خوشهبندی یکی از تکنیکهای بنیادین در یادگیری ماشین و علم داده است که به دستهبندی دادهها در گروههای مشابه بدون نیاز به برچسبگذاری قبلی میپردازد. الگوریتم DBSCAN به عنوان یکی از پرکاربردترین روشهای خوشهبندی مبتنی بر چگالی، توانایی شناسایی خوشههای با اشکال پیچیده و نامنظم را دارد. این مقاله به بررسی جامع مبانی نظری، نحوه عملکرد، پارامترها، مزایا و معایب، کاربردهای عملی و پیادهسازی الگوریتم DBSCAN میپردازد. هدف این پژوهش، ارائه یک راهنمای کامل برای محققان و متخصصان علم داده جهت استفاده بهینه از این الگوریتم در تحلیل دادههای پیچیده است.
۱. مقدمه
۱.۱. زمینه و ضرورت تحقیق
در عصر کنونی، حجم عظیمی از دادهها در حوزههای مختلف از جمله پزشکی، مالی، شبکههای اجتماعی و سامانههای اطلاعات جغرافیایی تولید میشود. تحلیل و استخراج الگوهای معنادار از این دادهها بدون ابزارهای مناسب تقریباً غیرممکن است. خوشهبندی به عنوان یکی از تکنیکهای اصلی یادگیری نظارت نشده، نقش حیاتی در کشف ساختارهای پنهان دادهها ایفا میکند.
الگوریتمهای سنتی خوشهبندی مانند K-Means دارای محدودیتهایی هستند. این الگوریتمها معمولاً فرض میکنند که خوشهها شکل کروی یا محدب دارند و نمیتوانند دادههای نویزی را به درستی مدیریت کنند. در مواجهه با دادههای واقعی که اغلب دارای ساختارهای پیچیده، اشکال نامنظم و نویز قابل توجهی هستند، نیاز به روشهای پیشرفتهتری احساس میشود.
۱.۲. معرفی الگوریتم DBSCAN
الگوریتم DBSCAN مخفف عبارت “Density-Based Spatial Clustering of Applications with Noise” به معنای خوشهبندی فضایی مبتنی بر چگالی برای کاربردهای دارای نویز است. این الگوریتم در سال ۱۹۹۶ توسط تیم تحقیقاتی متشکل از مارتین استر (Martin Ester)، هانس-پتر کریگل (Hans-Peter Kriegel)، یورگ ساندر (Jörg Sander) و شیائووی شو (Xiaowei Xu) معرفی شد و به سرعت به یکی از پرکاربردترین الگوریتمهای خوشهبندی تبدیل گردید.
در سال ۲۰۱۴، این الگوریتم موفق به دریافت جایزه “Test of Time Award” در کنفرانس معتبر ACM SIGKDD شد که نشاندهنده اهمیت و تأثیرگذاری آن در جامعه علمی است. DBSCAN بر خلاف الگوریتمهای مبتنی بر تقسیمبندی، نیازی به تعیین تعداد خوشهها از قبل ندارد و قادر است خوشههایی با اشکال و اندازههای دلخواه را شناسایی کند.
۱.۳. اهداف مقاله
این مقاله با هدف ارائه یک راهنمای جامع و کاربردی برای درک و استفاده از الگوریتم DBSCAN تدوین شده است. اهداف اصلی عبارتند از:
- تشریح مبانی نظری و مفاهیم پایه الگوریتم DBSCAN
- توضیح نحوه عملکرد گام به گام الگوریتم
- بررسی پارامترها و روشهای تنظیم آنها
- تحلیل مزایا و محدودیتهای الگوریتم
- معرفی کاربردهای عملی در حوزههای مختلف
- ارائه راهنمای پیادهسازی عملی
۲. مبانی نظری خوشهبندی
۲.۱. تعریف خوشهبندی
خوشهبندی فرآیند تقسیم مجموعه دادهها به گروههای همگن است به نحوی که دادههای درون یک خوشه دارای حداکثر شباهت با یکدیگر و حداقل شباهت با دادههای خوشههای دیگر باشند. به عبارت دیگر، هدف از خوشهبندی قرار دادن نقاط داده در خوشههایی با حداکثر مشابهت درون خوشهای و حداقل مشابهت میان خوشهای است.
۲.۲. انواع الگوریتمهای خوشهبندی
الگوریتمهای خوشهبندی به چهار دسته اصلی تقسیم میشوند:
۱. الگوریتمهای مبتنی بر تقسیمبندی (Partitioning): مانند K-Means و K-Medoids که دادهها را به تعداد مشخصی خوشه تقسیم میکنند.
۲. الگوریتمهای سلسله مراتبی (Hierarchical): که ساختار درختی از خوشهها ایجاد میکنند و به دو نوع تجمعی و تقسیمی تقسیم میشوند.
۳. الگوریتمهای مبتنی بر چگالی (Density-based): مانند DBSCAN و OPTICS که خوشهها را بر اساس تراکم نقاط شناسایی میکنند.
۴. الگوریتمهای مبتنی بر شبکه (Grid-based): که فضای داده را به شبکهای از سلولها تقسیم میکنند.
۲.۳. مفهوم خوشهبندی مبتنی بر چگالی
در خوشهبندی مبتنی بر چگالی، خوشهها به عنوان نواحی متراکم از نقاط داده که توسط نواحی کمتراکم از یکدیگر جدا شدهاند، تعریف میشوند. این رویکرد مبتنی بر این ایده است که برای هر نقطه درون یک خوشه، همسایگی آن نقطه باید حاوی حداقل تعداد مشخصی از نقاط دیگر باشد. این ویژگی به الگوریتم اجازه میدهد خوشههایی با اشکال دلخواه و نامنظم را کشف کند.
۳. مفاهیم پایه الگوریتم DBSCAN
۳.۱. پارامترهای اصلی
الگوریتم DBSCAN بر اساس دو پارامتر اصلی عمل میکند:
۱. Epsilon (ε یا eps): شعاع همسایگی که حداکثر فاصله بین دو نقطه برای اینکه همسایه محسوب شوند را تعیین میکند. این پارامتر معیار نزدیکی بین نقاط را مشخص میکند.
۲. MinPts (حداقل نقاط): حداقل تعداد نقاطی که باید در همسایگی ε یک نقطه قرار داشته باشند تا آن نقطه به عنوان نقطه مرکزی در نظر گرفته شود. این پارامتر چگالی مورد نیاز برای تشکیل یک خوشه را مشخص میکند.
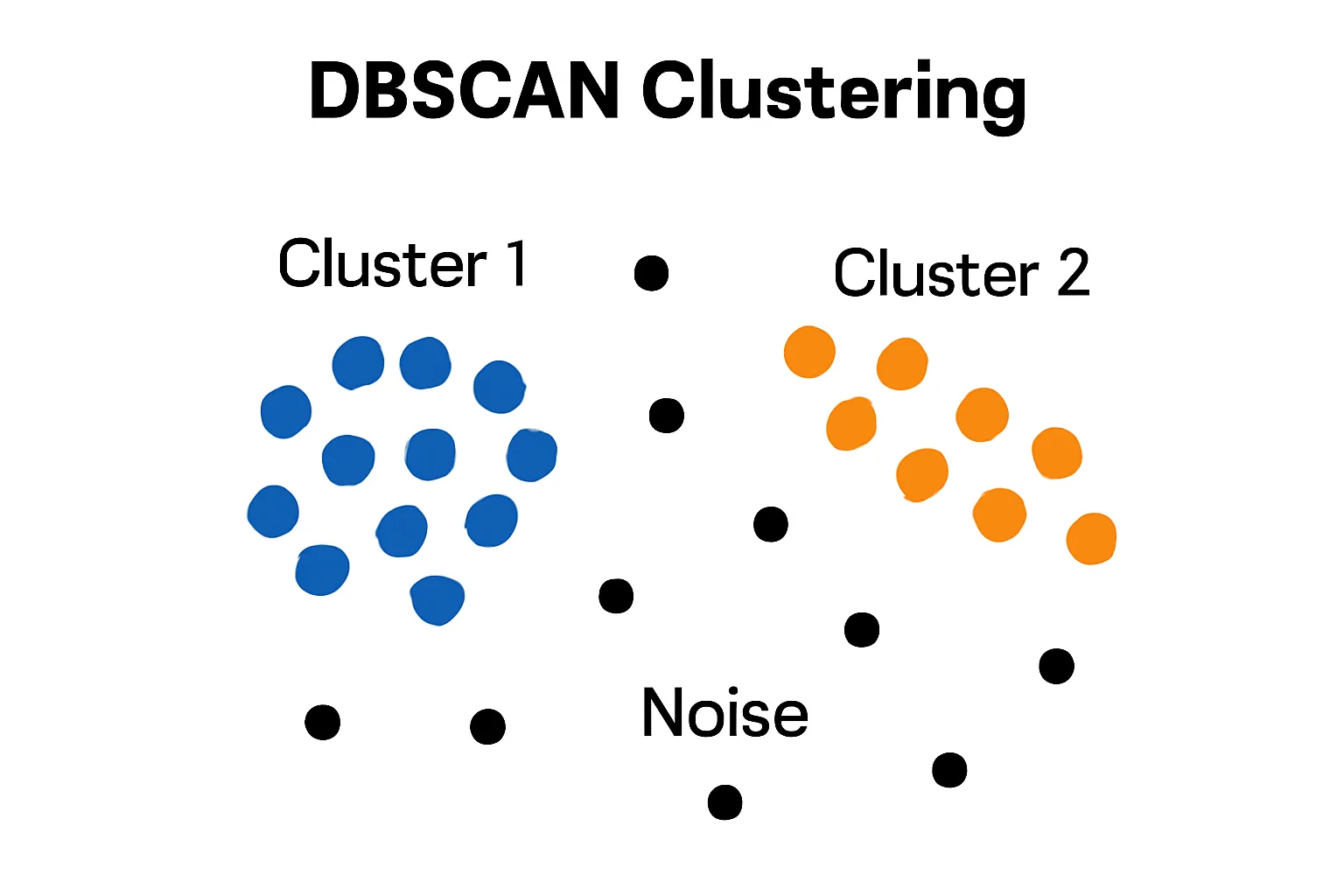
۳.۲. طبقهبندی نقاط
در الگوریتم DBSCAN، نقاط داده به سه دسته اصلی تقسیم میشوند:
۱. نقاط مرکزی (Core Points): نقطه p یک نقطه مرکزی است اگر حداقل MinPts نقطه (شامل خود p) در همسایگی ε آن قرار داشته باشند. این نقاط در مرکز نواحی پرتراکم قرار دارند و مبنای تشکیل خوشهها هستند.
۲. نقاط مرزی (Border Points): نقاطی که خودشان نقطه مرکزی نیستند اما در همسایگی ε یک نقطه مرکزی قرار دارند. این نقاط در حاشیه خوشهها واقع شدهاند.
۳. نقاط نویز (Noise Points یا Outliers): نقاطی که نه نقطه مرکزی هستند و نه در همسایگی هیچ نقطه مرکزی قرار دارند. این نقاط به هیچ خوشهای تعلق ندارند و به عنوان دادههای پرت شناسایی میشوند.
۳.۳. قابلیت دستیابی بر اساس چگالی
دو مفهوم مهم در DBSCAN عبارتند از:
دستیابی مستقیم (Direct Density-Reachability): نقطه q از نقطه p به طور مستقیم قابل دستیابی است اگر p یک نقطه مرکزی باشد و q در همسایگی ε آن قرار داشته باشد.
اتصال مبتنی بر چگالی (Density-Connectivity): دو نقطه p و q به هم متصل هستند اگر نقطه o وجود داشته باشد که هر دو نقطه p و q از o قابل دستیابی باشند. این مفهوم برای تعریف رسمی گستره خوشهها ضروری است و بر خلاف دستیابی، یک رابطه متقارن است.
۴. نحوه عملکرد الگوریتم DBSCAN
۴.۱. مراحل اجرای الگوریتم
الگوریتم DBSCAN به صورت زیر گام به گام عمل میکند:
گام ۱ – انتخاب نقطه اولیه: الگوریتم با انتخاب یک نقطه دلخواه که هنوز بازدید نشده است، آغاز میشود. انتخاب نقطه شروع تأثیر چندانی بر نتیجه نهایی ندارد.
گام ۲ – بازیابی همسایگان: همسایگی ε نقطه انتخاب شده استخراج میشود. این کار معمولاً با استفاده از تابع فاصله اقلیدسی انجام میگیرد.
گام ۳ – بررسی شرایط نقطه مرکزی: اگر تعداد نقاط در همسایگی ε بیشتر یا مساوی MinPts باشد، نقطه به عنوان نقطه مرکزی شناسایی شده و فرآیند تشکیل خوشه آغاز میشود. در غیر این صورت، نقطه موقتاً به عنوان نویز برچسبگذاری میشود.
گام ۴ – گسترش خوشه: برای هر نقطه مرکزی، تمام نقاط همسایه آن به خوشه اضافه میشوند. سپس برای هر یک از این نقاط همسایه که خودشان نیز نقطه مرکزی هستند، همین فرآیند به صورت بازگشتی تکرار میشود تا خوشه به طور کامل گسترش یابد.
گام ۵ – تکرار فرآیند: پس از اتمام گسترش یک خوشه، الگوریتم یک نقطه جدید بازدید نشده را انتخاب کرده و فرآیند را تکرار میکند تا همه نقاط بازدید شوند.
گام ۶ – نتیجه نهایی: در پایان، همه نقاط یا به خوشهای تعلق دارند یا به عنوان نویز شناسایی شدهاند. نقاطی که در ابتدا به عنوان نویز برچسبگذاری شده بودند، ممکن است در نهایت به عنوان نقاط مرزی به خوشهای اضافه شوند.
۴.۲. مثال عملی
فرض کنید مجموعه دادهای در فضای دو بعدی داریم و پارامترها را به صورت ε = ۱ و MinPts = ۳ تنظیم کردهایم:
۱. الگوریتم یک نقطه را انتخاب میکند و دایرهای با شعاع ۱ واحد حول آن رسم میکند. ۲. اگر حداقل ۳ نقطه (شامل خود نقطه) در این دایره باشند، نقطه به عنوان مرکزی شناسایی میشود. ۳. خوشه با اضافه کردن همسایگان نقطه مرکزی گسترش مییابد. ۴. این فرآیند تا زمانی که دیگر نقطه مرکزی جدیدی در همسایگی یافت نشود، ادامه مییابد. ۵. سپس الگوریتم به نقطه بعدی بازدید نشده میرود و فرآیند را تکرار میکند.
۴.۳. معیارهای فاصله
DBSCAN میتواند با هر تابع فاصلهای استفاده شود. رایجترین معیار، فاصله اقلیدسی است که برای فضاهای دو و سه بعدی مناسب است. برای دادههای جغرافیایی، فاصله Great Circle مناسبتر است. برای دادههای با ابعاد بالا، ممکن است معیارهای دیگری مانند فاصله منهتن یا کسینوسی کارایی بهتری داشته باشند.
۵. پیچیدگی محاسباتی
۵.۱. تحلیل پیچیدگی زمانی
پیچیدگی زمانی الگوریتم DBSCAN به روش پیادهسازی و ساختار دادههای استفاده شده بستگی دارد:
بهترین حالت: اگر از ساختارهای دادهای مناسب مانند R*-tree، Ball tree یا KD-tree برای شتابدهی به جستجوی همسایهها استفاده شود، پیچیدگی زمانی به O(n log n) میرسد که n تعداد نقاط داده است.
بدترین حالت: بدون استفاده از ساختارهای شاخصگذاری شده یا در دادههای با توزیع نامناسب، پیچیدگی به O(n²) افزایش مییابد.
حالت متوسط: برای اکثر کاربردهای عملی با پیادهسازی مناسب، پیچیدگی نزدیک به O(n log n) است که الگوریتم را برای مجموعه دادههای بزرگ مناسب میکند.
۵.۲. پیچیدگی حافظه
پیچیدگی حافظه اصلی الگوریتم برای ذخیره دادهها O(n) است. با این حال، استفاده از ساختارهای شاخصگذاری ممکن است حافظه اضافی به میزان O(n.d) نیاز داشته باشد که d میانگین تعداد همسایگان هر نقطه است.
۶. مزایای الگوریتم DBSCAN
۶.۱. عدم نیاز به تعیین تعداد خوشهها
یکی از مهمترین مزایای DBSCAN این است که بر خلاف الگوریتمهایی مانند K-Means، نیازی به تعیین تعداد خوشهها از قبل ندارد. الگوریتم به طور خودکار تعداد خوشهها را بر اساس چگالی دادهها و پارامترهای ε و MinPts تعیین میکند.
۶.۲. شناسایی خوشههای با اشکال دلخواه
DBSCAN میتواند خوشههای با اشکال نامنظم و پیچیده را شناسایی کند. این قابلیت به ویژه در دادههای واقعی که خوشهها الزاماً شکل کروی یا محدب ندارند، بسیار مفید است. حتی میتواند خوشهای را که کاملاً توسط خوشه دیگری احاطه شده اما به آن متصل نیست، شناسایی کند.
۶.۳. تشخیص و مدیریت نویز
الگوریتم DBSCAN قابلیت شناسایی و جداسازی نقاط نویزی یا دادههای پرت را دارد. این ویژگی برای کاربردهایی مانند تشخیص ناهنجاری و پاکسازی داده بسیار ارزشمند است. نقاط نویزی به هیچ خوشهای تعلق داده نمیشوند و میتوانند به عنوان موارد غیرعادی مورد توجه قرار گیرند.
۶.۴. استحکام در برابر ترتیب دادهها
DBSCAN تا حد زیادی نسبت به ترتیب پردازش نقاط حساس نیست. تنها نقاط مرزی که از بیش از یک خوشه قابل دستیابی هستند ممکن است بسته به ترتیب پردازش دادهها به خوشههای مختلف اختصاص یابند.
۶.۵. انعطاف در انتخاب معیار فاصله
الگوریتم میتواند با هر تابع فاصله یا شباهتی استفاده شود و این انعطافپذیری به کاربر اجازه میدهد مناسبترین معیار را برای نوع خاص دادههای خود انتخاب کند.
۶.۶. سرعت مناسب برای دادههای با ابعاد پایین
برای دادههای با ابعاد پایین و با استفاده از ساختارهای شاخصگذاری مناسب، DBSCAN سرعت قابل قبولی دارد و میتواند به صورت کارآمد اجرا شود.
۷. محدودیتها و معایب
۷.۱. حساسیت به پارامترها
یکی از اصلیترین چالشهای DBSCAN، تعیین مقادیر مناسب برای پارامترهای ε و MinPts است. انتخاب نادرست این پارامترها میتواند منجر به نتایج ضعیف شود. تعیین این پارامترها معمولاً نیازمند دانش قبلی از دادهها یا آزمون و خطا است.
۷.۲. مشکل در خوشههای با چگالی متفاوت
DBSCAN در شناسایی خوشههایی که چگالیهای بسیار متفاوتی دارند، دچار مشکل میشود. از آنجا که تنها یک جفت پارامتر ε و MinPts برای کل مجموعه داده استفاده میشود، نمیتوان این پارامترها را برای همه خوشهها به طور مناسب تنظیم کرد. برای حل این مشکل، الگوریتمهای پیشرفتهتری مانند HDBSCAN و OPTICS توسعه یافتهاند.
۷.۳. عملکرد ضعیف در ابعاد بالا
در دادههای با ابعاد بالا، مفهوم فاصله کمتر معنادار میشود (نفرین ابعاد). این پدیده میتواند کارایی DBSCAN را کاهش دهد و تعیین مقدار مناسب برای ε را دشوارتر کند.
۷.۴. عدم قطعیت کامل
DBSCAN برای نقاط مرزی که از چند خوشه قابل دستیابی هستند، کاملاً قطعی نیست. بسته به ترتیب پردازش دادهها، این نقاط ممکن است به خوشههای مختلف اختصاص یابند. با این حال، برای نقاط مرکزی و نقاط نویز، الگوریتم کاملاً قطعی است.
۷.۵. مشکل در خوشههای بسیار نزدیک
هنگامی که خوشهها بسیار نزدیک به یکدیگر هستند، ممکن است الگوریتم نتواند آنها را به درستی از هم تفکیک کند و به اشتباه آنها را به عنوان یک خوشه واحد شناسایی کند.
۷.۶. عدم توانایی پیشبینی
بر خلاف برخی الگوریتمهای خوشهبندی، DBSCAN پس از آموزش نمیتواند عضویت خوشهای نقاط جدید را پیشبینی کند. این محدودیت در کاربردهایی که نیاز به دستهبندی دادههای جدید دارند، میتواند مشکلساز باشد.
۸. تنظیم پارامترها
۸.۱. انتخاب پارامتر MinPts
یک قاعده سرانگشتی برای تعیین MinPts این است که آن را برابر یا بزرگتر از تعداد ابعاد داده به علاوه یک قرار دهیم: MinPts ≥ D + 1. برای اکثر کاربردها، مقدار حداقل ۳ توصیه میشود. مقدار پایینتر از ۳ معمولاً معنادار نیست زیرا در آن صورت تقریباً هر نقطهای میتواند نقطه مرکزی باشد.
برای مجموعه دادههای بزرگ یا پرنویز، مقادیر بالاتر (۵ تا ۱۰) معمولاً نتایج بهتری ارائه میدهند. هر چه MinPts بزرگتر باشد، خوشههای متراکمتری تشکیل میشوند و نقاط بیشتری به عنوان نویز شناسایی میشوند.
۸.۲. انتخاب پارامتر Epsilon (ε)
تعیین ε پیچیدهتر از MinPts است. یک روش رایج استفاده از نمودار k-distance است:
۱. برای هر نقطه، فاصله آن تا k-امین نزدیکترین همسایه محاسبه میشود (معمولاً k = MinPts). ۲. این فواصل به صورت نزولی مرتب شده و رسم میشوند. ۳. نقطهای در نمودار که در آن شیب تغییر ناگهانی دارد (نقطه زانویی یا elbow point) به عنوان مقدار مناسب برای ε انتخاب میشود.
این نقطه زانویی نشاندهنده آستانهای است که تفاوت بین نواحی متراکم و نواحی کمتراکم یا نویزی را مشخص میکند.
۸.۳. روشهای خودکار تنظیم پارامترها
برخی از روشهای پیشرفته برای تنظیم خودکار پارامترها عبارتند از:
روش Grid Search: آزمایش ترکیبات مختلف پارامترها و انتخاب بهترین ترکیب بر اساس معیارهای ارزیابی مانند Silhouette Score یا Davies-Bouldin Index.
استفاده از الگوریتمهای بهینهسازی: استفاده از الگوریتمهای فراابتکاری مانند الگوریتم ژنتیک یا بهینهسازی ازدحام ذرات برای یافتن بهترین ترکیب پارامترها.
تحلیل توزیع فاصلهها: بررسی توزیع فواصل بین نقاط و انتخاب پارامترها بر اساس ویژگیهای آماری این توزیع.
۸.۴. ملاحظات عملی
در عمل، توصیه میشود:
- ابتدا با MinPts = 4 یا 5 شروع کنید
- نمودار k-distance را رسم کنید و نقطه زانویی را شناسایی کنید
- چندین مقدار مختلف را آزمایش کنید و نتایج را با معیارهای ارزیابی مقایسه کنید
- تأثیر هر پارامتر را جداگانه بررسی کنید
- از دانش حوزهای خود درباره دادهها استفاده کنید
۹. کاربردهای عملی DBSCAN
۹.۱. تحلیل دادههای مکانی و GIS
یکی از کاربردهای اصلی DBSCAN در سامانههای اطلاعات جغرافیایی است. این الگوریتم برای شناسایی نواحی پرتراکم در شهرها، تحلیل الگوهای جرم و جنایت، خوشهبندی محل وقوع زلزلهها، و شناسایی کانونهای بیماریها کاربرد دارد. به عنوان مثال، در مدیریت شهری میتوان از DBSCAN برای شناسایی نقاط ترافیکی استفاده کرد.
۹.۲. تشخیص ناهنجاری و کلاهبرداری
در سیستمهای امنیتی و مالی، DBSCAN برای شناسایی رفتارهای غیرعادی مورد استفاده قرار میگیرد. نقاط نویزی شناسایی شده توسط الگوریتم میتوانند نشاندهنده تراکنشهای مشکوک، رفتارهای کاربری غیرعادی یا حملات سایبری باشند. در تشخیص کلاهبرداری کارت اعتباری، این الگوریتم میتواند تراکنشهای غیرعادی را شناسایی کند.
۹.۳. پردازش تصویر و بینایی ماشین
در پردازش تصویر، DBSCAN برای قطعهبندی تصویر، تشخیص اشیاء، و گروهبندی پیکسلهای مشابه استفاده میشود. در تحلیل تصاویر پزشکی، این الگوریتم میتواند برای شناسایی بافتهای آسیبدیده یا تومورها به کار رود. همچنین در سیستمهای تشخیص چهره و تحلیل ویدئو نیز کاربرد دارد.
۹.۴. تحلیل شبکههای اجتماعی
در تحلیل شبکههای اجتماعی، DBSCAN برای شناسایی جوامع و گروههای کاربری، تشخیص اخبار جعلی از طریق شناسایی الگوهای غیرعادی انتشار اطلاعات، و تحلیل ساختار شبکه استفاده میشود. این الگوریتم میتواند کاربران تأثیرگذار در هسته خوشهها را شناسایی کند.
۹.۵. زیستشناسی محاسباتی و پزشکی
در علوم زیستی، DBSCAN برای خوشهبندی توالیهای ژنتیکی، تحلیل دادههای میکروسکوپی، دستهبندی بیماریها بر اساس علائم بالینی، و تحلیل دادههای ژنومیک کاربرد دارد. در تشخیص سرطان، میتواند سلولهای غیرعادی را از سلولهای سالم جدا کند.
۹.۶. تحلیل سریهای زمانی
DBSCAN برای شناسایی الگوهای غیرعادی در سریهای زمانی، خوشهبندی دادههای سنسورها، و تشخیص رویدادهای نادر در دادههای لاگ سیستمها استفاده میشود. در نظارت بر تجهیزات صنعتی، میتواند نشانههای اولیه خرابی را تشخیص دهد.
۹.۷. یادگیری ماشین و پیشپردازش داده
DBSCAN در مرحله پیشپردازش برای حذف نویز، کاهش ابعاد، و استخراج ویژگیها استفاده میشود. همچنین میتواند برای انتخاب نمونههای آموزشی مناسب در یادگیری نیمهنظارت شده به کار رود.
۹.۸. اینترنت اشیا و دادههای سنسورها
در IoT، DBSCAN برای تحلیل و خوشهبندی دادههای بلادرنگ از سنسورها، تشخیص ناهنجاری در عملکرد دستگاهها، و بهینهسازی مصرف انرژی در شبکههای سنسوری استفاده میشود.
۱۰. الگوریتمهای مرتبط و پیشرفته
۱۰.۱. HDBSCAN
HDBSCAN مخفف Hierarchical DBSCAN است که یک نسخه پیشرفته و سلسلهمراتبی از DBSCAN محسوب میشود. این الگوریتم میتواند خوشههایی با چگالیهای مختلف را شناسایی کند و نیازی به تنظیم دقیق پارامتر ε ندارد. HDBSCAN یک درخت سلسلهمراتبی از خوشهها ایجاد میکند و بهترین خوشهها را بر اساس معیار پایداری انتخاب میکند.
۱۰.۲. OPTICS
الگوریتم OPTICS (Ordering Points To Identify the Clustering Structure) یک روش خوشهبندی مبتنی بر چگالی است که به جای تولید مستقیم خوشهها، یک ترتیب خاص از نقاط ایجاد میکند که ساختار خوشهبندی را نشان میدهد. OPTICS به ε خاصی محدود نیست و میتواند خوشههایی با چگالیهای متفاوت را شناسایی کند.
۱۰.۳. ST-DBSCAN
الگوریتم ST-DBSCAN برای دادههای فضایی-زمانی طراحی شده است. این الگوریتم هم بعد مکانی و هم بعد زمانی را در نظر میگیرد و برای تحلیل دادههایی که هم مکان و هم زمان برای آنها اهمیت دارد (مانند دادههای GPS یا شیوع بیماریها) مناسب است.
۱۰.۴. DENCLUE
DENCLUE از توابع چگالی برای خوشهبندی استفاده میکند و میتواند با دادههای پرنویز و چندبعدی به خوبی کار کند. این الگوریتم بر اساس تخمین تابع چگالی احتمال عمل میکند.
۱۱. پیادهسازی عملی
۱۱.۱. پیادهسازی با Python و Scikit-learn
کتابخانه Scikit-learn یکی از محبوبترین کتابخانههای یادگیری ماشین در پایتون است که پیادهسازی کاملی از DBSCAN را ارائه میدهد. نحوه استفاده از آن به شرح زیر است:
from sklearn.cluster import DBSCAN
import numpy as np
import matplotlib.pyplot as plt
# تولید داده نمونه
from sklearn.datasets import make_moons
X, _ = make_moons(n_samples=300, noise=0.05, random_state=42)
# ایجاد مدل DBSCAN
dbscan = DBSCAN(eps=0.3, min_samples=5)
# اجرای الگوریتم
labels = dbscan.fit_predict(X)
# تعداد خوشهها (بدون در نظر گرفتن نویز)
n_clusters = len(set(labels)) - (1 if -1 in labels else 0)
n_noise = list(labels).count(-1)
print(f'تعداد خوشهها: {n_clusters}')
print(f'تعداد نقاط نویز: {n_noise}')
# رسم نتایج
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis')
plt.title('نتیجه خوشهبندی DBSCAN')
plt.xlabel('ویژگی 1')
plt.ylabel('ویژگی 2')
plt.show()
۱۱.۲. پیادهسازی با R
در زبان R نیز کتابخانههای مختلفی برای اجرای DBSCAN وجود دارد:
library(dbscan)
# تولید داده نمونه
data <- data.frame(
x = rnorm(100),
y = rnorm(100)
)
# اجرای DBSCAN
result <- dbscan(data, eps = 0.5, minPts = 5)
# نمایش نتایج
print(result)
plot(data, col = result$cluster + 1, pch = 20)
۱۱.۳. بهینهسازی عملکرد
برای بهبود عملکرد DBSCAN در مجموعه دادههای بزرگ:
استفاده از الگوریتمهای جستجوی سریع همسایه: استفاده از KD-Tree، Ball Tree یا Annoy برای تسریع یافتن همسایگان.
پردازش موازی: تقسیم دادهها به بخشهای کوچکتر و پردازش موازی آنها.
نمونهبرداری: برای مجموعه دادههای بسیار بزرگ، استفاده از نمونهبرداری برای تخمین پارامترهای بهینه.
استفاده از GPU: پیادهسازیهای GPU-based برای دادههای بسیار بزرگ میتوانند سرعت را به طور قابل توجهی افزایش دهند.
۱۱.۴. ارزیابی نتایج
برای ارزیابی کیفیت خوشهبندی DBSCAN میتوان از معیارهای زیر استفاده کرد:
Silhouette Score: معیاری برای سنجش تفکیکپذیری خوشهها که مقادیر نزدیک به ۱ نشاندهنده خوشهبندی خوب است.
Davies-Bouldin Index: معیار کیفیت خوشهبندی که مقادیر پایینتر بهتر هستند.
Calinski-Harabasz Index: نسبت پراکندگی بین خوشهای به پراکندگی درون خوشهای که مقادیر بالاتر بهتر است.
بررسی بصری: رسم نتایج خوشهبندی و بررسی بصری کیفیت خوشهها به ویژه در دادههای دو و سه بعدی.
۱۲. مطالعات موردی
۱۲.۱. مطالعه موردی: تحلیل دادههای جغرافیایی شهری
در یک پروژه تحقیقاتی، DBSCAN برای تحلیل نقاط وقوع تصادفات رانندگی در یک کلانشهر استفاده شد. با تنظیم ε بر اساس فاصله متوسط بین تقاطعها و MinPts = 5، الگوریتم توانست نقاط حادثهخیز را شناسایی کند. نتایج نشان داد که خوشههای شناسایی شده با بزرگراهها و تقاطعهای پرترددد همخوانی دارند و میتوانند برای برنامهریزی ایمنی ترافیک مورد استفاده قرار گیرند.
۱۲.۲. مطالعه موردی: تشخیص کلاهبرداری در تراکنشهای مالی
یک موسسه مالی از DBSCAN برای شناسایی الگوهای غیرعادی در تراکنشهای کارت اعتباری استفاده کرد. با استفاده از ویژگیهایی مانند مبلغ تراکنش، مکان، زمان و فرکانس، الگوریتم توانست نقاط نویزی را شناسایی کند که بسیاری از آنها تراکنشهای کلاهبرداری بودند. این سیستم توانست نرخ تشخیص کلاهبرداری را ۳۵٪ افزایش دهد.
۱۲.۳. مطالعه موردی: خوشهبندی بیماران در تحقیقات پزشکی
در یک مطالعه پزشکی، DBSCAN برای دستهبندی بیماران دیابتی بر اساس پروفایل بالینی و آزمایشگاهی آنها استفاده شد. الگوریتم توانست زیرگروههای متمایزی از بیماران را شناسایی کند که هر کدام به درمانهای خاصی بهتر پاسخ میدادند. این اطلاعات به پزشکان کمک کرد تا درمانهای شخصیسازی شدهتری ارائه دهند.
۱۳. مقایسه با سایر الگوریتمها
۱۳.۱. مقایسه با K-Means
K-Means:
- نیاز به تعیین تعداد خوشهها دارد
- فقط خوشههای کروی را خوب شناسایی میکند
- سریعتر از DBSCAN است
- نسبت به نویز حساس است
- قطعی است
DBSCAN:
- تعداد خوشهها را خودکار تعیین میکند
- خوشههای با اشکال دلخواه را شناسایی میکند
- کندتر از K-Means است
- نویز را شناسایی و حذف میکند
- برای نقاط مرزی کاملاً قطعی نیست
۱۳.۲. مقایسه با Mean Shift
Mean Shift نیز یک الگوریتم مبتنی بر چگالی است اما بر خلاف DBSCAN، از تخمین چگالی کرنل استفاده میکند. Mean Shift معمولاً کندتر از DBSCAN است اما نیازی به تنظیم دقیق MinPts ندارد.
۱۳.۳. مقایسه با خوشهبندی سلسلهمراتبی
خوشهبندی سلسلهمراتبی یک درخت کامل از خوشهها ایجاد میکند در حالی که DBSCAN فقط یک سطح خوشهبندی ارائه میدهد. خوشهبندی سلسلهمراتبی معمولاً کندتر است اما اطلاعات بیشتری درباره ساختار دادهها ارائه میدهد.
۱۳.۴. جدول مقایسه
| ویژگی | DBSCAN | K-Means | Mean Shift | سلسلهمراتبی |
|---|---|---|---|---|
| نیاز به تعداد خوشه | خیر | بله | خیر | خیر |
| شکل خوشه | دلخواه | کروی | دلخواه | دلخواه |
| تشخیص نویز | بله | خیر | خیر | خیر |
| پیچیدگی زمانی | O(n log n) | O(n.k.i) | O(n²) | O(n²) |
| مناسب برای ابعاد بالا | خیر | نسبی | خیر | خیر |
۱۴. روندهای تحقیقاتی و توسعههای آینده
۱۴.۱. یادگیری عمیق و DBSCAN
ترکیب DBSCAN با شبکههای عصبی عمیق برای استخراج خودکار ویژگیها و خوشهبندی همزمان یکی از حوزههای فعال تحقیقاتی است. این رویکرد میتواند عملکرد را در دادههای پیچیده بهبود بخشد.
۱۴.۲. DBSCAN برای دادههای جریانی
توسعه نسخههای آنلاین و تطبیقی DBSCAN برای دادههای جریانی (streaming data) که به صورت بلادرنگ وارد سیستم میشوند، یک نیاز مهم در کاربردهای IoT و تحلیل شبکههای اجتماعی است.
۱۴.۳. بهینهسازی برای دادههای بزرگ
توسعه الگوریتمهای موازی و توزیع شده DBSCAN برای پردازش دادههای بزرگ در چارچوبهایی مانند Apache Spark و Hadoop در حال پیشرفت است.
۱۴.۴. خوشهبندی چندمنظوره
ترکیب DBSCAN با الگوریتمهای بهینهسازی چندمنظوره برای یافتن بهترین تنظیمات پارامتر که چندین معیار را همزمان بهینه میکنند، یک حوزه تحقیقاتی نوظهور است.
۱۴.۵. DBSCAN قابل تفسیر
توسعه روشهایی برای تفسیرپذیری نتایج DBSCAN و توضیح دلایل قرارگیری هر نقطه در یک خوشه خاص یا شناسایی آن به عنوان نویز، برای کاربردهای حساس مانند پزشکی و مالی اهمیت دارد.
۱۵. نتیجهگیری
الگوریتم DBSCAN یکی از قدرتمندترین و کاربردیترین روشهای خوشهبندی است که تواناییهای منحصر به فردی در شناسایی خوشههای با اشکال دلخواه و تشخیص نویز دارد. این الگوریتم با وجود محدودیتهایی مانند حساسیت به پارامترها و مشکل در خوشههای با چگالی متفاوت، همچنان یکی از گزینههای برتر برای تحلیل دادههای پیچیده محسوب میشود.
۱۵.۱. نکات کلیدی
- DBSCAN یک الگوریتم خوشهبندی مبتنی بر چگالی است که نیازی به تعیین تعداد خوشهها ندارد
- دو پارامتر اصلی eps و MinPts برای تعیین چگالی مورد نیاز خوشهها استفاده میشوند
- الگوریتم قادر به شناسایی خوشههای با اشکال نامنظم و تشخیص نقاط نویزی است
- انتخاب مناسب پارامترها با استفاده از روشهایی مانند نمودار k-distance ضروری است
- DBSCAN در حوزههای متنوعی از GIS تا تشخیص کلاهبرداری کاربرد دارد
۱۵.۲. توصیهها برای استفاده بهینه
برای استفاده موثر از DBSCAN:
۱. شناخت دادهها: قبل از اعمال الگوریتم، ویژگیهای دادهها را بررسی کنید ۲. نرمالسازی: دادهها را نرمالسازی کنید تا تمام ویژگیها در مقیاس مشابهی باشند ۳. تنظیم پارامترها: زمان کافی برای تنظیم پارامترها اختصاص دهید ۴. ارزیابی نتایج: از معیارهای کمی و بررسی بصری برای ارزیابی کیفیت استفاده کنید ۵. بهینهسازی عملکرد: از ساختارهای شاخصگذاری مناسب برای دادههای بزرگ استفاده کنید
۱۵.۳. چشمانداز آینده
با پیشرفت تکنولوژی و افزایش حجم دادهها، نیاز به الگوریتمهای کارآمد خوشهبندی مانند DBSCAN بیشتر احساس میشود. توسعه نسخههای بهبود یافته مانند HDBSCAN و ترکیب آن با فناوریهای نوین مانند یادگیری عمیق، آینده روشنی برای این الگوریتم ترسیم میکند.