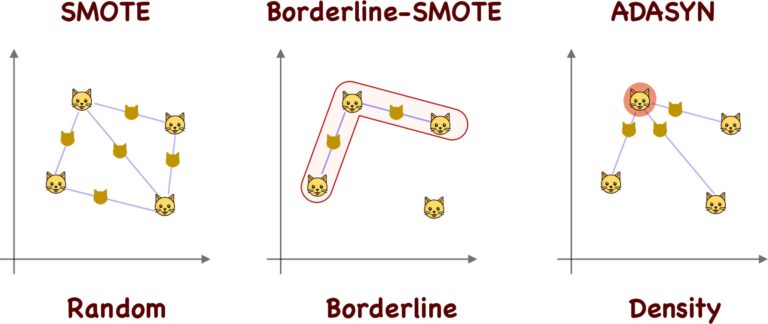
رگرسیون یکی از تکنیکهای اساسی در یادگیری ماشین و آمار است که برای مدلسازی و تحلیل روابط بین متغیرها استفاده میشود. این تکنیک به ما امکان میدهد تا با استفاده از دادههای موجود، پیشبینیهایی در مورد دادههای آینده انجام دهیم. در این مقاله، به بررسی جامع و کاربردی الگوریتمهای رگرسیون میپردازیم و نحوه استفاده از آنها را در مسائل واقعی توضیح میدهیم.
مفهوم رگرسیون
رگرسیون فرآیندی است که در آن یک متغیر وابسته (پاسخ) بر اساس یک یا چند متغیر مستقل (پیشبینیکننده) مدلسازی میشود. هدف اصلی رگرسیون، یافتن رابطهای است که بتواند تغییرات متغیر وابسته را با توجه به تغییرات متغیرهای مستقل توضیح دهد.
انواع الگوریتمهای رگرسیون
الگوریتمهای رگرسیون به دو دسته اصلی تقسیم میشوند: رگرسیون خطی و رگرسیون غیرخطی. در ادامه به بررسی هر یک از این دستهها و الگوریتمهای مربوطه میپردازیم.
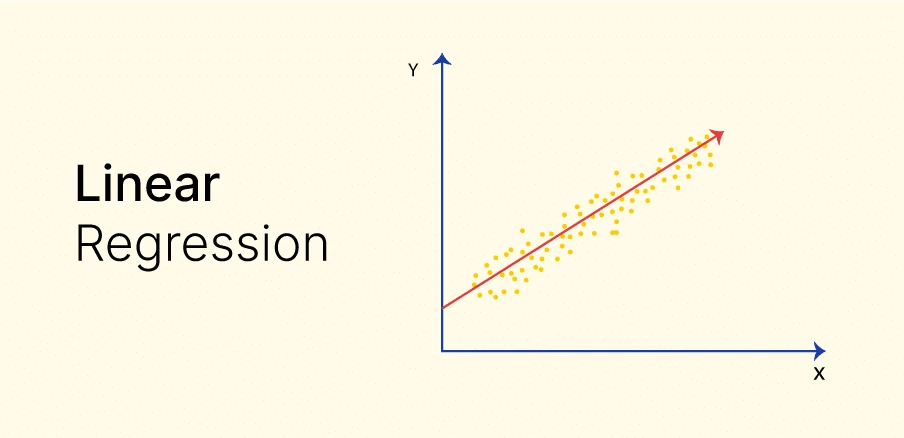
رگرسیون خطی
رگرسیون خطی یکی از سادهترین و پرکاربردترین الگوریتمهای رگرسیون است که فرض میکند رابطه بین متغیر وابسته و متغیرهای مستقل خطی است. این الگوریتم به دو دسته تقسیم میشود: رگرسیون خطی ساده و رگرسیون خطی چندگانه.
رگرسیون خطی ساده
در رگرسیون خطی ساده، تنها یک متغیر مستقل وجود دارد. مدل رگرسیون خطی ساده به صورت زیر تعریف میشود:
[ y = \beta_0 + \beta_1 x + \epsilon ]
که در آن:
- ( y ) متغیر وابسته است.
- ( x ) متغیر مستقل است.
- ( \beta_0 ) و ( \beta_1 ) ضرایب رگرسیون هستند.
- ( \epsilon ) خطای مدل است.
هدف از رگرسیون خطی ساده، پیدا کردن مقادیر بهینه برای ( \beta_0 ) و ( \beta_1 ) است که خطای مدل را به حداقل برساند.
رگرسیون خطی چندگانه
در رگرسیون خطی چندگانه، بیش از یک متغیر مستقل وجود دارد. مدل رگرسیون خطی چندگانه به صورت زیر تعریف میشود:
[ y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \cdots + \beta_n x_n + \epsilon ]
که در آن:
- ( y ) متغیر وابسته است.
- ( x_1, x_2, \ldots, x_n ) متغیرهای مستقل هستند.
- ( \beta_0, \beta_1, \beta_2, \ldots, \beta_n ) ضرایب رگرسیون هستند.
- ( \epsilon ) خطای مدل است.
هدف از رگرسیون خطی چندگانه، پیدا کردن مقادیر بهینه برای ضرایب رگرسیون است که خطای مدل را به حداقل برساند.
رگرسیون غیرخطی
رگرسیون غیرخطی برای مدلسازی روابط پیچیدهتر بین متغیرهای وابسته و مستقل استفاده میشود. در این نوع رگرسیون، رابطه بین متغیرها خطی نیست و ممکن است به صورت توابع غیرخطی مانند توابع نمایی، لگاریتمی و چندجملهای باشد.
رگرسیون چندجملهای
رگرسیون چندجملهای یکی از انواع رگرسیون غیرخطی است که رابطه بین متغیر وابسته و متغیرهای مستقل را به صورت چندجملهای مدلسازی میکند. مدل رگرسیون چندجملهای به صورت زیر تعریف میشود:
[ y = \beta_0 + \beta_1 x + \beta_2 x^2 + \cdots + \beta_n x^n + \epsilon ]
که در آن:
- ( y ) متغیر وابسته است.
- ( x ) متغیر مستقل است.
- ( \beta_0, \beta_1, \beta_2, \ldots, \beta_n ) ضرایب رگرسیون هستند.
- ( \epsilon ) خطای مدل است.
رگرسیون لگاریتمی
در رگرسیون لگاریتمی، رابطه بین متغیر وابسته و متغیرهای مستقل به صورت لگاریتمی مدلسازی میشود. مدل رگرسیون لگاریتمی به صورت زیر تعریف میشود:
[ y = \beta_0 + \beta_1 \log(x) + \epsilon ]
که در آن:
- ( y ) متغیر وابسته است.
- ( x ) متغیر مستقل است.
- ( \beta_0 ) و ( \beta_1 ) ضرایب رگرسیون هستند.
- ( \epsilon ) خطای مدل است.
رگرسیون نمایی
در رگرسیون نمایی، رابطه بین متغیر وابسته و متغیرهای مستقل به صورت نمایی مدلسازی میشود. مدل رگرسیون نمایی به صورت زیر تعریف میشود:
[ y = \beta_0 e^{\beta_1 x} + \epsilon ]
که در آن:
- ( y ) متغیر وابسته است.
- ( x ) متغیر مستقل است.
- ( \beta_0 ) و ( \beta_1 ) ضرایب رگرسیون هستند.
- ( \epsilon ) خطای مدل است.
ارزیابی مدلهای رگرسیون
برای ارزیابی مدلهای رگرسیون، از معیارهای مختلفی استفاده میشود. در ادامه به برخی از این معیارها اشاره میکنیم:
ضریب تعیین (R^2)
ضریب تعیین یا ( R^2 ) یکی از معیارهای اصلی برای ارزیابی مدلهای رگرسیون است. این معیار نشان میدهد که چه مقدار از تغییرات متغیر وابسته توسط مدل توضیح داده میشود. مقدار ( R^2 ) بین ۰ و ۱ قرار دارد و هرچه به ۱ نزدیکتر باشد، مدل بهتر است.
میانگین مربعات خطا (MSE)
میانگین مربعات خطا یا ( MSE ) یکی دیگر از معیارهای ارزیابی مدلهای رگرسیون است. این معیار میانگین مربعات تفاوت بین مقادیر واقعی و مقادیر پیشبینی شده توسط مدل را اندازهگیری میکند. مقدار کمتر ( MSE ) نشاندهنده مدل بهتر است.
میانگین قدر مطلق خطا (MAE)
میانگین قدر مطلق خطا یا ( MAE ) نیز یکی دیگر از معیارهای ارزیابی مدلهای رگرسیون است. این معیار میانگین قدر مطلق تفاوت بین مقادیر واقعی و مقادیر پیشبینی شده توسط مدل را اندازهگیری میکند. مقدار کمتر ( MAE ) نشاندهنده مدل بهتر است.
کاربردهای رگرسیون
الگوریتمهای رگرسیون در بسیاری از زمینهها و صنایع مختلف کاربرد دارند. در ادامه به برخی از این کاربردها اشاره میکنیم:
پیشبینی فروش
یکی از کاربردهای اصلی رگرسیون، پیشبینی فروش است. با استفاده از دادههای تاریخی فروش و متغیرهای مستقل مانند قیمت، تبلیغات و فصل، میتوان مدل رگرسیون را برای پیشبینی فروش آینده استفاده کرد.
تحلیل ریسک
در صنعت مالی، رگرسیون برای تحلیل ریسک و پیشبینی بازدهی سرمایهگذاریها استفاده میشود. با استفاده از دادههای تاریخی بازار و متغیرهای مستقل مانند نرخ بهره و نرخ تورم، میتوان مدل رگرسیون را برای تحلیل ریسک و پیشبینی بازدهی سرمایهگذاریها استفاده کرد.
پیشبینی آب و هوا
رگرسیون نیز در پیشبینی آب و هوا کاربرد دارد. با استفاده از دادههای تاریخی آب و هوا و متغیرهای مستقل مانند دما، رطوبت و فشار هوا، میتوان مدل رگرسیون را برای پیشبینی آب و هوای آینده استفاده کرد.
تحلیل بازاریابی
در بازاریابی، رگرسیون برای تحلیل تاثیر عوامل مختلف بر فروش و رفتار مشتریان استفاده میشود. با استفاده از دادههای تاریخی فروش و متغیرهای مستقل مانند تبلیغات، قیمت و ویژگیهای محصول، میتوان مدل رگرسیون را برای تحلیل بازاریابی استفاده کرد.
پیادهسازی الگوریتمهای رگرسیون
در این بخش، به پیادهسازی الگوریتمهای رگرسیون با استفاده از زبان برنامهنویسی پایتون و کتابخانههای معروف آن میپردازیم.
پیادهسازی رگرسیون خطی ساده
برای پیادهسازی رگرسیون خطی ساده، از کتابخانه scikit-learn استفاده میکنیم. در ادامه کد مربوط به پیادهسازی رگرسیون خطی ساده آورده شده است:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
# دادههای نمونه
X = np.array([1, 2, 3, 4, 5]).reshape(-1, 1)
y = np.array([1, 3, 2, 5, 4])
# ایجاد مدل رگرسیون خطی
model = LinearRegression()
model.fit(X, y)
# پیشبینی مقادیر
y_pred = model.predict(X)
# رسم نمودار
plt.scatter(X, y, color='blue')
plt.plot(X, y_pred, color='red')
plt.xlabel('X')
plt.ylabel('y')
plt.title('رگرسیون خطی ساده')
plt.show()
پیادهسازی رگرسیون خطی چندگانه
برای پیادهسازی رگرسیون خطی چندگانه، از کتابخانه scikit-learn استفاده میکنیم. در ادامه به کدهای مربوط به پیادهسازی رگرسیون خطی چندگانه می پردازیم:
import numpy as np
from sklearn.linear_model import LinearRegression
# دادههای نمونه
X = np.array([[1, 1], [2, 2], [3, 3], [4, 4], [5, 5]])
y = np.array([1, 3, 2, 5, 4])
# ایجاد مدل رگرسیون خطی
model = LinearRegression()
model.fit(X, y)
# پیشبینی مقادیر
y_pred = model.predict(X)
print('مقادیر پیشبینی شده:', y_pred)
پیادهسازی رگرسیون چندجملهای
برای پیادهسازی رگرسیون چندجملهای، از کتابخانه scikit-learn و PolynomialFeatures استفاده میکنیم. در ادامه به کد مربوط به پیادهسازی رگرسیون چندجملهای میپردازیم :
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
# دادههای نمونه
X = np.array([1, 2, 3, 4, 5]).reshape(-1, 1)
y = np.array([1, 3, 2, 5, 4])
# ایجاد ویژگیهای چندجملهای
poly = PolynomialFeatures(degree=2)
X_poly = poly.fit_transform(X)
# ایجاد مدل رگرسیون چندجملهای
model = LinearRegression()
model.fit(X_poly, y)
# پیشبینی مقادیر
y_pred = model.predict(X_poly)
# رسم نمودار
plt.scatter(X, y, color='blue')
plt.plot(X, y_pred, color='red')
plt.xlabel('X')
plt.ylabel('y')
plt.title('رگرسیون چندجملهای')
plt.show()نتیجهگیری
در این مقاله، به بررسی جامع و کاربردی الگوریتمهای رگرسیون پرداختیم و نحوه استفاده از آنها را در مسائل واقعی توضیح دادیم. همچنین، به پیادهسازی الگوریتمهای رگرسیون با استفاده از زبان برنامهنویسی پایتون و کتابخانههای معروف آن پرداختیم. الگوریتمهای رگرسیون ابزارهای قدرتمندی برای مدلسازی و تحلیل روابط بین متغیرها هستند و میتوانند در بسیاری از زمینهها و صنایع مختلف کاربرد داشته باشند. با استفاده از این الگوریتمها، میتوانید پیشبینیهای دقیقی انجام دهید و تصمیمات بهتری بگیرید.