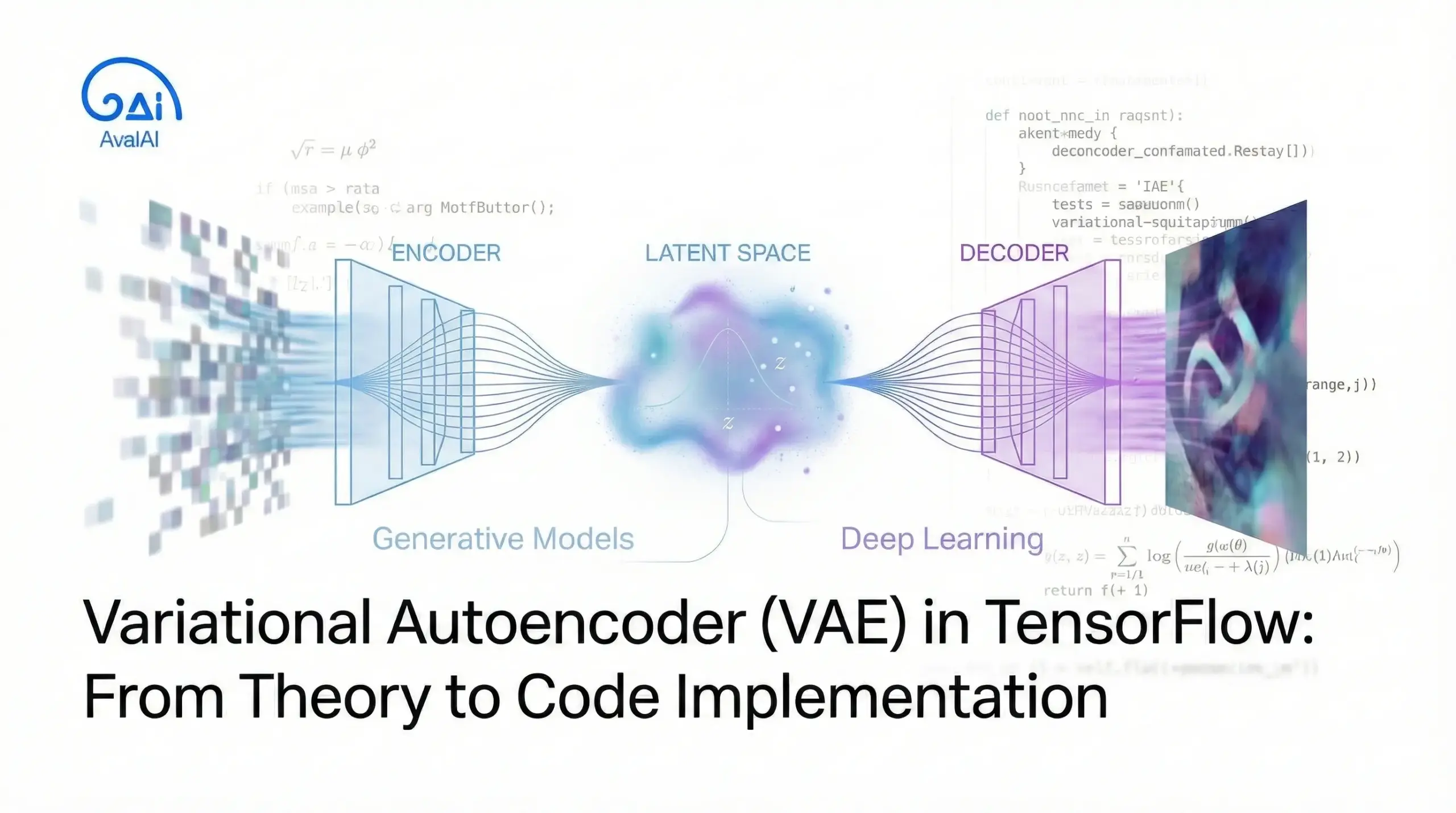
در مبحث یادگیری عمیق و مدلهای مولد، Variational Autoencoder یا VAE یکی از معماریهای برجسته و تاثیرگذار است که توانسته جایگاه ویژهای در میان محققان و توسعهدهندگان پیدا کند. این مدل که در سال ۲۰۱۳ توسط دیدریک کینگما و مکس ولینگ معرفی شد، ترکیبی هوشمندانه از استنتاج بیزی و شبکههای عصبی عمیق را ارائه میدهد.
Variational Autoencoder نه تنها قادر به فشردهسازی دادهها است، بلکه میتواند نمونههای جدید و واقعگرایانه تولید کند. در این مقاله، به صورت جامع و گام به گام به پیادهسازی VAE در فریمورک TensorFlow خواهیم پرداخت.
مبانی نظری Variational Autoencoder
تفاوت VAE با Autoencoder معمولی
قبل از ورود به جزئیات پیادهسازی، درک تفاوتهای بنیادین بین VAE و Autoencoder سنتی ضروری است. Autoencoder معمولی شامل دو بخش اصلی است: رمزنگار (Encoder) که داده ورودی را به یک بردار نهان فشرده تبدیل میکند، و رمزگشا (Decoder) که این بردار را به فضای اصلی بازمیگرداند.
VAE در مقابل، به جای نگاشت قطعی دادهها به یک نقطه مشخص در فضای نهان، دادهها را به یک توزیع احتمالاتی نگاشت میکند.
معماری کلی VAE
معماری VAE شامل سه جزء اساسی است:
۱. رمزنگار (Encoder)
رمزنگار در VAE یک شبکه عصبی است که داده ورودی را دریافت و به پارامترهای یک توزیع احتمالاتی تبدیل میکند. به جای خروجی یک بردار نهان ثابت، رمزنگار دو بردار تولید میکند: میانگین (μ) و واریانس (σ²) یک توزیع گاوسی. این رویکرد به مدل اجازه میدهد تا عدم قطعیت موجود در دادهها را مدلسازی کند.
۲. فضای نهان (Latent Space)
فضای نهان در VAE یک فضای پیوسته و ساختاریافته است که نمایش فشردهای از دادههای ورودی را ذخیره میکند. برخلاف Autoencoder معمولی که فضای نهان آن ممکن است نواحی خالی یا ناپیوسته داشته باشد، فضای نهان VAE به گونهای طراحی شده که نمونهبرداری از هر نقطه آن منجر به تولید داده معنادار شود.
۳. رمزگشا (Decoder)
رمزگشا وظیفه بازسازی داده اصلی را از بردار نهان نمونهبرداری شده بر عهده دارد. این شبکه یک بردار تصادفی از فضای نهان دریافت کرده و داده اصلی را بازسازی میکند.
تابع زیان VAE: ترکیب دو هدف متفاوت
یکی از مهمترین بخشهای VAE، تابع زیان (Loss Function) آن است. این تابع از ترکیب دو جزء اصلی تشکیل شده:
۱. زیان بازسازی (Reconstruction Loss)
این جزء اولین بخش تابع زیان است و مسئول اندازهگیری میزان تفاوت بین داده ورودی و داده بازسازی شده توسط مدل است.
زیان بازسازی تضمین میکند که مدل قادر به بازسازی دقیق دادههای ورودی باشد و اطلاعات مهم را در فرآیند رمزنگاری حفظ کند.
۲. زیان KL Divergence
KL Divergence یا واگرایی کولبک-لایبلر، جزء دوم و بسیار مهم تابع زیان است. این مقدار فاصله بین توزیع یادگرفته شده توسط رمزنگار و توزیع پیشین (معمولاً توزیع گاوسی استاندارد) را اندازهگیری میکند.
فرمول ریاضی KL Divergence برای توزیع گاوسی به صورت زیر است:
KL Loss = -0.5 × Σ(1 + log(σ²) - μ² - σ²)
این جزء نقش تنظیمکننده را ایفا میکند و باعث میشود فضای نهان منظم و پیوسته باشد. بدون این جزء، VAE به یک Autoencoder معمولی تبدیل میشود.
تابع زیان نهایی
Total Loss = Reconstruction Loss + KL Divergence
توازن بین این دو جزء بسیار حیاتی است. اگر وزن بازسازی زیاد باشد، مدل تصاویر با کیفیت بالاتر تولید میکند اما فضای نهان کمتر منظم خواهد بود. در مقابل، اگر وزن KL زیاد باشد، فضای نهان بسیار منظم اما بازسازی ضعیفتر خواهد بود.
ترفند بازپارامترسازی (Reparameterization Trick)
یکی از چالشهای اصلی در آموزش VAE، نمونهبرداری تصادفی از توزیع نهان است. عملیات نمونهبرداری به طور مستقیم قابل مشتقگیری نیست، که این مسئله مانع از استفاده از الگوریتم پسانتشار میشود.
ترفند بازپارامترسازی راهحلی هوشمندانه برای این مشکل ارائه میدهد. به جای نمونهبرداری مستقیم از N(μ, σ²)، ما به صورت زیر عمل میکنیم:
ε ~ N(0, 1)
z = μ + σ × ε
در اینجا، ε یک متغیر تصادفی از توزیع گاوسی استاندارد است که مستقل از پارامترهای مدل است. با این کار، z به یک تابع قطعی از μ و σ تبدیل میشود، در حالی که عنصر تصادفی از طریق ε حفظ میشود. این امر امکان محاسبه گرادیان نسبت به μ و σ را فراهم میکند.
پیادهسازی عملی در TensorFlow
حال که مبانی نظری را فراگرفتیم، به پیادهسازی عملی VAE در TensorFlow میپردازیم. در این بخش، یک VAE کامل برای مجموعه داده MNIST ایجاد خواهیم کرد.
نصب کتابخانههای مورد نیاز
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import numpy as np
import matplotlib.pyplot as plt
ایجاد لایه نمونهبرداری (Sampling Layer)
اولین قدم، پیادهسازی لایه نمونهبرداری با استفاده از ترفند بازپارامترسازی است:
class Sampling(layers.Layer):
"""لایه نمونهبرداری برای VAE با استفاده از ترفند بازپارامترسازی"""
def call(self, inputs):
z_mean, z_log_var = inputs
batch = tf.shape(z_mean)[0]
dim = tf.shape(z_mean)[1]
epsilon = tf.random.normal(shape=(batch, dim))
return z_mean + tf.exp(0.5 * z_log_var) * epsilon
ساخت رمزنگار
رمزنگار شامل لایههای کانولوشن است که داده ورودی را به پارامترهای توزیع نهان تبدیل میکند:
def build_encoder(latent_dim=2):
encoder_inputs = keras.Input(shape=(28, 28, 1))
x = layers.Conv2D(32, 3, activation="relu", strides=2, padding="same")(encoder_inputs)
x = layers.Conv2D(64, 3, activation="relu", strides=2, padding="same")(x)
x = layers.Flatten()(x)
x = layers.Dense(16, activation="relu")(x)
z_mean = layers.Dense(latent_dim, name="z_mean")(x)
z_log_var = layers.Dense(latent_dim, name="z_log_var")(x)
z = Sampling()([z_mean, z_log_var])
encoder = keras.Model(encoder_inputs, [z_mean, z_log_var, z], name="encoder")
return encoder
ساخت رمزگشا
رمزگشا از بردار نهان شروع کرده و تصویر را بازسازی میکند:
def build_decoder(latent_dim=2):
latent_inputs = keras.Input(shape=(latent_dim,))
x = layers.Dense(7 * 7 * 64, activation="relu")(latent_inputs)
x = layers.Reshape((7, 7, 64))(x)
x = layers.Conv2DTranspose(64, 3, activation="relu", strides=2, padding="same")(x)
x = layers.Conv2DTranspose(32, 3, activation="relu", strides=2, padding="same")(x)
decoder_outputs = layers.Conv2DTranspose(1, 3, activation="sigmoid", padding="same")(x)
decoder = keras.Model(latent_inputs, decoder_outputs, name="decoder")
return decoder
ایجاد کلاس VAE
حال باید یک کلاس سفارشی برای VAE ایجاد کنیم که تابع زیان و فرآیند آموزش را مدیریت کند:
class VAE(keras.Model):
def __init__(self, encoder, decoder, **kwargs):
super().__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
self.total_loss_tracker = keras.metrics.Mean(name="total_loss")
self.reconstruction_loss_tracker = keras.metrics.Mean(name="reconstruction_loss")
self.kl_loss_tracker = keras.metrics.Mean(name="kl_loss")
@property
def metrics(self):
return [
self.total_loss_tracker,
self.reconstruction_loss_tracker,
self.kl_loss_tracker,
]
def train_step(self, data):
with tf.GradientTape() as tape:
z_mean, z_log_var, z = self.encoder(data)
reconstruction = self.decoder(z)
# محاسبه زیان بازسازی
reconstruction_loss = tf.reduce_mean(
tf.reduce_sum(
keras.losses.binary_crossentropy(data, reconstruction),
axis=(1, 2)
)
)
# محاسبه KL divergence
kl_loss = -0.5 * (1 + z_log_var - tf.square(z_mean) - tf.exp(z_log_var))
kl_loss = tf.reduce_mean(tf.reduce_sum(kl_loss, axis=1))
# زیان کل
total_loss = reconstruction_loss + kl_loss
# بهروزرسانی وزنها
grads = tape.gradient(total_loss, self.trainable_weights)
self.optimizer.apply_gradients(zip(grads, self.trainable_weights))
# بهروزرسانی متریکها
self.total_loss_tracker.update_state(total_loss)
self.reconstruction_loss_tracker.update_state(reconstruction_loss)
self.kl_loss_tracker.update_state(kl_loss)
return {
"loss": self.total_loss_tracker.result(),
"reconstruction_loss": self.reconstruction_loss_tracker.result(),
"kl_loss": self.kl_loss_tracker.result(),
}
آموزش مدل
برای آموزش مدل، ابتدا باید دادهها را آماده کنیم:
# بارگذاری مجموعه داده MNIST
(x_train, _), (x_test, _) = keras.datasets.mnist.load_data()
# نرمالسازی دادهها
x_train = np.expand_dims(x_train, -1).astype("float32") / 255
x_test = np.expand_dims(x_test, -1).astype("float32") / 255
# ساخت مدل
latent_dim = 2
encoder = build_encoder(latent_dim)
decoder = build_decoder(latent_dim)
vae = VAE(encoder, decoder)
# کامپایل و آموزش
vae.compile(optimizer=keras.optimizers.Adam())
vae.fit(x_train, epochs=30, batch_size=128)
تولید نمونههای جدید
یکی از کاربردهای جذاب VAE، تولید نمونههای جدید است:
def generate_and_plot_images(vae, n=15, figsize=15):
"""تولید و نمایش تصاویر جدید از فضای نهان"""
digit_size = 28
scale = 1.0
figure = np.zeros((digit_size * n, digit_size * n))
grid_x = np.linspace(-scale, scale, n)
grid_y = np.linspace(-scale, scale, n)[::-1]
for i, yi in enumerate(grid_y):
for j, xi in enumerate(grid_x):
z_sample = np.array([[xi, yi]])
x_decoded = vae.decoder.predict(z_sample, verbose=0)
digit = x_decoded[0].reshape(digit_size, digit_size)
figure[
i * digit_size: (i + 1) * digit_size,
j * digit_size: (j + 1) * digit_size,
] = digit
plt.figure(figsize=(figsize, figsize))
plt.imshow(figure, cmap="Greys_r")
plt.axis('off')
plt.show()
generate_and_plot_images(vae)
بهینهسازی و نکات عملی
تنظیم ابعاد فضای نهان
انتخاب بعد مناسب برای فضای نهان بسیار مهم است. بعد کوچکتر منجر به فشردهسازی بیشتر اما ممکن است اطلاعات مهم را از دست بدهد. معمولاً برای تصاویر MNIST، ابعاد بین ۲ تا ۱۶ مناسب است.
استفاده از Beta-VAE
یک تکنیک رایج برای بهبود کیفیت، استفاده از ضریب β برای وزندهی KL divergence است:
total_loss = reconstruction_loss + beta * kl_loss
مقادیر بزرگتر β منجر به فضای نهان منظمتر اما کیفیت بازسازی کمتر میشود.
اجتناب از Batch Normalization
در آموزش Variational Autoencoder، معمولاً از Batch Normalization اجتناب میشود، زیرا تصادفی بودن اضافی ناشی از mini-batch ممکن است باعث ناپایداری در آموزش شود.
کاربردهای عملی VAE
۱. تولید تصویر
VAE میتواند برای تولید تصاویر جدید و واقعگرایانه استفاده شود. با نمونهبرداری از فضای نهان و عبور از رمزگشا، میتوان تصاویر متنوع تولید کرد.
۲. تشخیص ناهنجاری (Anomaly Detection)
یکی از کاربردهای مهم VAE، تشخیص ناهنجاری است. مدل روی دادههای نرمال آموزش داده میشود و سپس دادههایی که خطای بازسازی بالایی دارند، به عنوان ناهنجاری شناسایی میشوند. این روش در صنعت برای کنترل کیفیت، تشخیص خطا در ماشینها و امنیت سایبری کاربرد دارد.
۳. کاهش بعد و تجسم داده
VAE ابزار قدرتمندی برای کاهش بعد دادهها و تجسم آنها در فضای دو یا سه بعدی است.
۴. درونیابی (Interpolation)
به دلیل پیوستگی فضای نهان، میتوان بین دو نمونه در فضای نهان درونیابی انجام داد و تبدیل تدریجی یک تصویر به تصویر دیگر را مشاهده کرد.
چالشها و محدودیتها
۱. تصاویر تار
یکی از مشکلات معروف VAE تولید تصاویر نسبتاً تار است. این به دلیل استفاده از MSE در تابع زیان بازسازی است که تمایل به میانگینگیری دارد.
۲. پیچیدگی آموزش
VAE نسبت به Autoencoder معمولی پیچیدهتر است و نیاز به تنظیم دقیقتر هایپرپارامترها دارد.
۳. توازن زیان
یافتن توازن مناسب بین زیان بازسازی و KL divergence چالشبرانگیز است و نیاز به آزمایشهای متعدد دارد.
مقایسه با معماریهای دیگر
VAE در برابر GAN
در حالی که GAN ها معمولاً تصاویر با کیفیت بالاتری تولید میکنند، Variational Autoencoder دارای فضای نهان ساختاریافتهتر و آموزش پایدارتری است.
VAE در برابر Diffusion Models
مدلهای Diffusion اخیراً نتایج بهتری در تولید تصویر نشان دادهاند، اما VAE همچنان برای کاربردهایی که نیاز به فضای نهان قابل تفسیر دارند، مناسب است.
نتیجهگیری
Variational Autoencoder ابزاری قدرتمند و انعطافپذیر در حوزه یادگیری عمیق است که ترکیبی منحصر به فرد از استنتاج بیزی و شبکههای عصبی را ارائه میدهد. در این مقاله، به صورت جامع به مبانی نظری، پیادهسازی عملی در TensorFlow، و کاربردهای متنوع Variational Autoencoder پرداختیم.
پیادهسازی VAE در TensorFlow به دلیل API های کاربرپسند Keras و انعطافپذیری بالا، نسبتاً ساده است. با درک صحیح از مفاهیم بنیادین مانند ترفند بازپارامترسازی و تابع زیان ترکیبی، میتوان مدلهای VAE کارآمد و قدرتمند برای انواع مسائل طراحی کرد.
VAE همچنان یکی از معماریهای محبوب در پژوهشهای یادگیری عمیق است و توسعههای جدیدی مانند Beta-VAE، VQ-VAE و Conditional VAE نشاندهنده پتانسیل بالای این رویکرد هستند. با پیشرفت روزافزون سختافزار و الگوریتمها، انتظار میرود Variational Autoencoder و انواع بهبودیافته آن نقش مهمتری در آینده یادگیری ماشین ایفا کنند.