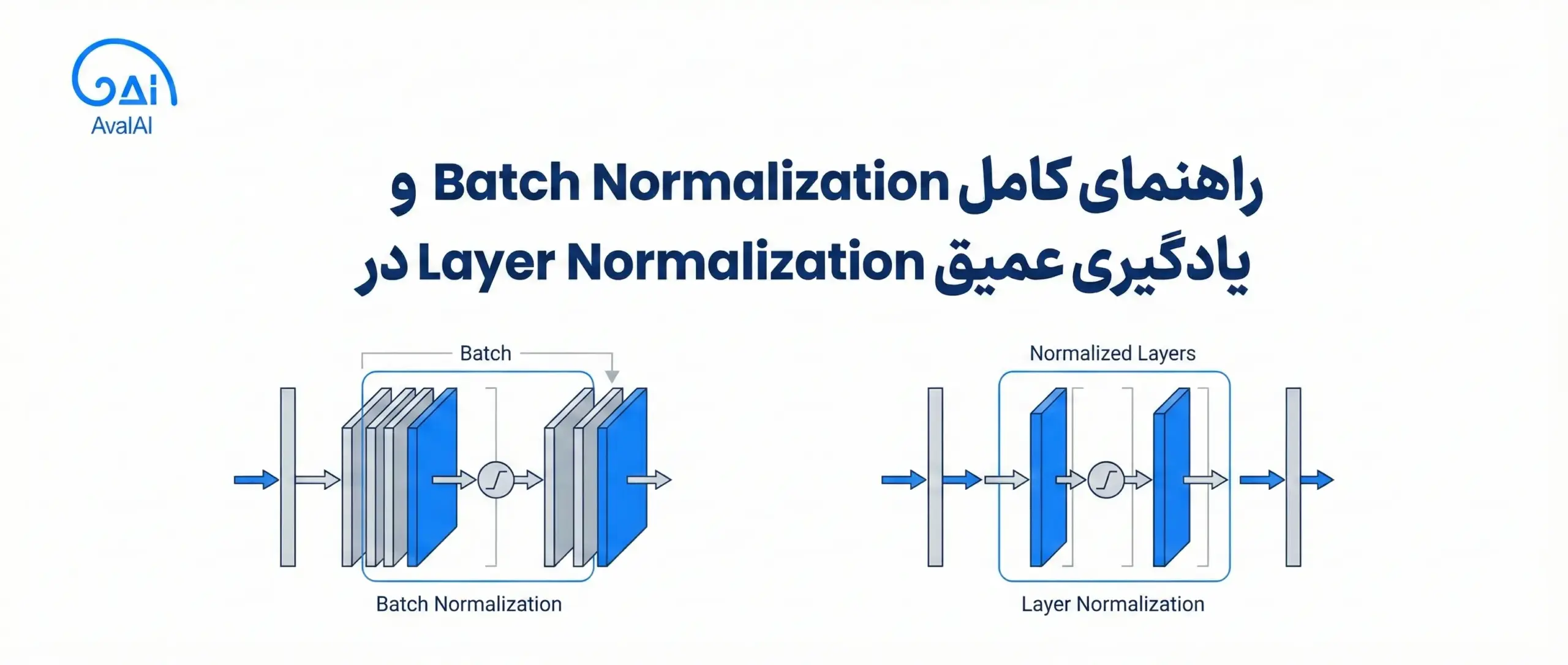
یکی از چالشهای اساسی در آموزش شبکههای عصبی عمیق، مدیریت توزیع دادهها در لایههای مختلف است. با افزایش عمق شبکه، مشکلاتی مانند محو شدن گرادیان و انفجار گرادیان آموزش را دشوار میکند. تکنیکهای نرمالسازی از جمله Batch Normalization و Layer Normalization برای حل این مشکلات طراحی شدهاند و امروزه به بخشی جداییناپذیر از معماریهای یادگیری عمیق تبدیل شدهاند.
در این مقاله به بررسی جامع این دو تکنیک، تفاوتهای آنها، کاربردها و نحوه پیادهسازی میپردازیم.
چرا نرمالسازی در شبکههای عصبی ضروری است؟
مشکل Internal Covariate Shift
زمانی که شبکه عصبی را آموزش میدهیم، توزیع ورودی هر لایه در طول فرآیند آموزش تغییر میکند. این پدیده که به آن Internal Covariate Shift گفته میشود، باعث کند شدن آموزش و نیاز به نرخ یادگیری کوچکتر میشود.
به عنوان مثال، فرض کنید در یک شبکه عصبی، خروجی لایه اول به عنوان ورودی لایه دوم استفاده میشود. با بهروزرسانی وزنهای لایه اول در هر مرحله آموزش، توزیع ورودی لایه دوم تغییر میکند. این تغییرات مداوم، فرایند یادگیری را پیچیدهتر و ناپایدارتر میکند.
مزایای نرمالسازی
نرمالسازی مزایای متعددی دارد:
- تسریع آموزش: امکان استفاده از نرخ یادگیری بالاتر بدون بیثباتی
- کاهش وابستگی به مقداردهی اولیه: حساسیت کمتر به مقادیر اولیه وزنها
- اثر منظمسازی: کاهش overfitting بدون نیاز به تکنیکهای اضافی
- بهبود جریان گرادیان: جلوگیری از محو یا انفجار گرادیان
Batch Normalization: مفاهیم و کاربردها
تاریخچه و معرفی
Batch Normalization در سال ۲۰۱۵ توسط سرگئی ایوفه و کریستین سگدی از شرکت گوگل معرفی شد. این تکنیک یکی از تأثیرگذارترین نوآوریها در یادگیری عمیق بوده است. در مقاله اصلی، نویسندگان نشان دادند که با استفاده از این روش میتوان همان دقت را با ۱۴ برابر کمتر مراحل آموزشی به دست آورد.
نحوه عملکرد Batch Normalization
Batch Normalization دادهها را در سطح mini-batch نرمال میکند. برای هر ویژگی به صورت مستقل، میانگین و واریانس محاسبه شده و سپس نرمالسازی انجام میشود.
فرمول ریاضی:
برای یک mini-batch با اندازه m:
μ = (1/m) Σ x_i // محاسبه میانگین
σ² = (1/m) Σ (x_i - μ)² // محاسبه واریانس
x̂ = (x - μ) / √(σ² + ε) // نرمالسازی
y = γx̂ + β // مقیاسگذاری و جابجایی
در این فرمول:
- ε یک مقدار کوچک برای پایداری عددی است
- γ (gamma) پارامتر مقیاسگذاری قابل آموزش
- β (beta) پارامتر جابجایی قابل آموزش
تفاوت Batch Normalization در آموزش و استنتاج
یکی از ویژگیهای کلیدی Batch Normalization، تفاوت رفتار آن در زمان آموزش و زمان استنتاج است:
در زمان آموزش:
- میانگین و واریانس از mini-batch جاری محاسبه میشود
- از این آمارها برای نرمالسازی استفاده میشود
- Moving average میانگین و واریانس بهروز میشود
در زمان استنتاج:
- از moving average میانگین و واریانس محاسبه شده در طول آموزش استفاده میشود
- این رویکرد تضمین میکند که خروجی برای یک ورودی مشخص همیشه یکسان باشد
کاربردهای Batch Normalization
Batch Normalization در معماریهای مختلف کاربرد دارد:
شبکههای کانولوشنی (CNN):
- معمولاً بعد از لایههای کانولوشنی و قبل از تابع فعالسازی قرار میگیرد
- برای هر کانال به صورت مستقل نرمالسازی انجام میشود
- در معماریهایی مانند ResNet و Inception استفاده گسترده دارد
شبکههای کاملاً متصل:
- بعد از لایههای Dense قرار میگیرد
- بهبود قابل توجهی در سرعت همگرایی ایجاد میکند
محدودیتهای Batch Normalization
با وجود مزایای فراوان، این تکنیک محدودیتهایی دارد:
وابستگی به اندازه Batch:
- برای batchهای کوچک کارایی کاهش مییابد
- برای کاربردهایی مانند تشخیص اشیاء با تصاویر با رزولوشن بالا مشکلساز است
- نیاز به حافظه بیشتر برای batchهای بزرگتر
ناسازگاری با RNN:
- محاسبه آمار برای توالیها پیچیده است
- هر گام زمانی نیاز به پارامترهای جداگانه دارد
تفاوت در آموزش و استنتاج:
- پیچیدگی اضافی در مدیریت moving statistics
- ممکن است در محیطهای تولید مشکل ایجاد کند
Layer Normalization: جایگزین قدرتمند
معرفی و انگیزه
Layer Normalization در سال ۲۰۱۶ توسط جیمی لی با، جیمی رایان کیروس و جفری هینتون معرفی شد. این تکنیک برای حل محدودیتهای Batch Normalization، به ویژه در مدلهای بازگشتی و ترنسفورمرها طراحی شده است.
نحوه عملکرد Layer Normalization
برخلاف Batch Normalization که در سطح batch نرمالسازی میکند، Layer Normalization در سطح هر نمونه و در تمام ویژگیها نرمالسازی انجام میدهد.
فرمول ریاضی:
برای هر نمونه x_i با K ویژگی:
μ_i = (1/K) Σ x_{i,k} // میانگین روی تمام ویژگیها
σ²_i = (1/K) Σ (x_{i,k} - μ_i)² // واریانس روی تمام ویژگیها
x̂_{i,k} = (x_{i,k} - μ_i) / √(σ²_i + ε)
y_{i,k} = γx̂_{i,k} + β
مزایای Layer Normalization
استقلال از اندازه Batch:
- برای batchهای کوچک نیز عملکرد خوبی دارد
- مناسب برای آموزش با محدودیت حافظه
سازگاری با دادههای توالی:
- برای RNN، LSTM و GRU ایدهآل است
- در هر گام زمانی به صورت مستقل نرمالسازی میکند
یکسان بودن آموزش و استنتاج:
- نیازی به نگهداری moving statistics نیست
- پیادهسازی سادهتر و سریعتر
کاربردهای Layer Normalization
معماریهای ترنسفورمر:
- در مدلهای زبانی مانند BERT، GPT-2 و GPT-3 استفاده میشود
- بعد از لایههای self-attention و feed-forward قرار میگیرد
- نقش حیاتی در پایداری آموزش مدلهای بزرگ دارد
شبکههای بازگشتی:
- برای LSTM و GRU جریان گرادیان را بهبود میبخشد
- مشکل vanishing gradient را کاهش میدهد
مدلهای بینایی:
- در Vision Transformers (ViT) کاربرد دارد
- جایگزین مناسب برای Batch Normalization در برخی معماریها
مقایسه جامع: Batch Normalization در مقابل Layer Normalization
تفاوتهای کلیدی
| ویژگی | Batch Normalization | Layer Normalization |
|---|---|---|
| محور نرمالسازی | روی تمام نمونههای batch | روی تمام ویژگیهای یک نمونه |
| وابستگی به batch | بله، نیاز به batch بزرگ | خیر، مستقل از اندازه batch |
| کاربرد اصلی | CNN و شبکههای کاملاً متصل | RNN، LSTM، ترنسفورمرها |
| آموزش vs استنتاج | متفاوت (moving statistics) | یکسان |
| پیچیدگی محاسباتی | متوسط | کم |
| حافظه مورد نیاز | بیشتر (برای batch بزرگ) | کمتر |
چه زمانی از کدام استفاده کنیم؟
استفاده از Batch Normalization:
- شبکههای کانولوشنی برای بینایی ماشین
- وقتی batch size بزرگ در دسترس است
- برای طبقهبندی تصویر و تشخیص الگو
- معماریهای ResNet، VGG، Inception
استفاده از Layer Normalization:
- مدلهای پردازش زبان طبیعی
- معماریهای ترنسفورمر (BERT، GPT)
- شبکههای بازگشتی (RNN، LSTM، GRU)
- batch size کوچک یا متغیر
- مدلهای تولید متن و ترجمه ماشینی
پیادهسازی عملی
Batch Normalization در TensorFlow/Keras
import tensorflow as tf
from tensorflow import keras
model = keras.Sequential([
keras.layers.Dense(128, input_shape=(784,)),
keras.layers.BatchNormalization(),
keras.layers.Activation('relu'),
keras.layers.Dense(64),
keras.layers.BatchNormalization(),
keras.layers.Activation('relu'),
keras.layers.Dense(10, activation='softmax')
])
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
Layer Normalization در PyTorch
import torch
import torch.nn as nn
class ModelWithLayerNorm(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.ln1 = nn.LayerNorm(hidden_size)
self.fc2 = nn.Linear(hidden_size, output_size)
self.ln2 = nn.LayerNorm(output_size)
def forward(self, x):
x = self.fc1(x)
x = self.ln1(x)
x = torch.relu(x)
x = self.fc2(x)
x = self.ln2(x)
return x
نکات عملی برای استفاده بهینه
تنظیمات Batch Normalization:
- momentum معمولاً بین ۰.۹ تا ۰.۹۹ تنظیم میشود
- epsilon را معمولاً ۱e-5 یا ۱e-3 قرار میدهند
- میتوان scale و center را غیرفعال کرد اگر لایه بعدی خطی باشد
تنظیمات Layer Normalization:
- epsilon معمولاً ۱e-6 یا ۱e-12 است
- پارامترهای gamma و beta را با ۱ و ۰ مقداردهی کنید
- در ترنسفورمرها معمولاً قبل از self-attention استفاده میشود (Pre-LN)
تأثیر بر عملکرد و دقت مدل
نتایج تجربی از تحقیقات
بر اساس مقاله اصلی Batch Normalization، این تکنیک توانست:
- دقت مشابه را با ۱۴ برابر کمتر مراحل آموزشی به دست آورد
- خطای top-5 در ImageNet را به ۴.۸۲٪ کاهش داد که از دقت انسان نیز فراتر رفت
- امکان استفاده از نرخ یادگیری بالاتر بدون مشکل را فراهم کرد
بهبود سرعت آموزش
استفاده از تکنیکهای نرمالسازی میتواند:
- سرعت همگرایی را ۲ تا ۵ برابر افزایش دهد
- نیاز به تنظیم دقیق hyperparameter را کاهش دهد
- امکان آموزش شبکههای عمیقتر را فراهم کند
جدیدترین پیشرفتها و روندهای آینده
تکنیکهای نوین نرمالسازی
RMSNorm (Root Mean Square Normalization):
- نسخه سادهشده Layer Normalization
- در مدلهای بزرگ مانند LLaMA استفاده میشود
- محاسبات کمتری نیاز دارد
Group Normalization:
- ترکیبی از Batch و Layer Normalization
- برای batchهای بسیار کوچک مناسب است
- در بینایی ماشین کاربرد دارد
Weight Normalization:
- به جای نرمالسازی activation، وزنها را نرمال میکند
- در برخی معماریها عملکرد بهتری دارد
تحقیقات جاری
محققان در حال بررسی این موضوعات هستند:
- آیا میتوان مدلهای بدون نرمالسازی آموزش داد؟
- بهینهسازی محل قرارگیری لایههای نرمالسازی
- ترکیب تکنیکهای مختلف نرمالسازی
- کاهش هزینه محاسباتی نرمالسازی در مدلهای بزرگ
نتیجهگیری و توصیهها
Batch Normalization و Layer Normalization دو ابزار قدرتمند برای بهبود آموزش شبکههای عصبی عمیق هستند. انتخاب بین این دو به معماری مدل، نوع داده و منابع محاسباتی در دسترس بستگی دارد.
نکات کلیدی برای تصمیمگیری:
- برای بینایی ماشین: Batch Normalization معمولاً گزینه اول است
- برای NLP و ترنسفورمرها: Layer Normalization استاندارد صنعت است
- محدودیت حافظه: Layer Normalization کارآمدتر است
- نیاز به استنتاج سریع: Layer Normalization سادهتر است
پیشنهادات عملی:
- همیشه با تکنیکهای استاندارد شروع کنید
- عملکرد را با و بدون نرمالسازی مقایسه کنید
- به hyperparameterهای مناسب توجه کنید
- از منابع معتبر و مستندات رسمی استفاده کنید
با درک صحیح این تکنیکها، میتوانید مدلهای یادگیری عمیق قویتر، سریعتر و دقیقتری بسازید که در حل مسائل پیچیده دنیای واقعی موفقتر عمل کنند.