در چشمانداز همیشه در حال تکامل هوش مصنوعی، یادگیری تقویتی (RL) بهعنوان یک رویکرد پیشگامانه ظهور کرده است که ماشینها را قادر میکند ازطریق تعامل مستمر با محیط خود یاد بگیرند و تصمیم بگیرند. در این مقاله، مفهوم یادگیری تقویتی، رابطهی آن با یادگیری ماشین، نحوهی کارکرد، کاربردهای آن در حوزههای مختلف و محدودیتهای ذاتیاش را بررسی خواهیم کرد.
یادگیری ماشین، یک زیرشاخه از هوش مصنوعی است که بر توسعه الگوریتمها و مدلهایی تمرکز دارد که به صورت خودکار از دادهها یاد میگیرند و عملکرد خود را در طول زمان بدون نیاز به برنامهریزی صریح بهبود میبخشند. این حوزه شامل الگوهای یادگیری متنوعی است، از جمله یادگیری تحت نظارت، یادگیری بدون نظارت و یادگیری تقویتی.
یادگیری تقویتی (Reinforcement Learning)
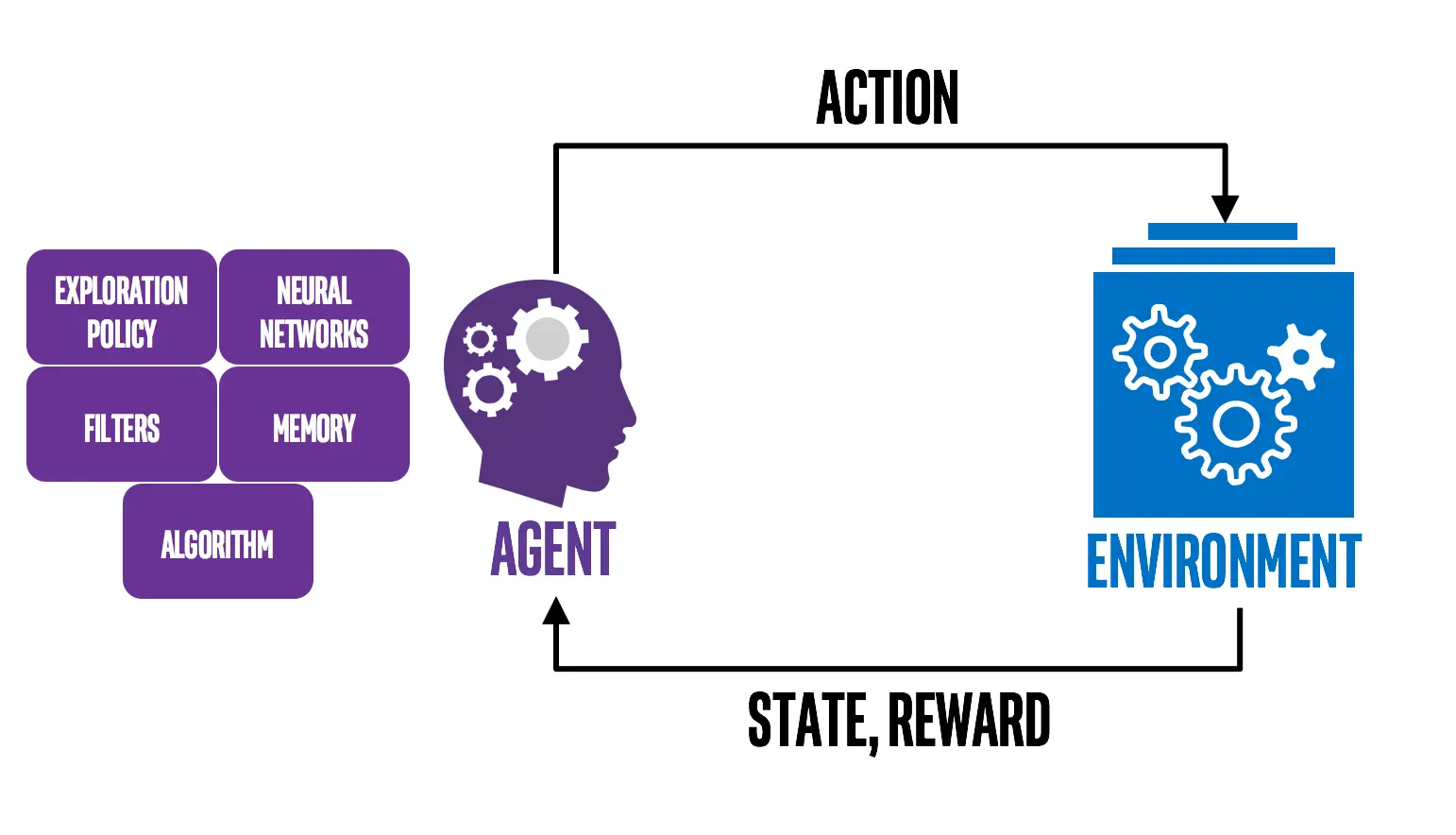
یادگیری تقویتی (Reinforcement Learning) یک روش یادگیری ماشین است که در آن یک عامل (Agent) در یک محیط قرار میگیرد و از طریق آزمون و خطا یاد میگیرد که چگونه با آن محیط تعامل داشته باشد. عامل بر اساس اقدامات خود بازخوردی را در قالب پاداش یا جریمه دریافت میکند. هدف عامل یادگیری یک خطمشی بهینه است که پاداشهای تجمعی را در طول زمان به حداکثر میرساند.
این نوع یادگیری یکی از سه دسته اصلی یادگیری ماشین است. دو دسته دیگر عبارتاند از یادگیری نظارتی و یادگیری بدون نظارت. در یادگیری نظارتی، دادههای آموزشی شامل برچسبهای پاسخ برای هر مثال است. در یادگیری بدون نظارت، دادههای آموزشی شامل برچسبهای پاسخ نیستند.
چرخه کار یادگیری تقویتی
در یادگیری تقویتی، عامل در یک چرخه مداوم قرار دارد که مراحل زیر شامل آن میشود:
مشاهدۀ حالت: عامل وضعیت فعلی محیط را دریافت میکند.
انتخاب عمل: بر اساس سیاست خود، عملی انتخاب میکند.
اجرای عمل: عامل عمل را انجام داده و محیط تغییر میکند.
دریافت پاداش: عامل پاداش یا تنبیه مربوط به عمل یا وضعیت جدید را دریافت میکند.
بهروزرسانی سیاست یا تابع ارزش: عامل بر اساس تجربه به دست آمده، استراتژیهای خود را بهبود میبخشد.
این چرخه تا زمانی که عامل به سیاست بهینه (Optimal Policy) نرسد، تکرار میشود.
الگوریتمهای رایج در یادگیری تقویتی
تعدادی از الگوریتمهای مشهور در این حوزه عبارتند از:
Q-Learning: یکی از سادهترین و کارآمدترین الگوریتمها بوده که تابع Q را برای هر جفت حالت-عمل بهروزرسانی میکند.
SARSA: الگوریتمی که تفاوتهای آن در انتخاب عمل بعدی بر اساس سیاست کنونی عامل است.
Policy Gradients: در این روش، به طور مستقیم سیاست بهینه را با استفاده از تکنیکهای گرادیان پیدا میکنند.
Deep Reinforcement Learning: ترکیب یادگیری عمیق (Deep Learning) و یادگیری تقویتی برای کار با دادههای پیچیده و پیوسته.
عامل در یادگیری تقویتی، از طریق آزمونوخطا، محیط را بررسی میکند، اقداماتی را براساس وضعیت فعلی آن انجام میدهد و بازخورد دریافت میکند. از این بازخورد برای بهروزرسانی خطمشی خود و اتخاذ تصمیمهای بهتر در آینده استفاده میکند.
الگوریتمهای RL، روشهایی هستند که به عامل کمک میکنند تا خطمشی خود را یاد بگیرد. الگوریتمهای یادگیری تقویتی، بر اساس نحوهی استفاده از بازخورد برای بهروزرسانی خطمشی، به دو دسته کلی تقسیم میشوند:
- الگوریتمهای مبتنی بر ارزش (Value-based): در این الگوریتمها، عامل با تخمین ارزش هر حالت و اقدام، خطمشی خود را یاد میگیرد.
- الگوریتمهای مبتنی بر سیاست (Policy-based): در این الگوریتمها، عامل با مستقیماً بهروزرسانی خطمشی خود، یادگیری را انجام میدهد.
کاربردهای یادگیری تقویتی
کاربردهای RL در زمینههای مختلف بسیار گسترده است. برخی از کاربردهای مهم RL عبارتند از:
بازیهای کامپیوتری
RL در توسعهی بازیهای کامپیوتری، بهویژه بازیهای استراتژیک و اکشن، کاربرد گستردهای دارد. به عنوان مثال، RL برای آموزش هوش مصنوعی در بازیهایی مانند شطرنج، گو، و پوکمون گو استفاده میشود.
رباتیک
RL در توسعهی رباتهای هوشمند، بهویژه رباتهایی که در محیطهای پیچیده عمل میکنند، کاربرد دارد. به عنوان مثال، RL برای آموزش رباتها برای انجام وظایفی مانند راه رفتن، بلند کردن اجسام، و تعامل با انسانها استفاده میشود.
اقتصاد
یادگیری تقویتی در مدلسازی رفتار اقتصادی، بهویژه رفتار سرمایهگذاران، کاربرد دارد. به عنوان مثال، این نوع یادگیری برای توسعهی الگوریتمهای معاملات خودکار استفاده میشود که میتوانند عملکرد بهتری نسبت به سرمایهگذاران انسانی داشته باشند.
شبکههای حمل و نقل
RL برای بهبود عملکرد شبکههای حمل و نقل، مانند ترافیک هوایی، جادهای، و ریلی، کاربرد دارد. به عنوان مثال، این نوع یادگیری برای توسعهی الگوریتمهای کنترل ترافیک استفاده میشود که میتوانند ترافیک را روانتر و کارآمدتر کنند.
سیستمهای تولید
RL برای بهبود عملکرد سیستمهای تولید، مانند کارخانهها و تأسیسات صنعتی، کاربرد دارد. به عنوان مثال، RL برای توسعهی الگوریتمهای کنترل تولید استفاده میشود که میتوانند بهرهوری را افزایش دهند و هزینهها را کاهش دهند.
امنیت
این نوع یادگیری برای بهبود امنیت سیستمهای کامپیوتری و شبکهها، مانند سیستمهای تشخیص نفوذ و سیستمهای ضد بدافزار، کاربرد دارد. به عنوان مثال، RL برای توسعهی الگوریتمهایی استفاده میشود که میتوانند تهدیدات سایبری جدید را شناسایی کنند.
پزشکی
RL برای بهبود تشخیص و درمان بیماریها، به ویژه بیماریهای مزمن، کاربرد دارد. به عنوان مثال، این نوع یادگیری برای توسعهی الگوریتمهایی استفاده میشود که میتوانند علائم بیماری را زودتر تشخیص دهند و درمانهای موثرتری را پیشنهاد دهند.
این نوع یادگیری در سالهای اخیر پیشرفتهای زیادی داشته است. این پیشرفتها به دلیل توسعه الگوریتمهای جدید یادگیری تقویتی عمیق و افزایش قدرت محاسباتی بوده است.
یادگیری تقویتی عمیق در زمینههای مختلفی کاربرد دارد، از جمله:
- بازیهای کامپیوتری:</strong> یادگیری تقویتی عمیق برای آموزش کامپیوترها برای انجام بازیهای کامپیوتری به سطح بالایی از مهارت استفاده میشود. بهعنوان مثال، الگوریتم یادگیری تقویتی عمیق DeepMind AlphaGo در سال ۲۰۱۶ توانست قهرمان بازی Go را شکست دهد.
- <strong>رباتیک:</strong&gt; یادگیری تقویتی عمیق برای آموزش رباتها برای انجام وظایف پیچیده در محیطهای واقعی استفاده میشود. بهعنوان مثال، الگوریتم یادگیری تقویتی عمیق OpenAI Roboschool برای آموزش رباتها برای انجام وظایف مختلفی مانند راه رفتن، دویدن و پریدن استفاده میشود.
- <strong>اقتصاد:</strong> یادگیری تقویتی عمیق برای مدلسازی رفتار اقتصادی استفاده میشود. بهعنوان مثال، الگوریتم یادگیری تقویتی عمیق DeepMind AlphaZero برای مدلسازی رفتار سرمایهگذاران در بازارهای مالی استفاده میشود.
الگوریتمهای Reinforcement Learning
الگوریتمهای یادگیری تقویتی عمیق، بر اساس رویکردهای ارزش محور، سیاست محور و مدل محور طراحی میشوند. برخی از الگوریتمهای یادگیری تقویتی عمیق عبارتند از:
- Q-learning: Q-learning یک الگوریتم یادگیری تقویتی ارزش محور است که از شبکههای عصبی عمیق برای یادگیری ارزش هر حالت و اقدام استفاده میکند.
- Policy gradient: Policy gradient یک الگوریتم یادگیری تقویتی سیاست محور است که از شبکههای عصبی عمیق برای یادگیری مستقیم خطمشی عامل استفاده میکند.
- Actor-critic: Actor-critic یک الگوریتم یادگیری تقویتی ترکیبی است که از یک شبکه عصبی عمیق برای یادگیری خطمشی عامل و از یک شبکه عصبی عمیق دیگر برای یادگیری ارزش حالتها استفاده میکند.
نوع دادههای آموزشی
در یادگیری تحت نظارت، دادههای آموزشی شامل جفتهای (ورودی، خروجی) هستند. ورودیها ویژگیهای دادهها هستند و خروجیها پاسخهای مطلوب هستند. هدف الگوریتمهای یادگیری تحت نظارت یادگیری یک تابعی است که ورودیها را به خروجیهای مطلوب مرتبط میکند.
در یادگیری بدون نظارت، دادههای آموزشی شامل مجموعهای از دادهها هستند که برچسبگذاری نشدهاند. هدف الگوریتمهای یادگیری بدون نظارت یافتن الگوها یا ساختارهای پنهان در دادهها است.
در RL، دادههای آموزشی شامل مجموعهای از تعاملات بین یک عامل و محیط هستند. هر تعامل شامل یک حالت، اقدام و پاداش است. هدف عامل یادگیری خطمشیای است که پاداشهای تجمعی را در طول زمان به حداکثر میرساند.
نوع بازخورد
در یادگیری تحت نظارت، بازخورد بهصورت پاسخهای مطلوب ارائه میشود. این بازخورد به الگوریتمها اجازه میدهد تا خطمشیهای دقیقی را یاد بگیرند.
در یادگیری بدون نظارت، بازخورد بهصورت ساختارها یا الگوهای پنهان ارائه میشود. این بازخورد به الگوریتمها اجازه میدهد تا درک عمیقتری از دادهها به دست آورند.
در یادگیری تقویتی، بازخورد بهصورت پاداشها ارائه میشود. پاداشها نشاندهنده مطلوبیت یا عدم مطلوبیت اقدامات عامل هستند.
نحوه یادگیری
در یادگیری تحت نظارت، الگوریتمها با استفاده از الگوریتمهای برآوردگر خطی یا غیرخطی، پاسخهای مطلوب را از دادههای آموزشی یاد میگیرند.
همچنین در یادگیری بدون نظارت، الگوریتمها با استفاده از الگوریتمهای خوشهبندی، کاهش ابعاد یا یادگیری خود سازماندهی، الگوها یا ساختارهای پنهان را از دادههای آموزشی یاد میگیرند.
مسائل قابل حل
یادگیری تحت نظارت برای مسائلی مناسب است که پاسخهای مطلوب برای دادههای آموزشی در دسترس هستند. نمونههایی از این مسائل عبارتند از طبقهبندی، تخمین و کنترل.
یادگیری بدون نظارت برای مسائلی مناسب است که الگوها یا ساختارهای پنهان در دادهها وجود دارند. نمونههایی از این مسائل عبارتند از خوشهبندی، کاهش ابعاد و یادگیری خود سازماندهی.
یادگیری تقویتی برای مسائلی مناسب است که عامل باید در محیطی تعامل داشته باشد و پاداشهای تجمعی را در طول زمان به حداکثر برساند. نمونههایی از این مسائل عبارتند از بازیها، رباتیک و کنترل فرآیندها.
سخن پایانی
RL به ماشینها امکان یادگیری از تجربیات و تصمیمگیری هوشمندانه را میدهد. این ابزار قدرتمند در حوزههای مختلف از رباتیک تا بازی و مدیریت منابع کاربردهای گستردهای دارد. برای بهرهمندی موثر از پتانسیل این نوع یادگیری شناخت عملکرد و محدودیتهای آن ضروری است. با ادامه پژوهشها و بهبود الگوریتمهای RL، انتظار میرود که پیشرفتها و کاربردهای جدیدی در آینده مشاهده شود.