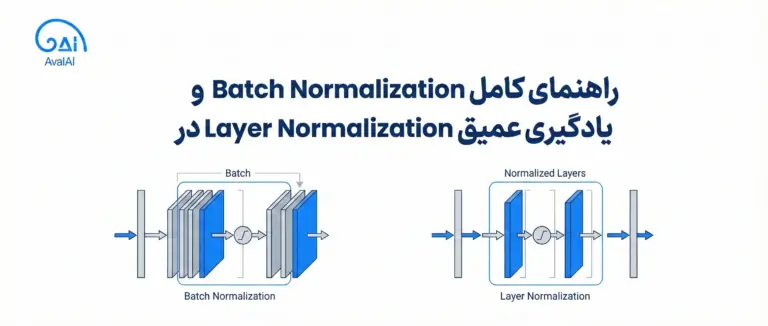
بخش چهارم: نرمالسازی دستهای (Batch Normalization)
مفهوم و کاربرد
نرمالسازی دستهای، که توسط Ioffe و Szegedy در سال ۲۰۱۵ معرفی شد، در ابتدا برای تسریع آموزش طراحی شد اما اثر منظمسازی نیز دارد.
عملکرد اصلی: نرمالسازی دستهای خروجیهای هر لایه را نرمال میکند تا میانگین صفر و واریانس یک داشته باشند:
x_normalized = (x - μ_batch) / √(σ²_batch + ε)
y = γ * x_normalized + β
که در آن:
- μ_batch: میانگین دسته
- σ²_batch: واریانس دسته
- ε: عدد کوچکی برای پایداری عددی
- γ و β: پارامترهای قابل یادگیری
مزایای نرمالسازی دستهای
۱. تسریع آموزش: امکان استفاده از نرخ یادگیری بالاتر ۲. کاهش وابستگی به مقداردهی اولیه: شبکه کمتر به وزنهای اولیه حساس است ۳. اثر منظمسازی: با افزودن نویز از طریق آمار دستهای، از بیشبرازش جلوگیری میکند ۴. کاهش نیاز به سایر تکنیکهای منظمسازی: گاهی نیاز به Dropout را کاهش میدهد
رابطه با Dropout
استفاده همزمان از Batch Normalization و Dropout موضوع بحثبرانگیزی است:
نکات کلیدی:
- در مقالات قدیمیتر، توالی Dropout → BatchNorm پیشنهاد میشد
- تحقیقات جدیدتر نشان میدهند BatchNorm → Dropout میتواند بهتر باشد
- برخی معماریها (مانند ResNet و DenseNet) تنها از BatchNorm استفاده میکنند
- ترکیب این دو میتواند منجر به ناهماهنگی واریانس شود
توصیه عملی: ابتدا تنها BatchNorm را امتحان کنید. اگر هنوز بیشبرازش وجود دارد، Dropout اضافه کنید.
محل قرارگیری در شبکه
نرمالسازی دستهای معمولاً بعد از لایه کانولوشنی یا کاملاً متصل و قبل از تابع فعالسازی قرار میگیرد:
Input → Conv/Dense → BatchNorm → Activation → Dropout (اختیاری)
بخش پنجم: توقف زودهنگام (Early Stopping)
مفهوم و اهمیت
توقف زودهنگام سادهترین اما موثرترین تکنیک منظمسازی است. ایده آن این است که آموزش را قبل از اینکه مدل شروع به یادگیری نویز کند، متوقف کنیم.
مکانیزم عملکرد
در طول آموزش، عملکرد مدل روی مجموعه اعتبارسنجی نظارت میشود:
۱. مرحله اولیه: خطای آموزش و اعتبارسنجی هر دو کاهش مییابند ۲. نقطه بهینه: کمترین خطای اعتبارسنجی حاصل میشود ۳. بیشبرازش: خطای آموزش همچنان کاهش مییابد اما خطای اعتبارسنجی افزایش مییابد
توقف زودهنگام در نقطه ۲ فعال میشود.
پیادهسازی عملی
# شبه کد توقف زودهنگام
best_val_loss = infinity
patience_counter = 0
patience = 10 # تعداد epochهای صبر
for epoch in training:
train_model()
val_loss = evaluate_on_validation()
if val_loss < best_val_loss:
best_val_loss = val_loss
save_model()
patience_counter = 0
else:
patience_counter += 1
if patience_counter >= patience:
break # توقف آموزش
restore_best_model()
پارامترهای مهم
۱. Patience: تعداد epochهایی که اجازه میدهیم بدون بهبود عملکرد ادامه یابد (معمولاً ۵-۲۰)
۲. Minimum Delta: حداقل تغییر در خطا که بهعنوان بهبود در نظر گرفته میشود
۳. Restore Best Weights: آیا بهترین وزنها بازیابی شوند یا وزنهای آخر استفاده شود
مزایا و معایب
مزایا:
- پیادهسازی بسیار ساده
- کاهش زمان آموزش
- عدم نیاز به تنظیم پارامترهای پیچیده
معایب:
- ممکن است آموزش را زودتر از موعد متوقف کند
- نیاز به مجموعه اعتبارسنجی مناسب
بخش ششم: افزایش داده (Data Augmentation)
اهمیت و کاربرد
یکی از راههای اساسی برای جلوگیری از بیشبرازش، افزایش حجم دادههای آموزشی است. زمانی که دسترسی به دادههای بیشتر میسر نیست، افزایش داده راهحل مناسبی است.
تکنیکهای افزایش داده در پردازش تصویر
۱. تبدیلات هندسی:
- چرخش (Rotation): چرخاندن تصویر با زوایای مختلف
- تغییر مکان (Translation): جابجایی تصویر
- برگردان (Flipping): انعکاس افقی یا عمودی
- بزرگنمایی (Scaling): تغییر اندازه تصویر
- برش (Cropping): استخراج بخشی از تصویر
۲. تبدیلات رنگی:
- تغییر روشنایی (Brightness adjustment)
- تغییر کنتراست (Contrast adjustment)
- اشباع رنگ (Color saturation)
- تغییر رنگها (Hue shift)
۳. افزودن نویز:
- نویز گاوسی
- نویز نمک و فلفل
- تار کردن (Blur)
اصول مهم در افزایش داده
۱. حفظ برچسب: تبدیلات نباید معنای برچسب را تغییر دهند ۲. واقعگرایی: تبدیلات باید نزدیک به دادههای واقعی باشند ۳. تنوع: استفاده از ترکیبهای مختلف تبدیلات
تاثیر بر بیشبرازش
افزایش داده باعث میشود:
- مدل الگوهای متنوعتری ببیند
- وابستگی به ویژگیهای خاص کاهش یابد
- تعمیمپذیری بهبود یابد
بخش هفتم: اعتبارسنجی متقاطع (Cross-Validation)
مفهوم کلی
اعتبارسنجی متقاطع تکنیکی برای ارزیابی دقیقتر عملکرد مدل و کاهش بیشبرازش است.
K-Fold Cross-Validation
رایجترین نوع اعتبارسنجی متقاطع است:
مراحل اجرا: ۱. تقسیم داده به k بخش مساوی (معمولاً k=5 یا k=10) ۲. در هر تکرار، k-1 بخش برای آموزش و یک بخش برای اعتبارسنجی استفاده میشود ۳. این فرآیند k بار تکرار میشود ۴. میانگین نتایج محاسبه میشود
مزایای اعتبارسنجی متقاطع
۱. ارزیابی قابل اعتمادتر: از تمام دادهها برای آموزش و ارزیابی استفاده میشود ۲. کاهش وابستگی به تقسیم خاص: نتایج وابسته به یک تقسیم تصادفی نیست ۳. شناسایی بهتر بیشبرازش: تغییرات زیاد در عملکرد بین foldها نشانه بیشبرازش است
Stratified K-Fold
در مسائل طبقهبندی، این روش تضمین میکند که نسبت کلاسها در هر fold حفظ شود:
- مناسب برای دادههای نامتعادل
- ارزیابی دقیقتر برای هر کلاس
اعتبارسنجی تودرتو (Nested Cross-Validation)
برای جلوگیری از بیشبرازش در تنظیم فراپارامترها:
- یک حلقه بیرونی برای ارزیابی مدل
- یک حلقه درونی برای انتخاب فراپارامترها
این روش تضمین میکند که فراپارامترها بر اساس دادههای مستقل از ارزیابی نهایی انتخاب میشوند.
بخش هشتم: سایر تکنیکهای موثر
کاهش پیچیدگی مدل
۱. حذف لایهها: کاهش تعداد لایههای شبکه ۲. کاهش نورونها: کاهش تعداد نورونها در هر لایه ۳. استفاده از معماری سادهتر: شروع با مدل ساده و پیچیدهسازی تدریجی
انتخاب ویژگی (Feature Selection)
حذف ویژگیهای غیرمهم یا زائد:
- کاهش ابعاد داده
- تمرکز بر ویژگیهای مهم
- کاهش نویز
روشهای مجموعهسازی (Ensemble Methods)
۱. Bagging: آموزش چندین مدل مستقل و میانگینگیری ۲. Boosting: آموزش متوالی مدلها با تمرکز بر خطاهای قبلی ۳. Stacking: ترکیب خروجی مدلهای مختلف با یک مدل فرا
این روشها با ترکیب پیشبینیهای متنوع، واریانس را کاهش میدهند.
MaxNorm Constraint
محدود کردن بزرگی بردار وزن هر نورون:
if ||w|| > c:
w = w * c / ||w||
که c معمولاً بین ۳ تا ۴ انتخاب میشود.
بخش نهم: ترکیب تکنیکها و بهترین شیوهها
استراتژی چندلایه
استفاده همزمان از چند تکنیک معمولاً بهترین نتایج را میدهد:
۱. معماری پیشنهادی برای CNN:
Input → Conv2D → BatchNorm → ReLU → MaxPool
→ Conv2D → BatchNorm → ReLU → MaxPool
→ Flatten → Dense → Dropout(0.5) → Dense
۲. افزودن منظمسازی L2: به لایههای Dense با ضریب ۰.۰۰۱ تا ۰.۰۱
۳. استفاده از افزایش داده: در مرحله بارگذاری دادهها
۴. اعمال توقف زودهنگام: با patience مناسب (۱۰-۲۰ epoch)
توصیههای عملی
۱. شروع ساده: ابتدا با سادهترین تکنیکها (توقف زودهنگام، منظمسازی L2) شروع کنید
۲. نظارت مداوم: همیشه منحنیهای یادگیری را بررسی کنید و تفاوت بین خطای آموزش و اعتبارسنجی را زیر نظر داشته باشید
۳. تنظیم تدریجی: فراپارامترها را بهصورت تدریجی تنظیم کنید، نه همهی آنها را همزمان
۴. استفاده از Transfer Learning: در صورت امکان، از مدلهای پیشآموزشدیده استفاده کنید که کمتر مستعد بیشبرازش هستند
۵. ثبت آزمایشها: تمام پیکربندیها و نتایج را ثبت کنید تا بهترین ترکیب را شناسایی کنید
انتخاب تکنیک مناسب بر اساس نوع مسئله
برای دادههای تصویری:
- افزایش داده (ضروری)
- Batch Normalization
- Dropout در لایههای کاملاً متصل
- منظمسازی L2 با ضریب کوچک (۰.۰۰۰۵)
دادههای متنی:
- Dropout در لایههای Embedding و RNN
- منظمسازی L2
- توقف زودهنگام
دادههای جدولی:
- منظمسازی L1 یا L2
- انتخاب ویژگی
- Cross-validation
- Ensemble methods
بخش دهم: مطالعات موردی و نتایج تجربی
مطالعه موردی ۱: طبقهبندی تصاویر CIFAR-10
یک شبکه CNN با معماری زیر در نظر بگیرید:
مدل پایه (بدون منظمسازی):
- دقت آموزش: ۹۸٪
- دقت تست: ۶۵٪
- وضعیت: بیشبرازش شدید
پس از افزودن Batch Normalization:
- دقت آموزش: ۹۵٪
- دقت تست: ۷۸٪
- بهبود: ۱۳٪
افزودن Dropout (0.5):
- دقت آموزش: ۹۱٪
- دقت تست: ۸۲٪
- بهبود: ۴٪
افزودن افزایش داده:
- دقت آموزش: ۸۸٪
- دقت تست: ۸۵٪
- بهبود: ۳٪
نتیجه: ترکیب تکنیکها دقت تست را ۲۰٪ بهبود داد.
مطالعه موردی ۲: مقایسه منظمسازیها
آزمایش روی یک شبکه عصبی با ۱۰۰۰ پارامتر و ۵۰۰ نمونه آموزشی:
بدون منظمسازی:
- Loss آموزش: ۰.۱۰
- Loss تست: ۰.۶۵
L2 Regularization (λ=0.01):
- Loss آموزش: ۰.۲۵
- Loss تست: ۰.۳۵
Dropout (p=0.5):
- Loss آموزش: ۰.۲۸
- Loss تست: ۰.۳۲
L2 + Dropout:
- Loss آموزش: ۰.۳۰
- Loss تست: ۰.۲۸
مطالعه موردی ۳: تاثیر نرخ Dropout
بررسی عملکرد با نرخهای مختلف Dropout:
| نرخ Dropout | دقت آموزش | دقت تست | زمان همگرایی |
|---|---|---|---|
| 0.0 | 99% | 68% | 50 epoch |
| 0.2 | 95% | 79% | 70 epoch |
| 0.5 | 88% | 84% | 100 epoch |
| 0.7 | 78% | 76% | 150+ epoch |
نتیجهگیری: نرخ ۰.۵ بهترین تعادل بین عملکرد و زمان آموزش را دارد.
بخش یازدهم: چالشها و محدودیتها
چالشهای رایج
۱. تعادل بین Underfitting و Overfitting: یافتن نقطه بهینه بین دو حالت میتواند دشوار باشد. منظمسازی بیش از حد میتواند منجر به کمبرازش شود.
۲. هزینه محاسباتی: برخی تکنیکها مانند Dropout و افزایش داده زمان آموزش را افزایش میدهند. Cross-validation نیز میتواند بسیار زمانبر باشد.
۳. تنظیم فراپارامترها: هر تکنیک فراپارامترهای خود را دارد که باید تنظیم شوند:
- λ برای منظمسازی
- نرخ Dropout
- Patience برای توقف زودهنگام
- تعداد foldها در cross-validation
۴. وابستگی به داده: تکنیکهای مختلف برای انواع مختلف داده عملکرد متفاوتی دارند. آنچه برای دادههای تصویری کار میکند، ممکن است برای دادههای متنی مناسب نباشد.
محدودیتهای شناختهشده
۱. ناسازگاری Batch Normalization و Dropout: استفاده همزمان از این دو ممکن است به دلیل تغییر واریانس منجر به نتایج ناخواسته شود.
۲. افزایش داده در مسائل غیرتصویری: در بسیاری از حوزهها، تولید دادههای معتبر جدید دشوار است.
۳. Cross-validation برای مدلهای بزرگ: برای مدلهای عمیق با میلیونها پارامتر، اجرای cross-validation میتواند غیرعملی باشد.
بخش دوازدهم: روندهای نوین و تحقیقات آینده
تکنیکهای نوین
۱. Mixup و CutMix: روشهای پیشرفته افزایش داده که تصاویر را با هم ترکیب میکنند:
- Mixup: میانگینگیری خطی از تصاویر
- CutMix: جایگذاری بخشی از یک تصویر در تصویر دیگر
۲. DropBlock: نسخه ساختاریافتهتر از Dropout برای شبکههای کانولوشنی که بلوکهای پیوسته از فیچرمپ را حذف میکند.
۳. Sharpness-Aware Minimization (SAM): بهینهسازی که به دنبال مینیممهای flatتر است که معمولاً بهتر تعمیم مییابند.
۴. Self-Supervised Learning: پیشآموزش مدلها روی وظایف خودنظارتی که نیاز به برچسب ندارند، سپس Fine-tuning روی دادههای برچسبدار محدود.
پژوهشهای اخیر
۱. Double Descent Phenomenon: کشف جدید که نشان میدهد مدلهای بسیار بزرگ میتوانند از مرحله بیشبرازش عبور کنند و دوباره عملکرد خوبی داشته باشند.
۲. Lottery Ticket Hypothesis: نظریهای که میگوید در شبکههای بزرگ، زیرشبکههای کوچکی وجود دارند که میتوانند بهتنهایی عملکرد خوبی داشته باشند.
۳. Neural Architecture Search (NAS): استفاده از الگوریتمها برای یافتن خودکار معماریهایی که کمتر مستعد بیشبرازش هستند.
مسیرهای تحقیقاتی آینده
۱. منظمسازی تطبیقی: روشهایی که بهصورت خودکار قدرت منظمسازی را در طول آموزش تنظیم میکنند.
۲. تئوری بهتر: درک عمیقتر از چرایی عملکرد تکنیکهای مختلف و چگونگی تعامل آنها.
۳. روشهای کارآمدتر: تکنیکهایی که منظمسازی موثر را با هزینه محاسباتی کمتر ارائه دهند.
بخش سیزدهم: راهنمای عملی پیادهسازی
دستورالعمل گامبهگام
مرحله ۱: تشخیص مشکل
# بررسی منحنیهای یادگیری
plot_learning_curves(train_loss, val_loss)
# محاسبه اختلاف عملکرد
gap = train_accuracy - val_accuracy
if gap > 0.15:
print("بیشبرازش احتمالی")
۲: انتخاب تکنیک اولیه
# افزودن منظمسازی L2
model.add(Dense(128,
kernel_regularizer=l2(0.01),
activation='relu'))
# افزودن Dropout
model.add(Dropout(0.5))
# استفاده از Batch Normalization
model.add(BatchNormalization())
۳: تنظیم فراپارامترها
# Grid Search برای یافتن بهترین ترکیب
param_grid = {
'dropout_rate': [0.2, 0.3, 0.5],
'l2_lambda': [0.001, 0.01, 0.1],
'learning_rate': [0.001, 0.0001]
}
۴: ارزیابی و تکرار
# اعتبارسنجی متقاطع
cv_scores = cross_val_score(model, X, y, cv=5)
print(f"میانگین دقت: {cv_scores.mean():.3f}")
print(f"انحراف معیار: {cv_scores.std():.3f}")
نمونه کد کامل
import tensorflow as tf
from tensorflow.keras import layers, regularizers
from tensorflow.keras.callbacks import EarlyStopping
def build_regularized_model(input_shape, num_classes):
"""
ساخت یک مدل با تکنیکهای منظمسازی مختلف
"""
model = tf.keras.Sequential([
# لایه ورودی
layers.Input(shape=input_shape),
# لایه کانولوشنی اول با L2
layers.Conv2D(32, (3, 3),
kernel_regularizer=regularizers.l2(0.001)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.MaxPooling2D((2, 2)),
# لایه کانولوشنی دوم
layers.Conv2D(64, (3, 3),
kernel_regularizer=regularizers.l2(0.001)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.MaxPooling2D((2, 2)),
# لایههای کاملاً متصل
layers.Flatten(),
layers.Dense(128,
kernel_regularizer=regularizers.l2(0.01)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.Dropout(0.5),
# لایه خروجی
layers.Dense(num_classes, activation='softmax')
])
return model
# ساخت مدل
model = build_regularized_model((32, 32, 3), 10)
# کامپایل با AdamW (Adam با Weight Decay)
model.compile(
optimizer=tf.keras.optimizers.AdamW(learning_rate=0.001,
weight_decay=0.0001),
loss='categorical_crossentropy',
metrics=['accuracy']
)
# توقف زودهنگام
early_stop = EarlyStopping(
monitor='val_loss',
patience=10,
restore_best_weights=True,
verbose=1
)
# آموزش با افزایش داده
datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rotation_range=15,
width_shift_range=0.1,
height_shift_range=0.1,
horizontal_flip=True
)
# آموزش مدل
history = model.fit(
datagen.flow(X_train, y_train, batch_size=32),
validation_data=(X_val, y_val),
epochs=100,
callbacks=[early_stop]
)
چکلیست عملی
قبل از شروع آموزش:
- [ ] دادهها را به مجموعههای آموزش، اعتبارسنجی و تست تقسیم کنید
- [ ] دادهها را نرمالسازی کنید
- [ ] افزایش داده را پیادهسازی کنید (در صورت نیاز)
هنگام طراحی مدل:
- [ ] با معماری ساده شروع کنید
- [ ] Batch Normalization اضافه کنید
- [ ] منظمسازی L2 به لایههای Dense اضافه کنید
- [ ] Dropout به لایههای کاملاً متصل اضافه کنید
در طول آموزش:
- [ ] توقف زودهنگام را فعال کنید
- [ ] منحنیهای یادگیری را نظارت کنید
- [ ] نرخ یادگیری را تنظیم کنید (Learning Rate Scheduling)
پس از آموزش:
- [ ] عملکرد روی مجموعه تست را ارزیابی کنید
- [ ] فراپارامترها را تنظیم کنید
- [ ] Cross-validation انجام دهید
نتیجهگیری
بیشبرازش یکی از چالشهای اساسی در یادگیری عمیق است که نیازمند رویکردی چندجانبه برای مقابله با آن است. هیچ راهحل واحدی برای تمام مسائل وجود ندارد، بلکه ترکیب مناسبی از تکنیکهای مختلف بر اساس ویژگیهای خاص مسئله مورد نیاز است.
نکات کلیدی
۱. تشخیص زودهنگام: نظارت مداوم بر منحنیهای یادگیری و شناسایی علائم بیشبرازش در مراحل اولیه
۲. رویکرد تدریجی: شروع با تکنیکهای ساده و افزودن پیچیدگی در صورت نیاز
۳. ترکیب هوشمندانه: استفاده همزمان از چند تکنیک با در نظر گرفتن تعاملات بین آنها
۴. تنظیم دقیق: صرف زمان برای یافتن بهترین فراپارامترها از طریق جستجوی سیستماتیک
۵. اعتبارسنجی جامع: استفاده از cross-validation برای اطمینان از تعمیمپذیری مدل
توصیههای نهایی
برای موفقیت در مقابله با بیشبرازش:
- داده کافی جمعآوری کنید: بیشترین داده ممکن را جمعآوری و در صورت امکان از افزایش داده استفاده کنید
- از Transfer Learning بهره ببرید: مدلهای پیشآموزشدیده میتوانند با دادههای کمتر عملکرد بهتری داشته باشند
- صبور باشید: یافتن ترکیب بهینه تکنیکها زمان میبرد و نیاز به آزمون و خطا دارد
- مستندسازی کنید: تمام آزمایشها و نتایج را ثبت کنید تا الگوهای موفق را شناسایی کنید
- بهروز باشید: تحقیقات در این حوزه به سرعت پیش میرود، همیشه مقالات جدید را دنبال کنید