یادگیری فدراتیو (Federated Learning) به عنوان یک پارادایم نوآورانه در یادگیری ماشین توزیعشده، امکان آموزش مدلهای هوش مصنوعی را بدون به اشتراکگذاری دادههای خام فراهم میآورد. این رویکرد با حفظ دادهها به صورت غیرمتمرکز در منابع محلی، خطرات مربوط به حریم خصوصی را کاهش میدهد که بهویژه در سناریوهایی که حساسیت دادهها یا الزامات نظارتی، متمرکزسازی دادهها را غیرعملی میسازد، بسیار سودمند است. این مقاله به بررسی جامع وضعیت کنونی، چالشها، فناوریهای تکمیلی و چشمانداز آینده یادگیری فدراتیو در حوزه محافظت از حریم خصوصی میپردازد. با تحلیل آخرین پیشرفتها در ترکیب یادگیری فدراتیو با رمزنگاری همومورفیک، حریم خصوصی تفاضلی و بلاکچین، راهکارهای عملی برای مواجهه با چالشهای امنیتی و حفظ حریم خصوصی ارائه میدهیم.
1. مقدمه
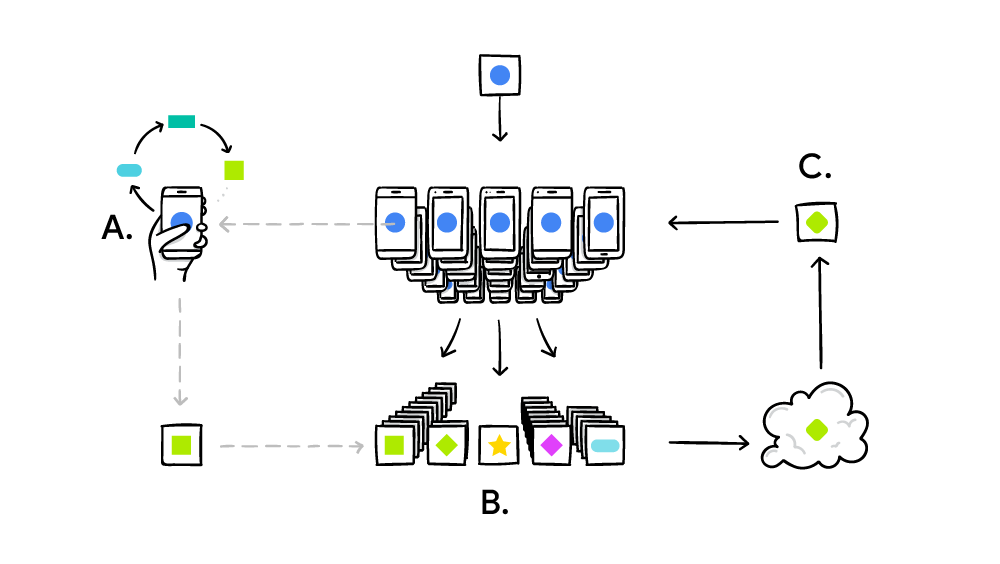
در عصر دیجیتال کنونی، حجم عظیمی از دادهها توسط دستگاههای مختلف از جمله گوشیهای هوشمند، دستگاههای اینترنت اشیاء (IoT) و سیستمهای بهداشتی تولید میشود. یادگیری فدراتیو با ارائه یک چارچوب یادگیری ماشین توزیعشده که در آن مدلها به صورت مشارکتی آموزش داده میشوند بدون اینکه دادههای خام منتقل شوند، به یکی از راهحلهای کلیدی برای حفظ حریم خصوصی تبدیل شده است.
شرکت گوگل در سال ۲۰۱۶ برای اولین بار مفهوم یادگیری فدراتیو را معرفی کرد که امکان آموزش مدلهای یادگیری ماشین را در دستگاههای متعدد بدون به اشتراکگذاری دادههای محلی فراهم میآورد. از آن زمان تاکنون، این فناوری به سرعت در حوزههای مختلف از جمله بهداشت و درمان، شهرهای هوشمند، و صنایع مالی گسترش یافته است.
1.1 اهمیت حریم خصوصی در یادگیری ماشین
مزیت اصلی یادگیری فدراتیو در ظرفیت آن برای انجام آموزش مشارکتی دادهها در حالی که از به اشتراکگذاری دادههای خام خودداری میکند، نمایان میشود که این امر برای محافظت از حریم خصوصی کاربران و رعایت مقررات حفاظت از دادهها بسیار حیاتی است. با توجه به مقررات سختگیرانهای مانند GDPR در اتحادیه اروپا و قوانین مشابه در سایر کشورها، نیاز به روشهایی که بتوانند همزمان از قدرت دادهها استفاده کرده و حریم خصوصی را حفظ کنند، بیش از پیش احساس میشود.
1.2 هدف و ساختار مقاله
این مقاله با هدف ارائه تحلیلی جامع از وضعیت فعلی و آینده یادگیری فدراتیو در حوزه محافظت از حریم خصوصی تدوین شده است. در ادامه، ابتدا مفاهیم بنیادی یادگیری فدراتیو را بررسی میکنیم، سپس به چالشهای کلیدی آن میپردازیم، و در نهایت راهحلهای نوآورانه و چشمانداز آینده این فناوری را تحلیل خواهیم کرد.
2. مفاهیم بنیادی یادگیری فدراتیو
2.1 تعریف و اصول کلیدی
یادگیری فدراتیو یک فرآیند یادگیری ماشین توزیعشده است که به چندین گره (node) امکان میدهد تا بدون به اشتراکگذاری دادههای خام، مدل مشترکی را آموزش دهند. در این رویکرد، به جای انتقال دادهها به سرور مرکزی، مدل به سمت دادهها حرکت میکند.
2.2 معماری سیستم یادگیری فدراتیو
معماری کلی یادگیری فدراتیو شامل اجزای زیر است:
1. کلاینتها (Clients): دستگاهها یا سازمانهایی که دادههای محلی را در اختیار دارند و آموزش محلی را انجام میدهند.
2. سرور مرکزی (Central Server): مسئول هماهنگی فرآیند آموزش، تجمیع مدلها و توزیع مدل سراسری بهروزشده است.
3. پروتکل ارتباطی: مکانیزمی برای تبادل امن پارامترهای مدل بین کلاینتها و سرور.
2.3 انواع یادگیری فدراتیو
یادگیری فدراتیو را میتوان به سه دسته اصلی تقسیم کرد: یادگیری فدراتیو افقی (Horizontal FL)، یادگیری فدراتیو عمودی (Vertical FL) و یادگیری انتقالی فدراتیو (Federated Transfer Learning):
- یادگیری فدراتیو افقی: زمانی که کلاینتها دارای ویژگیهای یکسان اما نمونههای مختلف هستند
- یادگیری فدراتیو عمودی: زمانی که کلاینتها دارای ویژگیهای مختلف برای همان نمونهها هستند
- یادگیری انتقالی فدراتیو: زمانی که کلاینتها دارای دادههای مختلف در هر دو بعد ویژگی و نمونه هستند
3. چالشهای کلیدی در یادگیری فدراتیو
3.1 ناهمگونی دادهها (Data Heterogeneity)
در یادگیری فدراتیو، دادهها در میان کلاینتها ممکن است غیر مستقل و غیر یکسان توزیعشده (Non-IID) باشند، نامتعادل بوده و از نظر کمیت و کیفیت بسیار متغیر باشند. چنین تنوعی میتواند منجر به مدلهایی شود که برای برخی کلاینتها عملکرد خوبی دارند اما برای دیگران ضعیف عمل میکنند.
ناهمگونی دادهها یکی از چالشهای اساسی در یادگیری فدراتیو است که میتواند به شکلهای مختلفی ظاهر شود:
- ناهمگونی در توزیع برچسبها: کلاینتهای مختلف ممکن است دادههایی با توزیعهای برچسب متفاوت داشته باشند
- ناهمگونی در حجم داده: تفاوت قابل توجه در تعداد نمونههای موجود در هر کلاینت
- ناهمگونی در کیفیت داده: تفاوت در دقت، کامل بودن یا قابلیت اطمینان دادهها
3.2 چالشهای امنیتی و حریم خصوصی
با وجود اینکه یادگیری فدراتیو یک نوع چارچوب یادگیری توزیعشده خاص است که به چندین کاربر اجازه میدهد در آموزش مدل مشارکت کنند در حالی که حریم خصوصی آنها به خطر نمیافتد، این پارادایم همچنان در برابر تهدیدات امنیتی و حریم خصوصی مختلف از سوی مهاجمان آسیبپذیر است.
تهدیدات اصلی شامل:
1. حملات استنتاج عضویت (Membership Inference Attacks): مهاجم تلاش میکند تا تشخیص دهد آیا یک نمونه خاص در دادههای آموزشی وجود داشته است یا خیر
2. حملات بازسازی داده (Data Reconstruction Attacks): بازسازی دادههای اصلی از روی بهروزرسانیهای مدل
3. حملات مسمومیت مدل (Model Poisoning Attacks): تزریق دادهها یا بهروزرسانیهای مخرب برای کاهش عملکرد مدل
4. حملات دروازه پشتی (Backdoor Attacks): کاشت رفتارهای مخرب در مدل که در شرایط خاص فعال میشوند
3.3 هزینههای ارتباطی و محاسباتی
ارسال حجم زیادی از دادهها از گرههای محاسبات لبه (Edge) یا دستگاههای لبه به سرور از راه دور نیاز به کدگذاری و زمان انتقال بیشتری در شبکه دارد. این مسئله بهویژه در محیطهایی با پهنای باند محدود یا دستگاههای با منابع محدود اهمیت بیشتری پیدا میکند.
3.4 مقیاسپذیری و کارایی
با افزایش تعداد کلاینتها، هماهنگی فرآیند آموزش و تجمیع مدلها پیچیدهتر میشود. یکی از چالشهای اصلی در چنین محیطهایی، انتخاب کارآمد گرههای لبه و بهینهسازی تخصیص منابع است، بهویژه در تنظیمات پویا و محدود از نظر منابع.
4. فناوریهای تکمیلی برای تقویت حریم خصوصی
4.1 رمزنگاری همومورفیک (Homomorphic Encryption)
رمزنگاری همومورفیک به انجام محاسبات بر روی دادههای رمزشده اجازه میدهد و سپس فقط نتیجه را رمزگشایی میکند. این امر به یادگیری فدراتیو امکان میدهد تا به تجمیع گرادیانها دسترسی داشته باشد بدون اینکه به خود گرادیانها دسترسی داشته باشد.
مزایای رمزنگاری همومورفیک در یادگیری فدراتیو:
سرور تجمیعکننده به هیچیک از بهروزرسانیهای مدل دسترسی نمییابد که از حملات احتمالی استنتاج جلوگیری میکند. این امکان را به طرفها میدهد تا به یک تجمیعکننده شخص ثالث برای هماهنگی فرآیند یادگیری اعتماد کنند بدون اینکه مدل تولیدشده یا دادههای خام خود را فاش کنند.
چالشهای پیادهسازی:
پیکربندی پارامترهای امنیتی CKKS شامل یک مبادله بین صحت، کارایی و امنیت است. علاوه بر این، حداکثر طول بردار که CKKS میتواند یکباره رمزگذاری کند، بر اساس توصیه استاندارد رمزنگاری همومورفیک، ۱۶۳۸۴ است که کاربرد گسترده آن را در یادگیری فدراتیو هنگام رمزگذاری لایههایی با نورونهای متعدد محدود میکند.
4.2 حریم خصوصی تفاضلی (Differential Privacy)
حریم خصوصی تفاضلی روشی برای مختل کردن دادهها است در حالی که ویژگیهای آماری دادهها حفظ میشود. این امر به ما امکان میدهد تا تحلیلها و آمارهای معنیداری داشته باشیم در حالی که از برخی حملات قبلی جلوگیری میکنیم.
حریم خصوصی تفاضلی با افزودن نویز کنترلشده به دادهها یا بهروزرسانیهای مدل، تضمین میکند که خروجی یک الگوریتم تقریباً یکسان باقی بماند چه یک فرد خاص در مجموعه داده حضور داشته باشد یا خیر.
4.3 بلاکچین و یادگیری فدراتیو
بلاکچین میتواند با استفاده از معماری غیرمتمرکز و غیرقابل تغییر خود، به بهبود امنیت، قابلیت اطمینان و عملکرد یادگیری فدراتیو کمک کند.
مزایای ترکیب بلاکچین با یادگیری فدراتیو:
بلاکچین راهحلی قوی برای رفع چالشهای امنیتی ذاتی در یادگیری فدراتیو ارائه میدهد. ساختار غیرمتمرکز و غیرقابل تغییر آن با توزیع ذخیرهسازی و عملیات مدل در گرهها، انعطافپذیری را تضمین میکند و از خرابی سیستم در اثر از کار افتادن گرهها جلوگیری میکند.
5. کاربردهای عملی و موفق
5.1 بهداشت و درمان
یادگیری فدراتیو در حوزه پزشکی برای پیشبینی نرخ بستری به دلیل رویدادهای قلبی، تومورها، سرطان و دیابت؛ نرخ مرگومیر؛ و مدت اقامت در ICU کمک میکند. علاوه بر این، مزایا و دامنه کاربرد یادگیری فدراتیو به تصویربرداری پزشکی، بخشبندی کل مغز مبتنی بر MRI و بخشبندی تومور مغزی گسترش مییابد.
Federated Learning با رمزنگاری همومورفیک، چندین طرف را قادر میسازد تا به طور امن مدلهای هوش مصنوعی را در پاتولوژی و رادیولوژی آموزش دهند و به عملکرد پیشرفته با تضمینهای حریم خصوصی دست یابند.
مثال عملی: پیشبینی شدت COVID-19
در اوج همهگیری COVID-19، دو بیمارستان فرانسوی با استفاده از Federated Learning برای پیشبینی شدت بیماری در بیماران بستری همکاری کردند. در عرض تنها ۲ ماه، مدلی ساخته شد که میتوانست دادههای چندوجهی (تصاویر CT ریه، گزارشهای رادیولوژی و انواع دادههای بالینی و بیولوژیکی) را تحلیل کند.
5.2 اینترنت اشیاء و شهرهای هوشمند
ظهور شبکههای 5G و رشد روزافزون دستگاههای اینترنت اشیاء، نیاز به مدلهای یادگیری ماشین کارآمد، امن و حافظ حریم خصوصی را که میتوانند در محیطهای لبه غیرمتمرکز کار کنند، تشدید کرده است.
چارچوب Edge-FLGuard با ترکیب مدلهای یادگیری عمیق سبکوزن – بهویژه رمزگذارهای خودکار و شبکههای LSTM – برای استنتاج در دستگاه، همراه با خط لوله آموزش فدراتیو حافظ حریم خصوصی، تشخیص تهدید مقیاسپذیر و غیرمتمرکز را بدون به اشتراکگذاری دادههای خام امکانپذیر میسازد.
5.3 صنایع و کسبوکار
شرکتهای بزرگ فناوری مانند گوگل، اپل و متا از یادگیری فدراتیو در برنامههایی مانند Gboard، Siri و دستیاران هوش مصنوعی متا برای ارائه تجربیات کاربری حافظ حریم خصوصی استفاده میکنند.
6. راهکارها و رویکردهای نوین
6.1 حل مسئله ناهمگونی دادهها
سیستمهایFederated Learning باید از استراتژیهای سفارشیشده مانند رویکردهای تجمیع پویا، تکنیکهای مدلسازی فردی و روشهای بهینهسازی فدراتیو مقاوم استفاده کنند. این راهحلهای تخصصی، یادگیری مؤثر از توزیعهای داده متنوع را در حالی که حریم خصوصی دادهها حفظ میشود و کارایی محاسباتی حفظ میشود، تسهیل میکنند.
روشهای پیشنهادی:
- FedProx: تعمیمی از الگوریتم FedAvg که برای مقابله با ناهمگونی در شبکههای فدراتیو طراحی شده است
- مدلهای شخصیسازی شده: ایجاد مدلهای سفارشی برای هر کلاینت در حالی که از دانش مشترک سراسری بهره میبرند
- یادگیری چندوظیفهای (Multi-Task Learning): رویکردی که هر کلاینت را به عنوان یک وظیفه جداگانه در نظر میگیرد
6.2 بهینهسازی ارتباطات
برای غلبه بر چالشهای ارتباطی، راهکارهای زیر پیشنهاد میشود: روش ماسکگذاری دوگانه-سپس-رمزگذاری برای کاربران نهایی جهت ارسال بهروزرسانیهای محلی خود به منظور حفاظت از حریم خصوصی دادهها.
روشهای بهینهسازی ارتباطات شامل:
- فشردهسازی مدل: استفاده از تکنیکهای کوانتیزاسیون و هرس کردن برای کاهش حجم دادههای ارسالی
- بهروزرسانیهای ناهمزمان: اجازه به کلاینتها برای ارسال بهروزرسانیها در زمانهای مختلف
- نمونهبرداری کلاینت: انتخاب زیرمجموعهای از کلاینتها در هر دور آموزش
6.3 امنیت پیشرفته با ترکیب فناوریها
این مقاله یک طرح Federated Learning حافظ حریم خصوصی جدید ارائه میدهد که رمزنگاری همومورفیک را با تکنیک تولید ماسک کارآمد ادغام میکند.
چارچوب EPP-BCFL با ادغام بلاکچین با مکانیزمهای حریم خصوصی ترکیبی و استراتژیهای تجمیع هوشمند، دقت مدل ۹۵.۲٪، کاهش ۴۳٪ در سربار ارتباطی، کاهش ۳۷٪ در هزینه محاسباتی را به دست میآورد و در برابر بردارهای حمله متعدد با سطوح دقت بالای ۹۳٪ مقاومت نشان میدهد.
7. چشمانداز آینده و جهتگیریهای پژوهشی
7.1 ادغام با فناوریهای نوظهور
7.1.1 یادگیری فدراتیو و شبکههای 6G
با ظهور شبکههای 6G، انتظار میرود یادگیری فدراتیو نقش محوریتری در معماری شبکه ایفا کند. پهنای باند بیشتر، تأخیر کمتر و قابلیتهای پردازش لبه پیشرفتهتر، امکان پیادهسازی الگوریتمهای پیچیدهتر و کارآمدتر یادگیری فدراتیو را فراهم خواهد کرد.
7.1.2 هوش مصنوعی تولیدی و یادگیری فدراتیو
ترکیب مدلهای زبانی بزرگ (LLMs) و هوش مصنوعی تولیدی با یادگیری فدراتیو، امکانات جدیدی را برای آموزش مدلهای شخصیسازی شده در عین حفظ حریم خصوصی ایجاد میکند. FedLLM به عنوان یک چارچوب نوید بخش برای آموزش فدراتیو مدلهای زبانی بزرگ در حال ظهور است.
7.2 چالشهای باقیمانده و راهحلهای آینده
7.2.1 مقیاسپذیری در محیطهای بزرگ
مقیاسپذیری در یادگیری فدراتیو یک چالش حیاتی است زیرا این رویکرد شامل آموزش مدل غیرمتمرکز در دستگاهها یا کلاینتهای متعدد است در حالی که حریم خصوصی دادهها حفظ میشود. مسائل کلیدی شامل گلوگاههای ارتباطی، بهویژه هنگام تجمیع بهروزرسانیها از مشارکتکنندگان زیاد، و محدودیتهای منابع در دستگاههای لبه است.
راهحلهای پیشنهادی:
- معماریهای یادگیری فدراتیو سلسلهمراتبی
- تجمیع بلاکچین غیرمتمرکز با قراردادهای هوشمند
- الگوریتمهای انتخاب کلاینت پویا بر اساس منابع و کیفیت داده
7.2.2 حفاظت در برابر حملات پیشرفته
با پیشرفت تکنیکهای حمله، نیاز به مکانیزمهای دفاعی قویتر احساس میشود. حملاتی مانند مسمومیت داده، حملات دروازه پشتی و استنتاج گرادیان عمیق نیازمند راهحلهای نوآورانه هستند.
رویکردهای آینده:
- استفاده از یادگیری تقویتی برای تشخیص رفتارهای مخرب
- پیادهسازی مکانیزمهای اعتبارسنجی چندلایه
- توسعه الگوریتمهای تجمیع مقاوم در برابر حمله
7.3 استانداردسازی و مقررات
7.3.1 چارچوبهای نظارتی
با گسترش کاربرد یادگیری فدراتیو، نیاز به چارچوبهای نظارتی و استانداردهای صنعتی بیشتر احساس میشود. سازمانهایی مانند IEEE و ISO در حال تدوین استانداردهایی برای یادگیری فدراتیو هستند.
7.3.2 مطابقت با مقررات حریم خصوصی
مقررات حریم خصوصی داده مانند GDPR و CCPA نیاز به در نظر گرفتن در هنگام پیادهسازی سیستمهای یادگیری فدراتیو دارند. انطباق با مقررات در حال تحول، اطمینان از رعایت و اعتماد کاربر را تضمین میکند.
7.4 فرصتهای پژوهشی آینده
بر اساس بررسیهای انجام شده، حوزههای زیر برای پژوهشهای آینده پیشنهاد میشوند:
1. یادگیری فدراتیو کوانتومی: بررسی پتانسیل محاسبات کوانتومی برای بهبود کارایی و امنیت یادگیری فدراتیو
2. یادگیری فدراتیو خودتنظیم: توسعه سیستمهایی که به صورت خودکار پارامترها را بر اساس شرایط شبکه و کیفیت داده تنظیم میکنند
3. یادگیری فدراتیو بیندامنهای: امکان همکاری بین سازمانها در دامنههای مختلف با حفظ حریم خصوصی
4. یادگیری فدراتیو سبز: بهینهسازی مصرف انرژی در سیستمهای یادگیری فدراتیو برای کاهش اثرات زیستمحیطی
8. مطالعات موردی و پیادهسازیهای موفق
8.1 پروژه MELLODDY در صنعت داروسازی
کنسرسیوم MELLODDY شامل ۱۰ شرکت داروسازی بزرگ، پیشگام در استفاده از Federated Learning مبتنی بر بلاکچین برای کشف دارو است. این پروژه نشان داد که شرکتهای رقیب میتوانند در صورت اطمینان از عدم به اشتراکگذاری دادهها، با یکدیگر همکاری کنند.
8.2 یادگیری فدراتیو در خودروهای خودران
خودروهای خودران با استفاده از Federated Learning میتوانند از تجربیات رانندگی یکدیگر بیاموزند بدون اینکه دادههای حساس موقعیت یا رفتار رانندگان را به اشتراک بگذارند. این امر منجر به بهبود ایمنی و عملکرد کلی ناوگان میشود.
8.3 سیستمهای توصیهگر حافظ حریم خصوصی
پلتفرمهای آنلاین با استفاده از Federated Learning، سیستمهای توصیهگر شخصیسازی شدهای ایجاد میکنند که بدون دسترسی مستقیم به دادههای کاربران، ترجیحات آنها را یاد میگیرند.
9. توصیههای عملی برای پیادهسازی
9.1 انتخاب معماری مناسب
انتخاب معماری یادگیری فدراتیو باید بر اساس موارد زیر صورت گیرد:
- نوع و حجم دادهها
- تعداد و توزیع جغرافیایی کلاینتها
- الزامات حریم خصوصی و امنیتی
- محدودیتهای منابع محاسباتی و ارتباطی
9.2 پیادهسازی گامبهگام
گام 1: ارزیابی نیازمندیها و محدودیتهای سیستم
2: انتخاب چارچوب و ابزارهای مناسب (مانند TensorFlow Federated، PySyft، یا FATE)
3: طراحی پروتکلهای امنیتی و حریم خصوصی
4: پیادهسازی آزمایشی با تعداد محدود کلاینت
5: ارزیابی عملکرد و بهینهسازی
6: گسترش تدریجی و مقیاسدهی
9.3 معیارهای ارزیابی
برای ارزیابی موفقیت یک سیستم یادگیری فدراتیو، معیارهای زیر باید در نظر گرفته شوند:
- دقت مدل: مقایسه با یادگیری متمرکز سنتی
- کارایی ارتباطی: حجم دادههای منتقل شده و تعداد دورهای ارتباطی
- مقاومت در برابر حمله: توانایی سیستم در حفظ عملکرد در حضور کلاینتهای مخرب
- حفظ حریم خصوصی: سطح حفاظت از دادههای کاربران
- مقیاسپذیری: عملکرد با افزایش تعداد کلاینتها
10. نتیجهگیری
یادگیری فدراتیو به عنوان یک پارادایم نوآورانه در یادگیری ماشین، پتانسیل تحولآفرینی در نحوه آموزش مدلهای هوش مصنوعی با حفظ حریم خصوصی را دارد. با وجود چالشهای متعددی که این فناوری با آن مواجه است، پیشرفتهای اخیر در ترکیب آن با فناوریهایی مانند رمزنگاری همومورفیک، حریم خصوصی تفاضلی و بلاکچین، راه را برای کاربردهای گستردهتر و امنتر هموار کرده است.
آینده Federated Learning در گرو توسعه راهحلهای نوآورانه برای مقابله با چالشهای ناهمگونی دادهها، بهبود کارایی ارتباطی و محاسباتی، و تقویت مکانیزمهای امنیتی است. با توجه به روند فعلی و سرمایهگذاریهای انجام شده در این حوزه، انتظار میرود که یادگیری فدراتیو نقش کلیدی در شکلدهی آینده هوش مصنوعی حافظ حریم خصوصی ایفا کند.
همانطور که به سمت عصری پیش میرویم که در آن دادهها بیش از پیش ارزشمند و حساس میشوند، Federated Learning نه تنها یک انتخاب، بلکه یک ضرورت برای سازمانهایی است که میخواهند از قدرت یادگیری ماشین بهرهمند شوند در حالی که به حریم خصوصی کاربران احترام میگذارند. موفقیت این فناوری در نهایت به توانایی جامعه پژوهشی و صنعت در همکاری برای حل چالشهای باقیمانده و توسعه استانداردها و بهترین شیوههای عملی بستگی خواهد داشت.
منابع و مراجع
مزیت اصلی یادگیری فدراتیو در ظرفیت آن برای انجام آموزش مشارکتی دادهها نمایان میشود در حالی که از به اشتراکگذاری دادههای خام خودداری میکند، که برای محافظت از حریم خصوصی کاربران و رعایت مقررات حفاظت از دادهها حیاتی است.
تحقیقات نشان میدهد که مدلهای فدراتیو میتوانند دقت، صحت و قابلیت تعمیم مشابهی با مدلهای آماری متمرکز استاندارد داشته باشند در حالی که حفاظتهای حریم خصوصی قابل توجهی قویتری را ارائه میدهند.
یادگیری فدراتیو تکنیک یادگیری ماشین توزیعشدهای است که از چندین سرور برای به اشتراکگذاری بهروزرسانیهای مدل بدون تبادل دادههای خام استفاده میکند و به غلبه بر حساسیت به دادهها و فناوری حفاظت از حریم خصوصی کمک میکند.