در عصر حاضر، هوش مصنوعی (Artificial Intelligence) بخش مهمی از صنایع مختلف را فراگرفته است و پایه و اساس بسیاری از ابزارهای هوشمند را تشکیل میدهد. هر سامانه هوش مصنوعی برای یادگیری و تصمیمگیری نیازمند داده است؛ بهعبارت دیگر، کیفیت و نوع دادهها نقش بسیار مؤثری در دقت و عملکرد مدلهای هوش مصنوعی ایفا میکنند. قبل از آموزش هر مدل، درک عمیق انواع مختلف دادهها و چگونگی آمادهسازی (پیشپردازش) آنها ضروری است تا مدل بتواند اطلاعات مفید را از ورودیها استخراج کند.
انواع داده در هوش مصنوعی
داده در حوزه هوش مصنوعی میتواند به اشکال و قالبهای متنوعی وجود داشته باشد. با توجه به کاربردها و ویژگیهای هر نوع داده، مدلهای متفاوتی برای پردازش و یادگیری استفاده میشوند. در ادامه مهمترین انواع داده را معرفی کرده و ویژگیها و کاربردهای هر یک را بیان میکنیم.
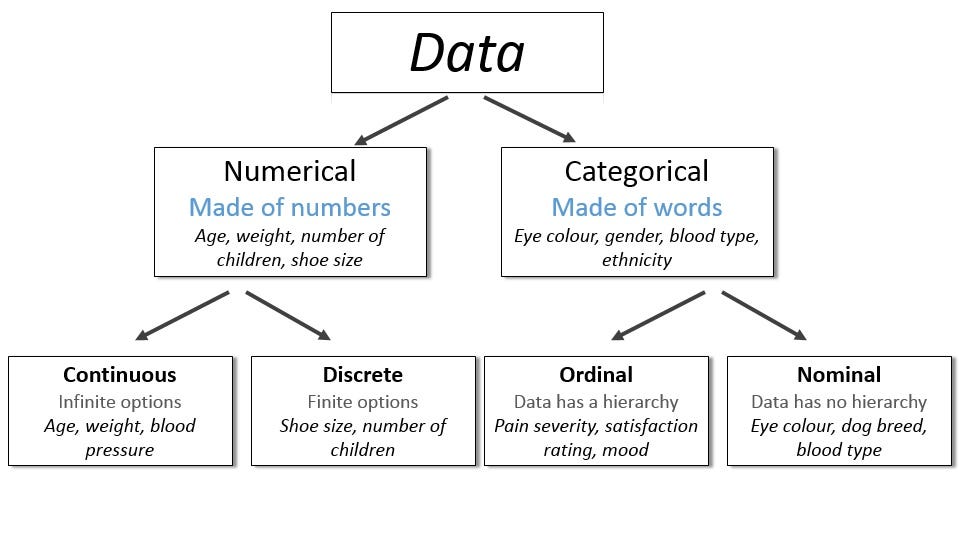
۱. دادههای عددی (Numerical Data)
تعریف و ویژگیها
دادههای عددی، که به «کمی» یا Quantitative نیز معروفاند، شامل مقادیری هستند که ماهیت عددی دارند و میتوانند پیوسته یا گسسته باشند.
- دادههای پیوسته (Continuous Data): مقادیری که در یک بازه بینهایت پیوسته قرار میگیرند؛ مانند دما، قیمت سهام یا وزن افراد.
- دادههای گسسته (Discrete Data): مقادیری که تنها در چند مقدار معین قابل تغییر هستند؛ مانند تعداد دانشآموزان، تعداد ماشینهای فروختهشده یا تعداد خطاهای یک نرمافزار در یک بازه زمانی مشخص.
دادههای عددی در بسیاری از مسائل یادگیری ماشین (مانند رگرسیون خطی، درخت تصمیم و جنگل تصادفی) کاربرد گستردهای دارند و اغلب بهعنوان پایه و اساس محاسبات آماری و مدلسازی استفاده میشوند.
مثال عملی
فرض کنید میخواهیم الگوریتمی برای پیشبینی قیمت خانه بسازیم. ویژگیهایی مانند مساحت زمین (مترمربع)، تعداد اتاقها (عدد صحیح) و تعداد سال ساخت (عدد صحیح) از نوع دادههای عددی هستند.
۲. دادههای طبقهای یا اسمی (Categorical/Qualitative Data)
تعریف و ویژگیها
دادههای طبقهای (Categorical Data) یا کیفی (Qualitative)، شامل مقادیری هستند که به صورت برچسب (Label) یا دستهبندی نمایش داده میشوند. این دادهها خود به دو دستهی کلی تقسیم میشوند:
- دادههای اسمی (Nominal): برچسبی بدون ترتیب واقعی؛ مانند رنگ خودرو (قرمز، آبی، مشکی)، جنسیت (مرد/زن) یا نام شهر.
- دادههای ترتیبی (Ordinal): برچسبهایی که یک ترتیب طبیعی دارند؛ مانند سطح تحصیلات (دیپلم < لیسانس < فوقلیسانس) یا درجه رضایت مشتری (ضعیف، متوسط، خوب، عالی).
هر دو نوع دادهی طبقهای در مسائل دستهبندی (Classification) و برخی الگوریتمهای یادگیری ماشین کاربرد دارند، اما قبل از استفاده معمولاً باید به شکل عددی (Encoded) تبدیل شوند؛ زیرا بیشتر الگوریتمها فقط با دادههای عددی کار میکنند. برای مثال، تکنیکهایی همچون One-Hot Encoding، Label Encoding یا Ordinal Encoding برای تبدیل دادههای اسمی به قالب عددی مورد استفاده قرار میگیرند.
مثال عملی
فرض کنید ما مجموعهدادهای داریم که شامل ویژگی «رنگ خودرو» (قرمز، آبی، مشکی) و «برند خودرو» (BMW، Mercedes، Toyota) است. قبل از اینکه این دادهها را به یک الگوریتم یادگیری ماشین بدهیم، باید از روشهایی مثل One-Hot Encoding برای ساخت ستونهای صفر و یک استفاده کنیم تا مدل بتواند بهدرستی آنها را تحلیل کند.
۳. دادههای سری زمانی (Time Series Data)
تعریف و ویژگیها
دادههای سری زمانی به مجموعهای از مشاهدات گفته میشوند که در فواصل زمانی (Second, Minute, Hour, Day و غیره) ثبت شدهاند. این نوع دادهها اهمیت ویژهای در حوزههایی مانند پیشبینی بازارهای مالی، تحلیل حسگرها، تشخیص نوسانات آبوهوا و سیستمهای کنترلی دارند؛ زیرا ترتیب ثبت دادهها و تغییرات زمانی نقش کلیدی در استخراج الگوها ایفا میکند.
در دادههای سری زمانی، ویژگیهایی مانند فراوانی نمونهگیری (Sampling Frequency)، ثبات نوسان (Stationarity) و فصلی بودن (Seasonality) مفهوم پیدا میکنند. همچنین برای تحلیل دقیق، معمولاً نیاز به تفکیک مجموعهدادهها به اجزای روند (Trend)، فصلی (Seasonal) و نویز (Noise) داریم.
پردازش و مثال عملی
بهعنوان مثال، پیشبینی قیمت سهام یک شرکت در هر دقیقه (یا هر روزنامه) از دستهی دادههای سری زمانی است. برای آمادهسازی چنین دادههایی، معمولاً مراحل زیر انجام میشود:
- بررسی نقاط گمشده (Missing Values): جایگزینی مقادیر از دسترفته با مقادیری مانند میانگین متحرک (Moving Average) یا استفاده از الگوریتمهای پیچیدهتر.
- استانداردسازی یا نرمالسازی: بهدلیل تغییرات دامنهی بزرگ در قیمت سهام، لازم است مقادیر را به بازهی مشخصی (مثل [0,1]) ببریم تا الگوریتمها سریعتر همگرا شوند.
- ایجاد ویژگیهای زمانی: استخراج ویژگیهایی نظیر «روز هفته»، «ماه سال»، «ساعت» یا «میانگین متحرک ۷ روزه» برای افزایش اطلاعات مدل.
- تقسیمبندی داده به صورت ترتیبی: بهعنوان مثال، ۷۰٪ ابتدا برای آموزش (Train) و ۳۰٪ انتهایی برای تست (Test) در نظر گرفته شود تا ترتیب زمانی حفظ شود و دادههای آینده برای تست نگه داشته شوند (نه بهصورت تصادفی).
۴. دادههای متنی (Text Data)
تعریف و ویژگیها
دادههای متنی یا Textual Data یکی از بزرگترین منابع داده در دنیای امروز هستند که در شبکههای اجتماعی، نظرات کاربران، مقالات علمی و گفتارها یافت میشوند. این نوع داده یک نوع دادهی بدون ساختار (Unstructured Data) محسوب میشود که برای استفاده در مدلهای یادگیری ماشین نیاز به استخراج ویژگی (Feature Extraction) دارد.
روشهای متداول برای تبدیل دادههای متنی به قالب قابلفهم برای مدل عبارتند از:
- Bag of Words (BoW): مدل سادهای که هر سند را به برداری از تکرار واژهها (Count Vector) یا وزندهی واژهها (TF-IDF) تبدیل میکند.
- Word Embeddings: استفاده از مدلهایی مانند Word2Vec، GloVe یا FastText برای نگاشت کلمات به بردارهای پیوسته در فضای چندبعدی؛ بردارهایی که روابط معنایی را حفظ میکنند.
- تبدیل پیشآموزشدیده (Pre-trained Models): بهرهگیری از کتابخانههایی مانند Hugging Face Transformers برای استخراج بردارهای سراسری (Contextual Embeddings) با استفاده از مدلهایی مثل BERT یا GPT. این روشها در کاربردهای پیشرفتهی تحلیل احساسات، بازیابی اطلاعات و تولید متن کاربرد دارند.
مثال عملی
فرض کنید قصد داریم تحلیل احساسات (Sentiment Analysis) روی نظرات کاربران یک فروشگاه آنلاین انجام دهیم. مراحل اصلی برای آمادهسازی دادههای متنی به شرح زیر است:
- پاکسازی اولیه متن (Text Cleaning): حذف علائم نگارشی، اعداد و کاراکترهای غیر متنی (مثل @، #) و تبدیل تمام حروف به حروف کوچک.
- حذف توقفواژهها (Stopwords Removal): حذف واژههای پرتکرار و بیفایده مانند «و»، «که»، «این» و غیره.
- Stemming یا Lemmatization: کاهش کلمات به ریشه یا شکل پایهای خود تا ابعاد بردار ویژگی کاهش یابد؛ مثلاً «میروم»، «رفتن» و «رفت» همگی به «رفت» تبدیل شوند.
- ایجاد بردار ویژگی: استفاده از روش TF-IDF یا بهرهگیری از مدلهای پیشآموزشدیده برای تولید Embedding.
- آموزش مدل: مثلاً یک مدل مبتنی بر Logistic Regression یا LSTM را با دادههای برداریشده آموزش دهیم و در نهایت برای پیشبینی احساس هر نظر استفاده کنیم.
۵. دادههای تصویری (Image Data)
تعریف و ویژگیها
دادههای تصویری از جنس پیکسل هستند؛ برای نمونه، عکسها با ابعاد عرض × ارتفاع × کانال (مثلاً RGB) نمایش داده میشوند. ترتیب نمایش دادهها معمولاً به صورت آرایههای سه یا چهاربعدی است (Batch × Height × Width × Channels).
این نوع دادهها در حوزه بینایی رایانهای (Computer Vision) کاربرد دارند؛ نظیر تشخیص اشیاء (Object Detection)، طبقهبندی تصویر (Image Classification)، تقسیمبندی معنایی (Semantic Segmentation) و غیره.
برای آمادهسازی دادههای تصویری، معمولاً مراحل زیر انجام میشود:
- Resize و Cropping: تغییر ابعاد تصویر یا گرفتن بخش موردنظر برای یکسانسازی ورودیها (مثلاً تمام تصاویر را به ابعاد 224×224 پیکسل برسانیم).
- نرمالسازی (Normalization): مقادیر پیکسل را به بازهی [0,1] یا (-1,1) تبدیل کنیم تا سرعت آموزش بالاتر برود و مدل سریعتر به همگرایی برسد.
- افزایش داده (Data Augmentation): اعمال تغییراتی مانند چرخش (Rotation)، برش تصادفی (Random Crop)، تغییر روشنایی (Brightness) یا وارونگی افقی (Horizontal Flip) برای تولید نمونههای متنوع و جلوگیری از بیشبازآموزی (Overfitting).
- استخراج ویژگی (Feature Extraction): در شبکههای عصبی کانولوشنی (CNN)، خود مدل بهصورت خودکار ویژگیهای سطح پایین (لبهها، بافتها) و سطح بالا (اشکال و اشیاء) را استخراج میکند.
مثال عملی
فرض کنید مجموعهدادهای از تصاویری داریم که در هر تصویر یک حیوان (گربه یا سگ) قرار دارد و هدف تشخیص نوع حیوان است. برای پیشپردازش:
- ابتدا همه تصاویر را به ابعاد ثابت مثلاً 224×224 برش میدهیم.
- سپس مقادیر پیکسلها را از [0,255] به [0,1] نرمالسازی میکنیم.
- برای هر تصویر، چند نسخه با چرخشهای تصادفی و تغییر میزان روشنایی ایجاد میکنیم تا مدل به تنوع شرایط عادت کند.
- در نهایت با استفاده از یک مدل CNN (مثل ResNet یا VGG) اقدام به آموزش خواهیم کرد.
۶. دادههای صوتی (Audio Data)
تعریف و ویژگیها
دادههای صوتی معمولاً به صورت سیگنالهای یکبعدی (Waveform) با فرکانس نمونهگیری مشخص (مثلاً 16 کیلوهرتز) ثبت میشوند. برای پردازش صوت بر روی مدلهای یادگیری ماشین و یادگیری عمیق، لازم است سیگنال اولیه را به ویژگیهای عددی (Features) تبدیل کنیم.
- MFCC (Mel-Frequency Cepstral Coefficients): یکی از متداولترین روشها برای استخراج ویژگی از فایل صوتی است.
- Spectrogram و Mel-Spectrogram: تبدیل سیگنال صوتی به نگاشت زمان-فرکانس که بهعنوان ورودی برای شبکههای عصبی کانولوشنی (CNN) مورد استفاده قرار میگیرد.
- ویژگیهای مرتبط با انرژی، تن و فرکانس: برای مثال، استخراج ویژگیهایی مانند Root Mean Square Energy، Zero Crossing Rate و Chromagram برای تحلیل صوت.
مثال عملی
اگر بخواهیم سیستمی برای تشخیص گفتار (Speech Recognition) یا تشخیص احساس از صدا (Emotion Recognition) بسازیم:
- فایل صوتی را با نرخ نمونهگیری 16 کیلوهرتز خوانده و در آرایهای ذخیره میکنیم.
- با استفاده از کتابخانهای مانند Librosa، MFCC یا Spectrogram را استخراج کرده و به قالب ماتریسی تبدیل میکنیم.
- در صورتی که از مدل CNN استفاده کنیم، Spectrogram را مانند یک تصویر به مدل میدهیم. در غیر این صورت، MFCCها را به عنوان ورودی به یک شبکه عصبی سلسلهمراتبی (مثل LSTM) میدهیم تا توالی زمانی صدا را تحلیل کند.
پیشپردازش دادهها
پیشپردازش داده (Data Preprocessing) به مجموعهٔ عملیاتی گفته میشود که روی دادههای خام انجام میشود تا آنها را در قالب و کیفیت مناسب برای الگوریتمهای یادگیری ماشین و هوش مصنوعی آماده سازد. طبق منابع معتبر، پیشپردازش مهمترین قسمت از طراحی یک پروژه یادگیری ماشین است، زیرا ۷۰–۸۰٪ زمان پروژه صرف این مراحل میشود.
۱. پاکسازی دادهها (Data Cleaning)
- حذف یا اصلاح مقادیر گمشده (Missing Values): از روشهایی مانند حذف سطر/ستونهای دارای دادههای زیاد مفقود، جایگزینی با میانگین یا میانه (برای دادههای عددی)، یا استفاده از روشهای Imputation پیشرفتهتر (مثل KNN Imputer یا مدلهای پیشبینی) استفاده میشود.
- حذف یا یکپارچهسازی دادههای ناسازگار و تکراری (Outliers & Duplicates): دادههای پرت (Outliers) را با روشهایی نظیر IQR یا فاصله استاندارد (Z-score) شناسایی و حذف یا تصحیح میکنند. رکوردهای تکراری (Duplicate Rows) را حذف میکنند تا از آلودگی مدل جلوگیری شود.
- اصلاح فرمت (Formatting): یکسانسازی فرمت تاریخها، حروف بزرگ/کوچک (Case Normalization) و حذف نویسههای غیرمجاز از متون.
۲. تبدیل ویژگی (Feature Transformation)
- نرمالسازی (Normalization): مقادیر عددی را به بازه مشخص (مثلاً [0,1]) تبدیل میکنند تا همه ویژگیها در یک مقیاس قرار گیرند؛ معمولاً از Min-Max Scaling استفاده میشود.
- استانداردسازی (Standardization): تبدیل مقادیر به توزیع نرمال استاندارد (میانگین صفر و انحراف معیار یک) با استفاده از فرمول z=x−μσz = \frac{x – \mu}{\sigma}. این روش برای الگوریتمهایی مثل SVM و K-Means مناسب است.
- تبدیل لگاریتمی (Log Transformation): کاهش کشیدگی توزیعهای نامتقارن (Skewed)؛ برای دادههایی که مقادیرشان چند مرتبه اختلاف دارند، از تبدیل لگاریتمی یا Box–Cox استفاده میشود.
۳. تبدیل دادههای طبقهای به عددی (Encoding)
همانطور که گفته شد، بیشتر الگوریتمها برای کار با دادهها نیازمند قالب عددی هستند. برای دادههای اسمی از روشهای زیر استفاده میشود:
- Label Encoding: به هر دسته عددی یکتا اختصاص میدهد (مانند تبدیل {قرمز، آبی، سبز} به {0،1،2}). برای دادههای ترتیبی خوب است ولی برای دادههای اسمی ممکن است مدل اشتباه برداشت ترتیبی از اعداد داشته باشد.
- One-Hot Encoding: برای هر دسته یک ستون اختصاص میدهد و در سطر معادل مقدار ۱ و در سایر ستونها مقدار صفر قرار میدهد. این روش از لحاظ جلوگیری از ایجاد ترتیب عددی مناسب است، ولی ممکن است تعداد ستونها را بسیار زیاد کند.
- Ordinal Encoding: برای دادههای دارای ترتیب از این روش استفاده میشود تا هر برچسب به یک عدد منطبق با ترتیب تبدیل شود.
۴. انتخاب و استخراج ویژگی (Feature Selection & Extraction)
- انتخاب ویژگی (Feature Selection): در این روش با استفاده از روشهای آماری (مثل ANOVA، همبستگی Correlation یا درخت تصمیم) یا روشهای پیچیدهتر (مانند Recursive Feature Elimination یا الگوریتمهای مبتنی بر LASSO) مهمترین ویژگیها شناسایی شده و سایر ویژگیهای غیرضروری حذف میشوند.
- استخراج ویژگی (Feature Extraction): تولید ویژگیهای جدید با ترکیب یا تغییر ویژگیهای اولیه. برای مثال، در دادههای متنی با استفاده از مدل Word2Vec، بردارهای واژهها را استخراج کرده و در دادههای تصویری با استفاده از شبکه کانولوشنی (CNN) لایههای میانی را بهعنوان ویژگی برداری (Embedding) میگیریم.
۵. کاهش ابعاد (Dimensionality Reduction)
در مجموعهدادههایی با تعداد ویژگی بسیار زیاد، فشردهسازی ابعاد و کاهش ابعاد میتواند به بهبود سرعت و دقت مدل کمک کند. مهمترین روشها عبارتاند از:
- PCA (Principal Component Analysis): نگاشت ویژگیها به فضای با ابعاد کمتر بهگونهای که بیشترین واریانس را حفظ کند.
- t-SNE یا UMAP: بهویژه برای بصریسازی (Visualization) در ابعاد کم (۲ یا ۳ بعد) مفیدند، اما به عنوان ورودی مستقیم مدلهای یادگیری ماشین معمولاً مناسب نیستند.
- LDA (Linear Discriminant Analysis): علاوه بر کاهش ابعاد، بهدنبال حداکثر تفکیک بین کلاسها هست.
۶. تقسیمبندی داده (Data Splitting)
در اغلب پروژههای یادگیری ماشین، مجموعهدادهها به سه بخش تقسیم میشوند:
- Train Set (مجموعه آموزشی): بخشی از داده که برای آموزش مدل استفاده میشود (مثلاً ۷۰٪ داده).
- Validation Set (مجموعه اعتبارسنجی): قسمتی که برای تنظیم ابرپارامترها و Tuning مدل استفاده میشود (مثلاً ۱۵٪ داده).
- Test Set (مجموعه آزمایشی): بخشی که برای ارزیابی عملکرد نهایی مدل روی دادههای ندیده استفاده میشود (مثلاً ۱۵٪ داده).
مثالهای عملی پیشپردازش داده در پایتون
در این بخش به چند مثال کد کوتاه پایتون برای نشان دادن مفاهیم فوق میپردازیم.
مثال ۱: پاکسازی و نرمالسازی دادههای عددی با Pandas و Scikit-Learn
import pandas as pd
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import MinMaxScaler
# بارگذاری داده فرضی
df = pd.DataFrame({
'age': [25, 30, None, 45, 22],
'salary': [50000, None, 60000, 80000, 45000]
})
# 1. جایگزینی مقادیر گمشده با میانگین
imputer = SimpleImputer(strategy='mean')
df[['age', 'salary']] = imputer.fit_transform(df[['age', 'salary']])
# 2. نرمالسازی به بازه [0,1]
scaler = MinMaxScaler()
df[['age', 'salary']] = scaler.fit_transform(df[['age', 'salary']])
print(df)
در این مثال، ابتدا Missing Valueها را با میانگین ستونها جایگزین میکنیم و سپس همه مقادیر عددی را به بازه [0,1] میبریم تا مقیاس ویژگیها یکسان شود.
مثال ۲: کدگذاری (Encoding) دادههای طبقهای
import pandas as pd
from sklearn.preprocessing import OneHotEncoder
# دادههای طبقهای فرضی
df = pd.DataFrame({
'color': ['red', 'blue', 'green', 'blue', 'red'],
'brand': ['Toyota', 'BMW', 'Toyota', 'Mercedes', 'BMW']
})
# One-Hot Encoding
encoder = OneHotEncoder(sparse=False, drop='first')
encoded = encoder.fit_transform(df[['color', 'brand']])
encoded_df = pd.DataFrame(encoded, columns=encoder.get_feature_names_out(['color', 'brand']))
# ترکیب با داده اصلی برای نمایش
result_df = pd.concat([df, encoded_df], axis=1)
print(result_df)
این کد با استفاده از One-Hot Encoding ستونهای «color» و «brand» را به فرمت صفر و یک تبدیل میکند و اولین دسته (به کمک drop='first') حذف میشود تا از تلهی چندهمخطی (Multicollinearity) جلوگیری شود.
مثال ۳: استخراج ویژگی از داده متنی با TF-IDF
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
# مجموعه متنی فرضی
texts = [
"این یک متن نمونه برای پردازش زبان طبیعی است.",
"در این مثال، میخواهیم از TF-IDF استفاده کنیم.",
"پیشپردازش دادههای متنی برای مدلهای یادگیری ماشین ضروری است."
]
# ایجاد TF-IDF Vectorizer
vectorizer = TfidfVectorizer(stop_words=['این', 'برای', 'است', 'میخواهیم'])
tfidf_matrix = vectorizer.fit_transform(texts)
# تبدیل به DataFrame برای نمایش
tfidf_df = pd.DataFrame(tfidf_matrix.toarray(), columns=vectorizer.get_feature_names_out())
print(tfidf_df)
در این مثال، ابتدا واژههای توقف (Stopwords) حذف میشوند و سپس ماتریس TF-IDF تولید میشود. خروجی این ماتریس برای آموزش مدلهای سادهی طبقهبندی مانند Logistic Regression یا Naive Bayes قابل استفاده است.
مثال ۴: بارگذاری و پیشپردازش سادهی تصویر با Keras
from tensorflow.keras.preprocessing import image
from tensorflow.keras.applications.resnet50 import preprocess_input
import numpy as np
# بارگذاری تصویر و تغییر اندازه به 224x224
img = image.load_img('cat.jpg', target_size=(224, 224))
x = image.img_to_array(img)
# افزودن بعد Batch
x = np.expand_dims(x, axis=0)
# نرمالسازی (پیشپردازش مخصوص ResNet50)
x = preprocess_input(x)
print("Shape:", x.shape) # خروجی باید (1, 224, 224, 3) باشد
در این مثال از تابع preprocess_input برای نرمالسازی تصویر بر اساس استاندارد مدل ResNet50 استفاده شده است. تصویر ابتدا به ابعاد 224×224 تغییر اندازه داده میشود و سپس بردار چهاربعدی ساخته میشود.
جمعبندی و نتیجهگیری
در این مقاله با انواع مختلف داده در حوزه هوش مصنوعی آشنا شدیم و اینکه برای هر نوع داده (عددی، طبقهای، سری زمانی، متنی، تصویری و صوتی) چه ویژگیهایی وجود دارد و چگونه باید آنها را قبل از آموزش مدل آماده کرد. سپس به مراحل پیشپردازش داده از قبیل پاکسازی، تبدیل ویژگی، کدگذاری، استخراج ویژگی، کاهش ابعاد و تقسیمبندی داده پرداختیم. مثالهای عملی پایتون نشان داد که چگونه میتوان با استفاده از کتابخانههای رایج مانند Pandas، Scikit-Learn، TensorFlow و Keras مراحل مختلف پیشپردازش را در عمل پیادهسازی کرد.
پردازش صحیح دادهها پایهی هر پروژه هوش مصنوعی است و بدون انجام دقیق گامهای پیشپردازش، مدل حتی اگر پیچیده و قدرتمند باشد نیز کارایی لازم را نخواهد داشت. بنابراین توصیه میشود توسعهدهندگان مبتدی و متوسط، پیش از ورود به مدلسازی، وقت کافی برای درک و اجرای اصولی مراحل پیشپردازش اختصاص دهند.