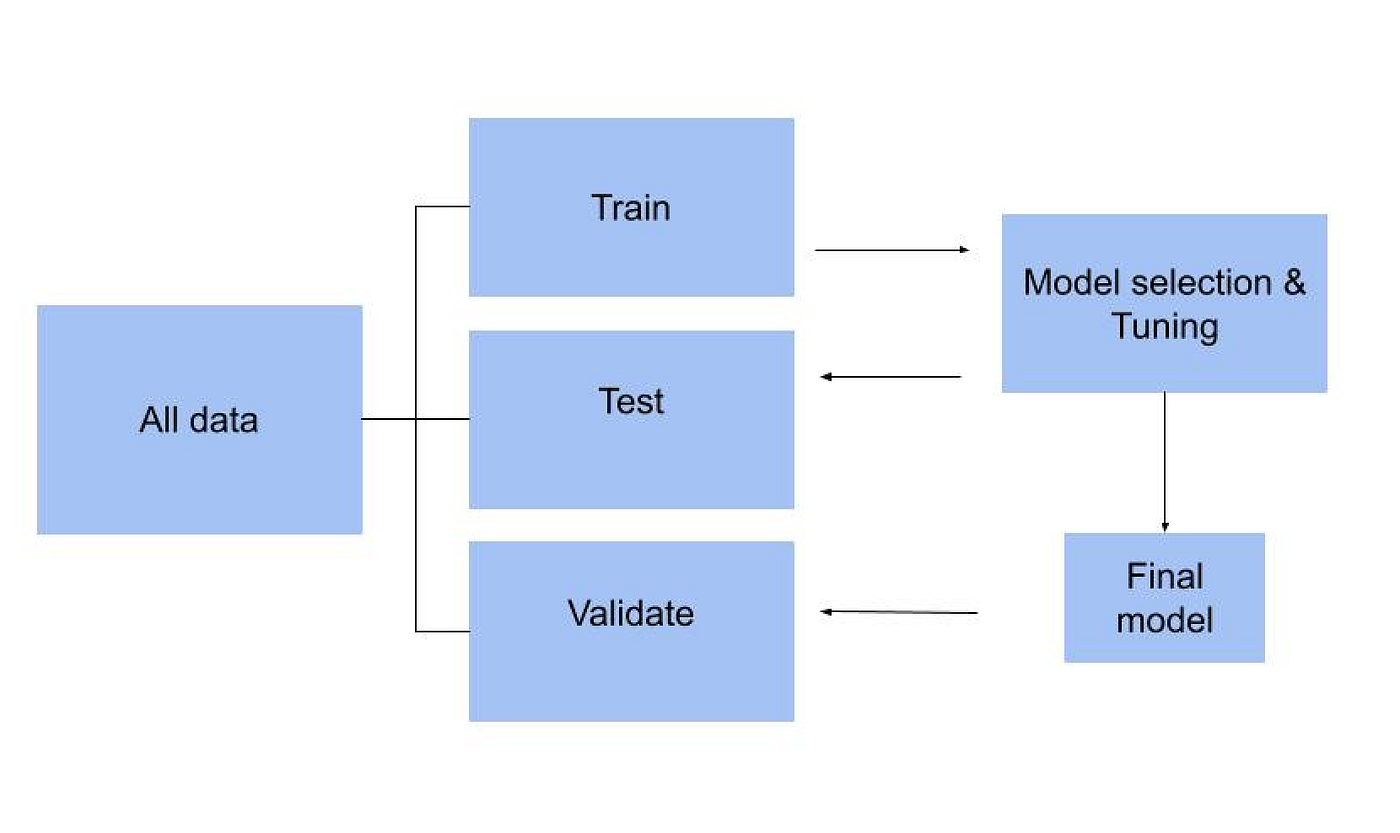
در یادگیری ماشین، ارزیابی دقیق عملکرد مدلها بر روی دادههای دیدهنشده یکی از چالشهای اساسی است. اعتبارسنجی متقابل (Cross-Validation) بهعنوان یک تکنیک استاندارد برای برآورد قابلیت تعمیمپذیری مدلها شناخته میشود. این مقاله به بررسی جامع مفهوم، انواع، مزایا، معایب و کاربردهای عملی روشهای مختلف اعتبارسنجی متقابل میپردازد و راهنمای کاملی برای استفاده صحیح از این تکنیکها ارائه میدهد.
مقدمه
تعریف اعتبارسنجی متقابل
اعتبارسنجی متقابل یک روش ارزیابی آماری است که برای تخمین مهارت مدلهای یادگیری ماشین بر روی دادههای دیدهنشده بهکار میرود. این روش که گاهی با نامهای برآورد دَوَرانی (Rotation Estimation) یا آزمون خارج از نمونه (Out-of-Sample Testing) نیز شناخته میشود، تعیین میکند که نتایج یک تحلیل آماری تا چه اندازه میتواند به مجموعه دادههای مستقل تعمیم یابد.
ضرورت استفاده از اعتبارسنجی متقابل
در مدلسازی یادگیری ماشین، آموزش و ارزیابی مدل بر روی یک مجموعه داده واحد یک اشتباه روششناختی محسوب میشود. مدلی که صرفاً برچسبهای نمونههای آموزشی را حفظ کند، در دادههای آموزشی عملکرد بینقصی خواهد داشت، اما در پیشبینی دادههای جدید شکست میخورد. این پدیده را بیشبرازش (Overfitting) مینامیم.
اعتبارسنجی متقابل با تقسیم دادهها به زیرمجموعههای مختلف و آموزش و ارزیابی مکرر مدل، برآوردی قابلاعتمادتر از عملکرد واقعی مدل ارائه میدهد و از مشکلات بیشبرازش و کمبرازش (Underfitting) جلوگیری میکند.
اصول بنیادین اعتبارسنجی متقابل
مفاهیم پایه
در فرآیند اعتبارسنجی متقابل، دادهها به دو یا چند زیرمجموعه تقسیم میشوند:
دادههای آموزشی (Training Set): از این بخش برای آموزش مدل و برآورد پارامترهای آن استفاده میشود.
دادههای آزمایشی (Test Set): این بخش برای ارزیابی کارایی مدل بهکار میرود و شامل مشاهداتی است که در فرآیند آموزش استفاده نشدهاند.
خطای درون نمونه و خارج از نمونه
خطای درون نمونه (In-Sample Error): خطایی که مدل بر روی دادههای آموزشی نشان میدهد. این خطا معمولاً برآوردی متعصبانه و خوشبینانه از عملکرد واقعی مدل است.
خطای خارج از نمونه (Out-of-Sample Error): خطایی که در اعتبارسنجی متقابل برآورد میشود و نشاندهنده عملکرد مدل بر روی دادههای دیدهنشده است. این معیار قابلاعتمادتری برای ارزیابی توانایی تعمیمپذیری مدل محسوب میشود.
چرا دادههای seen و unseen مهم هستند؟
برای درک بهتر، تصور کنید دانشآموزی که برای امتحان ریاضی آماده میشود. اگر تنها نمونه سوالاتی را که قبلاً دیده حل کند، ممکن است آنها را حفظ کرده باشد ولی توانایی حل مسائل جدید را نداشته باشد. اعتبارسنجی متقابل مانند امتحانی است که با سوالات جدید، توانایی واقعی مدل را میسنجد.
انواع روشهای اعتبارسنجی متقابل
۱. روش نگهداشتن (Hold-Out Method)
تعریف و نحوه عملکرد
سادهترین و پرکاربردترین روش اعتبارسنجی است. در این روش، دادهها بهطور تصادفی به دو بخش آموزش و آزمون تقسیم میشوند. نسبت معمول ۸۰٪ برای آموزش و ۲۰٪ برای آزمون است، اگرچه نسبتهای ۷۰-۳۰ یا ۶۰-۴۰ نیز رایج هستند.
مراحل اجرا
- مجموعه داده را بهطور تصادفی مخلوط کنید
- دادهها را به دو بخش آموزشی و تست تقسیم کنید
- مدل را با مجموعه آموزشی آموزش دهید
- عملکرد مدل را با دادههای تست ارزیابی کنید
- نتیجه اعتبارسنجی را ذخیره کنید
مزایا و معایب
مزایا:
- سادگی در پیادهسازی و درک
- سرعت بالای اجرا
- مصرف محاسباتی کم
معایب:
- حساسیت به نحوه تقسیم تصادفی دادهها
- استفاده ناکارآمد از دادهها (بخشی از داده برای آموزش استفاده نمیشود)
- واریانس بالا در برآورد عملکرد
- ممکن است برای مجموعه دادههای کوچک مناسب نباشد
۲. اعتبارسنجی متقابل K-Fold
تعریف و مفهوم
در این روش که محبوبترین و پرکاربردترین تکنیک اعتبارسنجی است، مجموعه داده به K زیرمجموعه مساوی (fold) تقسیم میشود. فرآیند آموزش و ارزیابی K بار تکرار میشود، بهطوری که در هر تکرار یکی از زیرمجموعهها برای آزمون و K-1 زیرمجموعه باقیمانده برای آموزش استفاده میشوند.
الگوریتم اجرا
- مجموعه داده را بهطور تصادفی به K بخش مساوی تقسیم کنید
- برای i = 1 تا K:
- بخش i را بهعنوان مجموعه آزمون در نظر بگیرید
- K-1 بخش باقیمانده را بهعنوان مجموعه آموزش استفاده کنید
- مدل را آموزش دهید
- عملکرد را بر روی مجموعه آزمون ارزیابی کنید
- میانگین نتایج K تکرار را بهعنوان برآورد نهایی محاسبه کنید
انتخاب مقدار K
انتخاب مقدار K بسیار مهم است و بر نتایج تأثیرگذار خواهد بود:
K کوچک (مثلاً K=3):
- زمان اجرای کمتر
- واریانس بیشتر در برآورد
- بایاس (تورش) بیشتر
متوسط (K=5 یا K=10):
- توصیه میشود برای اکثر کاربردها
- تعادل خوب بین بایاس و واریانس
- K=10 استاندارد صنعت محسوب میشود
بزرگ (K=20 یا بیشتر):
- واریانس کمتر
- زمان اجرای بیشتر
- ممکن است منجر به بیشبرازش شود
مزایا و کاربردها
مزایا:
- استفاده بهینه از تمام دادهها
- هر نمونه دقیقاً یک بار برای آزمون و K-1 بار برای آموزش استفاده میشود
- برآورد پایدارتر نسبت به Hold-Out
- کاهش واریانس در مقایسه با روش نگهداشتن
- مناسب برای مجموعه دادههای متوسط
معایب:
- هزینه محاسباتی بالاتر (باید K مدل آموزش داد)
- زمانبر برای مجموعه دادههای بزرگ
- نتایج ممکن است به انتخاب تصادفی folds وابسته باشد
۳. اعتبارسنجی متقابل Stratified K-Fold
تعریف و ضرورت
Stratified K-Fold نسخه پیشرفتهتری از K-Fold است که برای مجموعه دادههای نامتوازن (Imbalanced) طراحی شده است. در این روش، هر fold بهگونهای ساخته میشود که نسبت کلاسها در آن با نسبت کلاسها در مجموعه داده اصلی برابر باشد.
چه زمانی استفاده کنیم؟
این روش زمانی ضروری است که:
- توزیع کلاسها نامتوازن است
- یک کلاس بهشدت کمیاب است
- میخواهیم از نمایندگی عادلانه تمام کلاسها در هر fold اطمینان حاصل کنیم
مثال کاربردی
فرض کنید در یک مسئله طبقهبندی پزشکی، ۹۰٪ بیماران سالم و ۱۰٪ بیمار هستند. با استفاده از Stratified K-Fold، هر fold دقیقاً همین نسبت ۹۰-۱۰ را حفظ میکند، در حالی که K-Fold معمولی ممکن است foldهایی بدون هیچ بیمار یا با نسبتهای متفاوت ایجاد کند.
مزایا
- جلوگیری از foldهای بدون نمونه از کلاسهای کمیاب
- ارزیابی عادلانهتر برای مجموعه دادههای نامتوازن
- معیارهای ارزیابی پایدارتر (مثل ROC AUC)
- کاهش واریانس در نتایج
۴. Leave-One-Out Cross-Validation (LOOCV)
تعریف
LOOCV حالت خاصی از K-Fold است که در آن K برابر با تعداد نمونهها (N) است. در هر تکرار، تنها یک نمونه برای آزمون نگهداشته میشود و بقیه نمونهها برای آموزش استفاده میشوند. این فرآیند N بار تکرار میشود.
الگوریتم
برای مجموعه داده با N نمونه:
- برای i = 1 تا N:
- نمونه i را بهعنوان مجموعه آزمون انتخاب کنید
- N-1 نمونه باقیمانده را برای آموزش استفاده کنید
- مدل را آموزش دهید و روی نمونه i ارزیابی کنید
- میانگین N نتیجه را محاسبه کنید
چه زمانی مناسب است؟
LOOCV زمانی مناسب است که:
- مجموعه داده بسیار کوچک است (N < 50)
- میخواهیم حداکثر استفاده را از دادهها داشته باشیم
- دقت بالا در برآورد مهم است
- هزینه محاسباتی مسئله نیست
مزایا و معایب
مزایا:
- تقریباً بدون بایاس (هر بار با N-1 نمونه آموزش میبینید)
- استفاده حداکثری از دادهها
- مناسب برای مجموعه دادههای خیلی کوچک
- برآورد دقیقتر نسبت به K-Fold
معایب:
- بسیار زمانبر (باید N مدل آموزش داد)
- هزینه محاسباتی بسیار بالا برای N بزرگ
- واریانس بالا در برآورد (چون مجموعههای آموزش بسیار شبیه هم هستند)
- ممکن است منجر به برآورد خوشبینانه شود
- برای مدلهای پیچیده عملی نیست
۵. Leave-P-Out Cross-Validation (LPO)
تعریف
LPO تعمیم LOOCV است که در هر تکرار P نمونه برای آزمون نگهداشته میشود. این روش تمام ترکیبات ممکن C(N,P) را آزمایش میکند، که میتواند عدد بسیار بزرگی باشد.
کاربرد و محدودیتها
به دلیل تعداد بسیار زیاد ترکیبات، این روش معمولاً برای P≤2 و مجموعه دادههای کوچک استفاده میشود. برای مثال، با N=100 و P=2، تعداد ترکیبات برابر 4950 خواهد بود.
مزایا:
- برآورد بسیار دقیق
- پوشش کامل تمام حالات ممکن
معایب:
- هزینه محاسباتی بسیار بالا
- عملی نیست برای P≥3
- زمانبر
۶. Repeated K-Fold Cross-Validation
تعریف و هدف
در این روش، فرآیند K-Fold چندین بار با ترتیبهای تصادفی متفاوت از دادهها تکرار میشود. به این ترتیب، قابلیت اطمینان نتایج افزایش مییابد و تأثیر تقسیمبندی خاص دادهها کاهش مییابد.
الگوریتم
- برای r = 1 تا R (تعداد تکرارها):
- دادهها را بهطور تصادفی مخلوط کنید
- K-Fold Cross-Validation را اجرا کنید
- نتایج K fold را ذخیره کنید
- میانگین کل R×K نتیجه را محاسبه کنید
پارامترهای توصیهشده
معمولاً از 5-Fold یا 10-Fold با 3 تا 10 تکرار استفاده میشود. بهعنوان مثال: 10-Fold CV با 5 تکرار = 50 مدل آموزش دادهشده.
مزایا و معایب
مزایا:
- کاهش واریانس بهطور قابلتوجه
- برآورد پایدارتر و قابلاعتمادتر
- کاهش تأثیر شانس در تقسیمبندی
- مناسب برای مقایسه مدلها
معایب:
- هزینه محاسباتی بسیار بالا (R×K برابر بیشتر)
- زمانبر
- ممکن است برای مجموعه دادههای بزرگ عملی نباشد
۷. Shuffle Split Cross-Validation
تعریف
در این روش، بهجای تقسیم منظم دادهها به folds، در هر تکرار یک زیرمجموعه تصادفی برای آموزش و یک زیرمجموعه دیگر برای آزمون انتخاب میشود. تعداد تکرارها و نسبت تقسیم قابل تنظیم هستند.
ویژگیهای کلیدی
- برخلاف K-Fold، تضمینی وجود ندارد که تمام folds متفاوت باشند
- اندازه مجموعه آموزش و آزمون ثابت میماند
- انعطافپذیری بالا در تعیین نسبت تقسیم
- تعداد تکرارها مستقل از اندازه داده است
کاربردها
مناسب زمانی است که:
- میخواهید کنترل دقیقتری بر اندازه مجموعههای آموزش و آزمون داشته باشید
- نیاز به تعداد مشخصی تکرار دارید (مستقل از اندازه داده)
- مجموعه داده بسیار بزرگ است
مزایا:
- انعطافپذیری بالا
- کنترل دقیق بر نسبت train/test
- سریعتر از K-Fold با تعداد تکرار کم
معایب:
- ممکن است برخی نمونهها اصلاً استفاده نشوند
- ممکن است برخی نمونهها چندین بار تکرار شوند
- استفاده ناکارآمدتر از داده نسبت به K-Fold
۸. Group K-Fold Cross-Validation
تعریف و کاربرد
این روش برای دادههایی طراحی شده که ساختار گروهی دارند. تضمین میکند که نمونههای یک گروه خاص همگی در یک fold قرار بگیرند و هرگز بین مجموعههای آموزش و آزمون تقسیم نشوند.
کاربردهای عملی
مثال ۱ – دادههای پزشکی: اگر چندین نمونه از هر بیمار داریم، تمام نمونههای یک بیمار باید در یک fold باشند تا از نشت اطلاعات (Data Leakage) جلوگیری شود.
۲ – سری زمانی چندگانه: در پیشبینی فروش محصولات مختلف، هر محصول یک گروه است و باید کاملاً در یک fold قرار گیرد.
<p>۳ – دادههای آزمایشگاهی: اگر نمونهها از دستگاههای مختلف جمعآوری شدهاند، نمونههای هر دستگاه باید در یک گروه باشند.
الگوریتم
- گروههای منحصربهفرد را شناسایی کنید
- گروهها را به K fold تقسیم کنید (نه نمونههای فردی)
- در هر تکرار، گروههای یک fold برای آزمون و بقیه برای آموزش استفاده میشوند
مزایا:
- جلوگیری از Data Leakage
- ارزیابی واقعیتر توانایی تعمیمپذیری
- مناسب برای دادههای سلسلهمراتبی
معایب:
- اگر اندازه گروهها نابرابر باشد، folds نامتوازن میشوند
- پیچیدگی بیشتر در پیادهسازی
- ممکن است برخی folds تعداد نمونه کمی داشته باشند
۹. Stratified Group K-Fold
ترکیب دو رویکرد
این روش ترکیبی از Stratified K-Fold و Group K-Fold است که سعی میکند هم توزیع کلاسها را حفظ کند و هم از تقسیم گروهها جلوگیری کند. این روش زمانی کاربرد دارد که هم دادههای گروهی داریم و هم کلاسها نامتوازن هستند.
سناریوی کاربردی
تصور کنید در یک مطالعه پزشکی، چندین آزمایش از هر بیمار داریم و تعداد بیماران مبتلا به بیماری نادر بسیار کم است. در این حالت باید:
- تمام آزمایشات هر بیمار در یک fold باشند (Group K-Fold)
- نسبت بیماران سالم به بیمار در هر fold حفظ شود (Stratified)
۱۰. Time Series Split (اعتبارسنجی سری زمانی)
تفاوت اساسی با روشهای دیگر
در دادههای سری زمانی، فرض استقلال دادهها نقض میشود و ترتیب زمانی مهم است. بنابراین، نمیتوانیم دادهها را بهطور تصادفی تقسیم کنیم. در Time Series Split، مجموعه آموزش همیشه شامل دادههای گذشته و مجموعه آزمون شامل دادههای آینده است.
الگوریتم Forward Chaining
Fold 1: Train: [1] Test: [2]
Fold 2: Train: [1, 2] Test: [3]
Fold 3: Train: [1, 2, 3] Test: [4]
Fold 4: Train: [1, 2, 3, 4] Test: [5]
در هر fold، مجموعه آموزش از ابتدا تا یک نقطه زمانی مشخص و مجموعه آزمون بلوک زمانی بعدی است.
پارامترهای مهم
Gap (فاصله): گاهی بین مجموعه آموزش و آزمون یک فاصله زمانی قرار میدهیم تا از نشت اطلاعات جلوگیری کنیم.
Max Train Size: برای جلوگیری از بزرگ شدن بیش از حد مجموعه آموزش، میتوان حداکثر اندازه را محدود کرد.
Test Size: اندازه ثابت برای مجموعه آزمون در هر fold.
کاربردها
- پیشبینی قیمت سهام
- پیشبینی تقاضا و فروش
- پیشبینی آبوهوا
- هر مسئلهای با وابستگی زمانی
نکته مهم: استفاده از K-Fold معمولی برای سریهای زمانی اشتباه است و منجر به نشت اطلاعات میشود، چون مدل میتواند از اطلاعات آینده برای پیشبینی گذشته استفاده کند.
۱۱. Nested Cross-Validation (اعتبارسنجی متقابل تو در تو)
مفهوم و ضرورت
Nested CV زمانی استفاده میشود که علاوه بر ارزیابی مدل، نیاز به تنظیم هایپرپارامترها نیز داریم. این روش از دو حلقه تشکیل شده است:
حلقه داخلی (Inner Loop): برای تنظیم هایپرپارامترها و انتخاب بهترین مدل استفاده میشود.
حلقه خارجی (Outer Loop): برای ارزیابی بیطرفانه عملکرد مدل نهایی بهکار میرود.
چرا Nested CV ضروری است؟
اگر از یک CV ساده برای هم تنظیم هایپرپارامتر و هم ارزیابی مدل استفاده کنیم، برآورد عملکرد خوشبینانه (Optimistic) خواهد بود، چون هایپرپارامترها برای عملکرد بهتر روی همان دادههای اعتبارسنجی تنظیم شدهاند. این منجر به نشت اطلاعات و بیشبرازش میشود.
ساختار الگوریتم
برای هر fold در حلقه خارجی:
داده را به Train_outer و Test_outer تقسیم کن
برای هر fold در حلقه داخلی:
Train_outer را به Train_inner و Validation_inner تقسیم کن
برای هر ترکیب هایپرپارامتر:
مدل را با Train_inner آموزش بده
روی Validation_inner ارزیابی کن
بهترین هایپرپارامترها را انتخاب کن
مدل نهایی را با Train_outer و بهترین هایپرپارامترها آموزش بده
روی Test_outer ارزیابی کن
میانگین نتایج حلقه خارجی = برآورد بیطرفانه عملکرد
مثال عملی
فرض کنید میخواهیم یک SVM با بهترین مقدار C آموزش دهیم:
- حلقه خارجی: 5-Fold برای ارزیابی نهایی
- حلقه داخلی: 3-Fold برای انتخاب بهترین C
- تعداد کل مدلهای آموزشدیده: 5 × 3 × تعداد مقادیر C
مزایا و معایب
مزایا:
- برآورد بیطرفانه از عملکرد واقعی
- جلوگیری از بیشبرازش در انتخاب مدل
- مناسب برای گزارش نتایج در مقالات علمی
معایب:
- هزینه محاسباتی بسیار بالا
- پیچیدگی در پیادهسازی
- زمانبر برای مجموعه دادههای بزرگ
بیشبرازش، کمبرازش و نقش Cross-Validation
مفهوم بیشبرازش (Overfitting)
بیشبرازش زمانی رخ میدهد که مدل بهقدری پیچیده است که نهتنها الگوهای واقعی، بلکه نویز و جزئیات تصادفی دادههای آموزشی را نیز یاد میگیرد. چنین مدلی در دادههای آموزشی عملکرد عالی دارد اما در دادههای جدید ضعیف عمل میکند.
نشانههای بیشبرازش:
- خطای آموزش بسیار پایین اما خطای آزمون بالا
- تفاوت زیاد بین عملکرد train و test
- مدل بسیار پیچیده با پارامترهای زیاد
- واریانس بالای نتایج در foldهای مختلف CV
مفهوم کمبرازش (Underfitting)
کمبرازش زمانی رخ میدهد که مدل بیش از حد ساده است و نمیتواند الگوهای موجود در دادهها را یاد بگیرد. چنین مدلی در هر دو مجموعه آموزش و آزمون عملکرد ضعیفی دارد.
نشانههای کمبرازش:
- خطای بالا در هم دادههای آموزش و هم آزمون
- مدل بسیار ساده
- بایاس بالا
- عدم توانایی در یادگیری الگوهای پیچیده
چگونه Cross-Validation کمک میکند؟
تشخیص بیشبرازش: اگر در K-Fold CV، میانگین دقت train بسیار بالاتر از میانگین دقت validation باشد، احتمالاً بیشبرازش رخ داده است.
تشخیص کمبرازش: اگر هم دقت train و هم validation پایین باشند، مدل دچار کمبرازش است.
جلوگیری از بیشبرازش:
- استفاده از Regularization (L1, L2)
- کاهش پیچیدگی مدل
- افزایش دادههای آموزشی
- Early Stopping
- Dropout در شبکههای عصبی
جلوگیری از کمبرازش:
- افزایش پیچیدگی مدل
- افزودن ویژگیهای بیشتر
- کاهش Regularization
- آموزش طولانیتر
Trade-off بین بایاس و واریانس
مفهوم بایاس (Bias)
بایاس خطایی است که از فرضیات سادهسازیشده مدل نشأت میگیرد. مدلهای با بایاس بالا تمایل دارند روابط را بیش از حد ساده فرض کنند و الگوهای پیچیده را از دست بدهند.
مدلهای با بایاس بالا:
- رگرسیون خطی برای دادههای غیرخطی
- درخت تصمیم با عمق بسیار کم
- الگوریتمهای ساده
مفهوم واریانس (Variance)
واریانس نشاندهنده حساسیت مدل به تغییرات کوچک در دادههای آموزشی است. مدلهای با واریانس بالا بهشدت به دادههای خاص آموزشی وابسته هستند.
مدلهای با واریانس بالا:
- درختهای تصمیم عمیق
- چندجملهایهای درجه بالا
- مدلهای بسیار پیچیده
تعادل بایاس-واریانس
خطای کل = بایاس² + واریانس + نویز
هدف یافتن نقطه بهینهای است که هم بایاس و هم واریانس در حد قابلقبولی باشند:
- مدلهای ساده: بایاس بالا، واریانس پایین
- مدلهای پیچیده: بایاس پایین، واریانس بالا
- مدل بهینه: تعادل مناسب
Cross-Validation به ما کمک میکند این نقطه بهینه را پیدا کنیم.
پیادهسازی عملی با Python و Scikit-learn
مثال ۱: K-Fold Cross-Validation پایه
from sklearn.model_selection import KFold, cross_val_score
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
import numpy as np
# بارگذاری داده
X, y = load_iris(return_X_y=True)
# تعریف مدل
model = LogisticRegression(max_iter=200)
# تعریف K-Fold
kfold = KFold(n_splits=5, shuffle=True, random_state=42)
# اجرای Cross-Validation
scores = cross_val_score(model, X, y, cv=kfold, scoring='accuracy')
# نمایش نتایج
print(f"نتایج هر fold: {scores}")
print(f"میانگین دقت: {scores.mean():.4f}")
print(f"انحراف معیار: {scores.std():.4f}")
۲: Stratified K-Fold برای دادههای نامتوازن
from sklearn.model_selection import StratifiedKFold
from sklearn.ensemble import RandomForestClassifier
# تعریف Stratified K-Fold
skfold = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
# تعریف مدل
model = RandomForestClassifier(n_estimators=100, random_state=42)
# اجرا
scores = cross_val_score(model, X, y, cv=skfold, scoring='f1_weighted')
print(f"F1-Score میانگین: {scores.mean():.4f}")
۳: Leave-One-Out Cross-Validation
from sklearn.model_selection import LeaveOneOut
from sklearn.svm import SVC
# برای داده کوچک
X_small, y_small = X[:30], y[:30]
# تعریف LOOCV
loo = LeaveOneOut()
model = SVC(kernel='linear')
scores = cross_val_score(model, X_small, y_small, cv=loo)
print(f"تعداد تکرارها: {len(scores)}")
print(f"دقت میانگین: {scores.mean():.4f}")
۴: Time Series Split
from sklearn.model_selection import TimeSeriesSplit
import pandas as pd
# فرض: داده سری زمانی
n_samples = 100
X_ts = np.random.randn(n_samples, 5)
y_ts = np.random.randn(n_samples)
# تعریف Time Series Split
tscv = TimeSeriesSplit(n_splits=5, test_size=10, gap=2)
for fold, (train_idx, test_idx) in enumerate(tscv.split(X_ts)):
print(f"Fold {fold+1}:")
print(f" Train: indices {train_idx[0]} to {train_idx[-1]} (size={len(train_idx)})")
print(f" Test: indices {test_idx[0]} to {test_idx[-1]} (size={len(test_idx)})")
۵: Group K-Fold
from sklearn.model_selection import GroupKFold
# فرض: دادههای گروهی (مثلاً از 3 بیمار)
groups = np.array([1,1,1,1, 2,2,2,2, 3,3,3,3])
X_group = np.random.randn(12, 4)
y_group = np.random.randint(0, 2, 12)
gkfold = GroupKFold(n_splits=3)
for fold, (train_idx, test_idx) in enumerate(gkfold.split(X_group, y_group, groups)):
print(f"Fold {fold+1}:")
print(f" Train groups: {np.unique(groups[train_idx])}")
print(f" Test groups: {np.unique(groups[test_idx])}")
۶: Nested Cross-Validation با Grid Search
from sklearn.model_selection import GridSearchCV
from sklearn.datasets import load_breast_cancer
# بارگذاری داده
X, y = load_breast_cancer(return_X_y=True)
# تعریف فضای جستجوی هایپرپارامترها
param_grid = {
'C': [0.1, 1, 10],
'kernel': ['rbf', 'linear'],
'gamma': ['scale', 'auto']
}
# حلقه داخلی: Grid Search
inner_cv = KFold(n_splits=3, shuffle=True, random_state=42)
model = SVC()
grid_search = GridSearchCV(model, param_grid, cv=inner_cv, scoring='accuracy')
# حلقه خارجی: ارزیابی نهایی
outer_cv = KFold(n_splits=5, shuffle=True, random_state=42)
nested_scores = cross_val_score(grid_search, X, y, cv=outer_cv)
print(f"میانگین دقت Nested CV: {nested_scores.mean():.4f}")
print(f"انحراف معیار: {nested_scores.std():.4f}")
۷: Repeated K-Fold
from sklearn.model_selection import RepeatedKFold
# 5-Fold با 3 تکرار = 15 مدل
rkfold = RepeatedKFold(n_splits=5, n_repeats=3, random_state=42)
model = LogisticRegression(max_iter=200)
scores = cross_val_score(model, X, y, cv=rkfold, scoring='accuracy')
print(f"تعداد کل ارزیابیها: {len(scores)}")
print(f"میانگین دقت: {scores.mean():.4f}")
print(f"انحراف معیار: {scores.std():.4f}")
راهنمای انتخاب روش مناسب
بر اساس اندازه داده
داده بسیار کوچک (N < 50):</p>
- LOOCV یا Leave-P-Out
- K-Fold با K بزرگ (10 یا بیشتر)
<p> متوسط (50 < N < 1000):</p>
- 5-Fold یا 10-Fold Cross-Validation
- Stratified K-Fold برای کلاسهای نامتوازن</li>
داده بزرگ (N > 1000):</p>
- 3-Fold یا 5-Fold (برای کاهش هزینه محاسباتی)
- Hold-Out با نسبت 80-20 یا 70-30
- Shuffle Split
داده بسیار بزرگ (N > 100,000):</p>
- Hold-Out ساده
- Shuffle Split با تعداد تکرار کم
بر اساس نوع مسئله
طبقهبندی با کلاسهای متوازن:
- K-Fold استاندارد
طبقهبندی با کلاسهای نامتوازن:
- Stratified K-Fold
- Stratified Shuffle Split
سری زمانی:
- Time Series Split
- هرگز K-Fold معمولی استفاده نکنید
دادههای گروهی:
- Group K-Fold
- Leave-One-Group-Out
دادههای گروهی + کلاسهای نامتوازن:
- Stratified Group K-Fold
بر اساس هدف
مقایسه سریع مدلهای مختلف:
- 3-Fold یا 5-Fold
ارزیابی دقیق یک مدل:
- 10-Fold
- Repeated K-Fold
تنظیم هایپرپارامترها:
- Grid Search با K-Fold داخلی
تنظیم هایپرپارامتر + ارزیابی:
- Nested Cross-Validation
محاسبات سنگین/مدل پیچیده:
- 3-Fold
- Hold-Out
نکات و توصیههای عملی
۱. تنظیم random_state
همیشه random_state را تنظیم کنید تا نتایج قابل تکرار باشند:
kfold = KFold(n_splits=5, shuffle=True, random_state=42)
۲. Shuffle کردن دادهها
مگر برای سریهای زمانی، همیشه shuffle=True استفاده کنید تا از تورش ناشی از ترتیب دادهها جلوگیری شود.
۳. Scaling و Preprocessing
اشتباه رایج:
# اشتباه: scaling قبل از split
X_scaled = scaler.fit_transform(X)
scores = cross_val_score(model, X_scaled, y, cv=5)
روش صحیح:
# صحیح: استفاده از Pipeline
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
pipeline = Pipeline([
('scaler', StandardScaler()),
('model', LogisticRegression())
])
scores = cross_val_score(pipeline, X, y, cv=5)
در روش صحیح، scaling در داخل هر fold انجام میشود و از نشت اطلاعات جلوگیری میکند.
۴. انتخاب معیار ارزیابی (Scoring)
معیار مناسب را برای مسئله خود انتخاب کنید:
طبقهبندی:
- accuracy: برای کلاسهای متوازن
- f1, f1_weighted: برای کلاسهای نامتوازن
- roc_auc: برای ارزیابی احتمالات
- precision, recall: بسته به اولویت
رگرسیون:
- neg_mean_squared_error: MSE
- neg_mean_absolute_error: MAE
- r2: ضریب تعیین
scores = cross_val_score(model, X, y, cv=5, scoring='f1_weighted')
۵. ذخیره مدلهای هر Fold
گاهی نیاز است مدلهای آموزشدیده در هر fold را نگه داریم:
from sklearn.model_selection import cross_validate
results = cross_validate(
model, X, y, cv=5,
scoring='accuracy',
return_train_score=True,
return_estimator=True
)
# دسترسی به مدلها
trained_models = results['estimator']
train_scores = results['train_score']
test_scores = results['test_score']
۶. تحلیل واریانس نتایج
واریانس بالا در نتایج foldها نشانه ناپایداری مدل است:
scores = cross_val_score(model, X, y, cv=10)
print(f"میانگین: {scores.mean():.4f}")
print(f"انحراف معیار: {scores.std():.4f}")
print(f"Min: {scores.min():.4f}, Max: {scores.max():.4f}")
# اگر std بالا باشد، ممکن است:
# - مدل ناپایدار باشد
# - داده کافی نباشد
# - نیاز به Regularization باشد
۷. Cross-Validation برای Feature Selection
from sklearn.feature_selection import RFECV
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=100)
rfecv = RFECV(estimator=model, step=1, cv=5, scoring='accuracy')
rfecv.fit(X, y)
print(f"تعداد بهینه ویژگیها: {rfecv.n_features_}")
print(f"ویژگیهای انتخابشده: {rfecv.support_}")
۸. Parallel Processing
برای تسریع محاسبات، از پردازش موازی استفاده کنید:
scores = cross_val_score(
model, X, y, cv=10,
n_jobs=-1 # استفاده از تمام هستههای CPU
)
مشکلات رایج و راهحلها
مشکل ۱: Data Leakage (نشت اطلاعات)
علت: انجام preprocessing قبل از split دادهها.
راهحل: استفاده از Pipeline یا انجام preprocessing در داخل هر fold.
مشکل ۲: Temporal Leakage در سریهای زمانی
علت: استفاده از K-Fold معمولی برای دادههای زمانی.
راهحل: استفاده از TimeSeriesSplit.
مشکل ۳: Group Leakage
علت: تقسیم نمونههای یک گروه بین train و test.
راهحل: استفاده از GroupKFold.
مشکل ۴: واریانس بالای نتایج
علائم: تفاوت زیاد در دقت بین foldها.
راهحلها:
- افزایش تعداد دادهها
- استفاده از Repeated K-Fold
- Regularization
- مدل سادهتر
مشکل ۵: Computational Cost بالا
راهحلها:
- کاهش K (مثلاً از 10 به 5)
- استفاده از Shuffle Split با تکرار کمتر
- Parallel processing با n_jobs=-1
- استفاده از مدل سادهتر
مشکل ۶: Imbalanced Folds
علت: عدم استفاده از Stratified در دادههای نامتوازن.
راهحل: استفاده از StratifiedKFold.
مطالعات موردی و مثالهای کاربردی
مورد ۱: پیشبینی بیماری قلبی
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
# بارگذاری داده (مثال با breast cancer)
X, y = load_breast_cancer(return_X_y=True)
# ساخت Pipeline
pipeline = Pipeline([
('scaler', StandardScaler()),
('model', GradientBoostingClassifier(n_estimators=100))
])
# Stratified برای کلاسهای نامتوازن
skfold = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
# ارزیابی با معیارهای مختلف
from sklearn.model_selection import cross_validate
scoring = ['accuracy', 'precision', 'recall', 'f1', 'roc_auc']
results = cross_validate(
pipeline, X, y,
cv=skfold,
scoring=scoring,
return_train_score=False
)
for metric in scoring:
scores = results[f'test_{metric}']
print(f"{metric}: {scores.mean():.4f} (+/- {scores.std():.4f})")
۲: پیشبینی قیمت سهام (سری زمانی)
import pandas as pd
from sklearn.linear_model import Ridge
# فرض: داده قیمت سهام
dates = pd.date_range('2020-01-01', periods=500, freq='D')
prices = np.cumsum(np.random.randn(500)) + 100
# ساخت ویژگیهای تأخیری
def create_features(data, lags=5):
df = pd.DataFrame({'price': data})
for i in range(1, lags+1):
df[f'lag_{i}'] = df['price'].shift(i)
df['target'] = df['price'].shift(-1)
return df.dropna()
df = create_features(prices)
X = df.drop('target', axis=1).values
y = df['target'].values
# Time Series Split با Gap
tscv = TimeSeriesSplit(n_splits=5, test_size=30, gap=5)
model = Ridge(alpha=1.0)
scores = []
for train_idx, test_idx in tscv.split(X):
X_train, X_test = X[train_idx], X[test_idx]
y_train, y_test = y[train_idx], y[test_idx]
model.fit(X_train, y_train)
score = model.score(X_test, y_test)
scores.append(score)
print(f"R² Score: {score:.4f}")
print(f"\nمیانگین R²: {np.mean(scores):.4f}")
۳: تشخیص تصویر با Nested CV
from sklearn.svm import SVC
from sklearn.decomposition import PCA
# فرض: داده تصویر
from sklearn.datasets import load_digits
X, y = load_digits(return_X_y=True)
# Pipeline با PCA
pipeline = Pipeline([
('pca', PCA()),
('svm', SVC())
])
# فضای جستجو
param_grid = {
'pca__n_components': [20, 30, 40, 50],
'svm__C': [0.1, 1, 10],
'svm__kernel': ['rbf', 'linear']
}
# Inner CV برای Grid Search
inner_cv = StratifiedKFold(n_splits=3, shuffle=True, random_state=42)
grid_search = GridSearchCV(
pipeline, param_grid,
cv=inner_cv,
scoring='accuracy',
n_jobs=-1
)
# Outer CV برای ارزیابی نهایی
outer_cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
nested_scores = cross_val_score(grid_search, X, y, cv=outer_cv, n_jobs=-1)
print(f"دقت نهایی: {nested_scores.mean():.4f} (+/- {nested_scores.std():.4f})")
# آموزش مدل نهایی با بهترین پارامترها
grid_search.fit(X, y)
print(f"بهترین پارامترها: {grid_search.best_params_}")
نتیجهگیری
اعتبارسنجی متقابل ابزاری ضروری در یادگیری ماشین است که:
- ارزیابی واقعبینانه از عملکرد مدل ارائه میدهد
- از بیشبرازش و کمبرازش جلوگیری میکند
- استفاده بهینه از دادهها را تضمین میکند
- قابلیت تعمیمپذیری مدل را میسنجد
- به انتخاب بهترین مدل کمک میکند