رگرسیون خطی یکی از پایهایترین تکنیکهای یادگیری ماشین و تحلیل آماری است که برای مدلسازی رابطه بین متغیرهای مستقل و وابسته به کار میرود. با این حال، مدلهای رگرسیون خطی کلاسیک با چالشهایی همچون بیشبرازش، همخطی چندگانه و پیچیدگی بیش از حد مواجه هستند. تکنیکهای منظمسازی (Regularization) شامل Ridge، Lasso و Elastic Net با افزودن جملات جریمه به تابع هزینه، این مشکلات را برطرف میکنند. این مقاله به بررسی عمیق و مقایسه جامع این سه روش، مبانی ریاضی، کاربردها و تفاوتهای کلیدی آنها میپردازد.
مقدمه
ضرورت منظمسازی در رگرسیون خطی
در تحلیل دادههای پیچیده، مدلهای رگرسیون خطی معمولی (OLS – Ordinary Least Squares) اغلب با محدودیتهایی روبهرو میشوند که عملکرد آنها را تحت تأثیر قرار میدهد. دو چالش اصلی عبارتند از:
بیشبرازش (Overfitting): زمانی رخ میدهد که مدل به جای یادگیری الگوهای کلی، جزئیات و نویز دادههای آموزشی را حفظ میکند. این امر منجر به عملکرد ضعیف مدل روی دادههای جدید میشود. بیشبرازش معمولاً با واریانس بالا و بایاس پایین مشخص میشود.
همخطی چندگانه (Multicollinearity): زمانی اتفاق میافتد که متغیرهای مستقل همبستگی بالایی با یکدیگر داشته باشند. این پدیده باعث ناپایداری ضرایب برآوردی، افزایش خطای استاندارد و مشکل در تفسیر تأثیر متغیرهای مجزا میشود.
منظمسازی با اعمال محدودیت بر روی بزرگی ضرایب، تعادلی بین پیچیدگی مدل و برازش دادهها ایجاد میکند و مدلهای قویتر و قابل تعمیمتر تولید میکند.
مبانی نظری رگرسیون خطی
رگرسیون خطی کلاسیک
در رگرسیون خطی استاندارد، هدف یافتن بهترین خط برازش است که مجموع مربعات خطا (RSS – Residual Sum of Squares) را به حداقل برساند:
RSS = Σ(yi - ŷi)²
که در آن:
- yi: مقدار واقعی متغیر وابسته
- ŷi: مقدار پیشبینی شده
- ŷi = β₀ + β₁x₁ + β₂x₂ + … + βₚxₚ
محدودیتهای روش کمترین مربعات معمولی
روش OLS بهترین برآوردکننده خطی نااریب (BLUE – Best Linear Unbiased Estimator) است، اما چند مشکل اساسی دارد:
- واریانس بالا در حضور همخطی: زمانی که متغیرهای مستقل همبسته باشند، ماتریس X’X نزدیک به تکین میشود و برآوردهای ضرایب ناپایدار میشوند.
- حساسیت به نویز: مدلهای پیچیده با تعداد پارامتر زیاد، نویز دادهها را یاد میگیرند نه الگوهای واقعی.
- عدم انتخاب ویژگی: OLS همه متغیرها را در مدل نگه میدارد حتی اگر برخی از آنها غیرمؤثر باشند.
رگرسیون ستیغی (Ridge Regression)
تعریف و مبانی ریاضی
رگرسیون Ridge که به عنوان منظمسازی L2 نیز شناخته میشود، با افزودن جریمهای متناسب با مجموع مربعات ضرایب به تابع هزینه عمل میکند:
Ridge Loss = Σ(yi - ŷi)² + λ Σβj²
که در آن:
- λ (لامبدا): پارامتر منظمسازی که شدت جریمه را کنترل میکند
- βj: ضریب متغیر jام
- جمله اول: خطای پیشبینی
- جمله دوم: جریمه L2
ویژگیهای کلیدی Ridge
1. کوچکسازی ضرایب (Shrinkage): Ridge همه ضرایب را به سمت صفر میکشد اما هیچکدام را دقیقاً صفر نمیکند. این ویژگی باعث میشود تمام متغیرها در مدل باقی بمانند.
2. مدیریت همخطی: با کاهش بزرگی ضرایب متغیرهای همبسته، Ridge پایداری مدل را افزایش میدهد. در واقع، Ridge ضرایب متغیرهای همبسته را به مقادیر نزدیک به هم میکشاند.
3. کاهش واریانس: با محدود کردن بزرگی ضرایب، واریانس برآوردها کاهش یافته و مدل نسبت به تغییرات کوچک در دادهها حساسیت کمتری نشان میدهد.
4. افزایش بایاس: قیمت کاهش واریانس، افزایش اندکی در بایاس است که معمولاً منجر به کاهش خطای کلی میشود.
کاربردها و مزایا
- مناسب برای دادههای با همخطی بالا: زمانی که متغیرهای پیشبین همبستگی قوی دارند
- تعداد زیاد متغیرها: وقتی تعداد ویژگیها نزدیک یا بیشتر از تعداد نمونهها است
- تمام متغیرها مهم هستند: زمانی که باور داریم همه متغیرها تأثیر دارند
محدودیتها
- عدم انتخاب ویژگی: همه متغیرها در مدل باقی میمانند که تفسیر را دشوار میکند
- تفسیرپذیری پایین: با وجود تعداد زیاد متغیر، مدل نهایی پیچیده است
رگرسیون لاسو (Lasso Regression)
تعریف و مبانی ریاضی
Lasso مخفف عبارت “Least Absolute Shrinkage and Selection Operator” است که از منظمسازی L1 استفاده میکند:
Lasso Loss = Σ(yi - ŷi)² + λ Σ|βj|
تفاوت کلیدی با Ridge در استفاده از قدرمطلق ضرایب به جای مربع آنها است.
ویژگیهای متمایز Lasso
1. انتخاب خودکار ویژگی (Feature Selection): ویژگی منحصربهفرد Lasso این است که برخی از ضرایب را دقیقاً به صفر میرساند، در نتیج متغیرهای غیرمهم از مدل حذف میشوند.
2. تولید مدلهای خلوت (Sparse Models): با حذف متغیرهای غیرضروری، Lasso مدلهای سادهتر و قابل تفسیرتر تولید میکند.
3. حل چالش p > n: در شرایطی که تعداد ویژگیها بیشتر از تعداد نمونهها است، Lasso میتواند به طور مؤثر عمل کند.
4. رفتار در برابر متغیرهای همبسته: وقتی چند متغیر با هم همبستگی بالا دارند، Lasso معمولاً یکی را انتخاب کرده و بقیه را صفر میکند. این انتخاب میتواند تصادفی باشد و ناپایداری ایجاد کند.
مزایا و کاربردها
- مدلسازی قابل تفسیر: با تعداد محدود متغیرها
- کشف متغیرهای مهم: شناسایی خودکار ویژگیهای تأثیرگذار
- مناسب برای دادههای با ابعاد بالا: وقتی تعداد ویژگیها بسیار زیاد است
محدودیتها
- ناپایداری در انتخاب: در حضور متغیرهای بسیار همبسته، ممکن است در نمونههای مختلف، متغیرهای متفاوتی انتخاب شود
- محدودیت در تعداد متغیرهای انتخابی: حداکثر n متغیر را میتواند انتخاب کند (n = تعداد نمونهها)
- مشکل “Grouping Effect”: توانایی محدود در انتخاب گروهی از متغیرهای همبسته
رگرسیون شبکه الاستیک (Elastic Net)
تعریف و فلسفه طراحی
Elastic Net به عنوان ترکیبی از Ridge و Lasso طراحی شده است تا نقاط ضعف هر دو را برطرف کند:
Elastic Net Loss = Σ(yi - ŷi)² + λ₁ Σ|βj| + λ₂ Σβj²
یا به صورت معادل:
Elastic Net Loss = Σ(yi - ŷi)² + λ[α Σ|βj| + (1-α) Σβj²]
که در آن:
- α: پارامتر ترکیب (Mixing Parameter) بین 0 و 1
- α = 0: مدل تبدیل به Ridge میشود
- α = 1: مدل تبدیل به Lasso میشود
- 0 < α < 1: ترکیبی از هر دو جریمه
ویژگیهای Elastic Net
1. ترکیب بهترین ویژگیها: Elastic Net هم انتخاب ویژگی انجام میدهد (مانند Lasso) و هم پایداری در برابر همخطی دارد (مانند Ridge).
2. اثر گروهبندی (Grouping Effect): برخلاف Lasso که معمولاً یک متغیر از گروه متغیرهای همبسته را انتخاب میکند، Elastic Net تمایل دارد گروه کاملی از متغیرهای همبسته را با هم وارد یا خارج کند.
3. انعطافپذیری بالا: با دو پارامتر تنظیم (λ و α)، امکان کنترل دقیقتر رفتار مدل فراهم است.
4. پایداری بهتر: در مقایسه با Lasso، Elastic Net در انتخاب متغیرها پایدارتر است.
مزایای کلیدی
- رفع نقایص Lasso: حل مشکل ناپایداری در انتخاب متغیر
- توازن بین سادگی و عملکرد: ایجاد تعادل بین کاهش پیچیدگی و حفظ اطلاعات
- مناسب برای شرایط p >> n: عملکرد عالی در دادههای با ابعاد بسیار بالا
- مدیریت گروههای همبسته: توانایی انتخاب و حفظ گروههای متغیرهای مرتبط
محدودیتها
- پیچیدگی محاسباتی: نیاز به تنظیم دو پارامتر به جای یکی
- زمان آموزش بیشتر: محاسبات بیشتر نسبت به Ridge یا Lasso
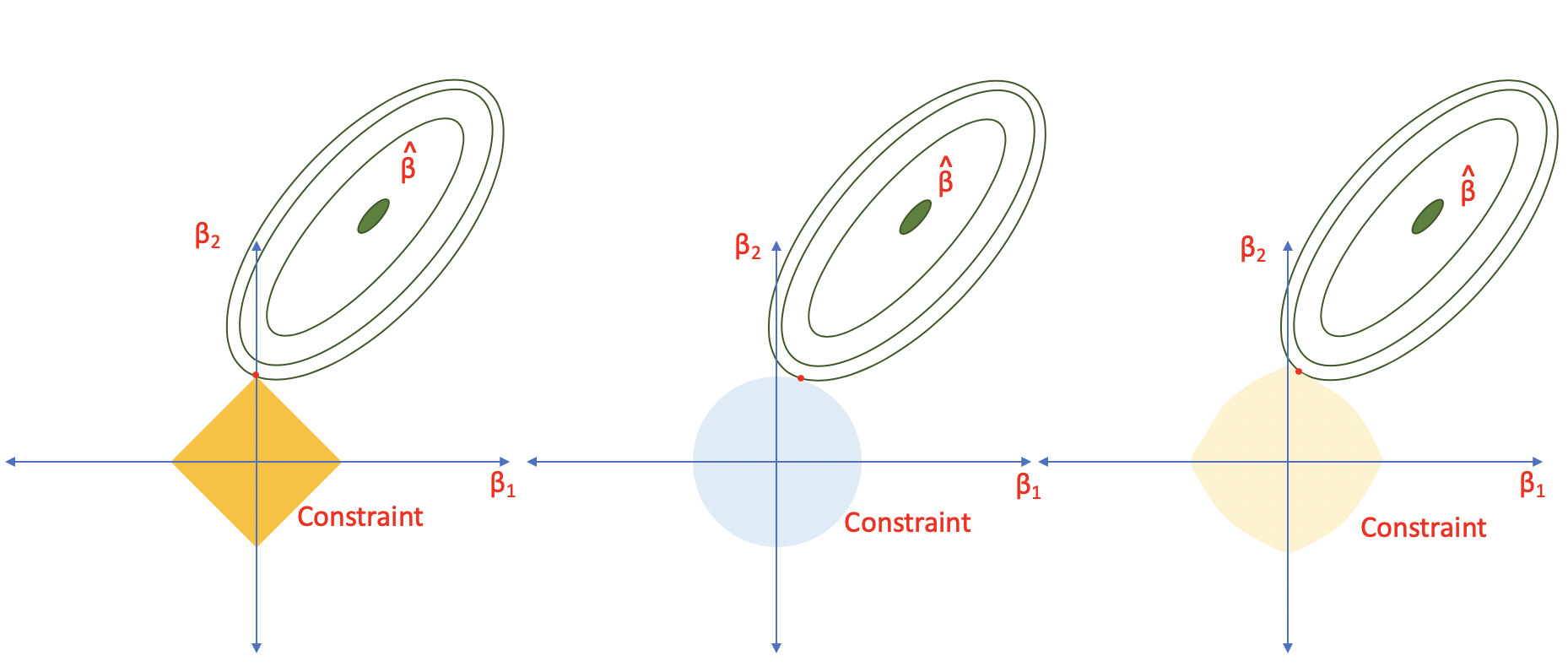
مقایسه جامع Ridge، Lasso و Elastic Net
از نظر ریاضی
| ویژگی | Ridge (L2) | Lasso (L1) | Elastic Net |
|---|---|---|---|
| نوع جریمه | Σβj² | Σ|βj| | α Σ|βj| + (1-α) Σβj² |
| انتخاب ویژگی | خیر | بله | بله |
| صفر کردن ضرایب | خیر | بله | بله |
| پایداری | بالا | پایین (در همخطی) | بالا |
| تفسیرپذیری | پایین | بالا | متوسط تا بالا |
مقایسه عملکرد
Ridge مناسب است برای:
- دادههایی که همه یا اکثر متغیرها مؤثر هستند
- حضور همخطی شدید بین متغیرها
- نیاز به پایداری بالای ضرایب
- زمانی که هدف پیشبینی است نه تفسیر
Lasso مناسب است برای:
- تعداد کم متغیرهای مؤثر در میان متغیرهای زیاد
- نیاز به مدل ساده و قابل تفسیر
- شناسایی و انتخاب خودکار ویژگیها
- زمانی که بسیاری از متغیرها بیربط هستند
Elastic Net مناسب است برای:
- وجود گروههای متغیرهای همبسته
- ترکیب نیاز به انتخاب ویژگی و مدیریت همخطی
- دادههای با ابعاد بسیار بالا (p >> n)
- نیاز به پایداری و تفسیرپذیری همزمان
مقایسه رفتار در شرایط خاص
در حضور متغیرهای همبسته:
- Ridge: ضرایب متغیرهای همبسته را به مقادیر مشابه میکشاند
- Lasso: یکی را انتخاب و بقیه را صفر میکند (ناپایدار)
- Elastic Net: گروه متغیرهای همبسته را با هم حفظ میکند (پایدار)
در شرایط p > n (تعداد ویژگیها > تعداد نمونهها):
- Ridge: کار میکند اما همه متغیرها را حفظ میکند
- Lasso: حداکثر n متغیر را انتخاب میکند
- Elastic Net: محدودیتی ندارد و عملکرد بهتری دارد
مقایسه محاسباتی
حل تحلیلی:
- Ridge: دارای حل تحلیلی مستقیم → محاسبات سریعتر
- Lasso: نیاز به روشهای تکراری (Coordinate Descent)
- Elastic Net: نیاز به روشهای تکراری (پیچیدهتر)
مقیاسپذیری:
- Ridge: بهترین گزینه برای دادههای بزرگ
- Lasso: سرعت متوسط
- Elastic Net: کندترین اما قویترین
انتخاب پارامترهای تنظیم
تنظیم پارامتر λ (Lambda)
پارامتر λ شدت منظمسازی را کنترل میکند:
- λ = 0: مدل تبدیل به رگرسیون خطی معمولی میشود (احتمال بیشبرازش)
- λ → ∞: همه ضرایب به سمت صفر میروند (احتمال کمبرازش)
- λ بهینه: تعادل بین بایاس و واریانس
تنظیم پارامتر α در Elastic Net
- α = 0: رفتار Ridge (بدون انتخاب ویژگی)
- α = 1: رفتار Lasso (انتخاب قوی ویژگی)
- 0.5 ≤ α ≤ 0.95: معمولاً بهترین نتایج را میدهد
روشهای تنظیم
1. اعتبارسنجی متقاطع (Cross-Validation): روش استاندارد و رایج که داده را به k قسمت تقسیم کرده و مدل را k بار آموزش و ارزیابی میکند.
2. جستجوی شبکهای (Grid Search): آزمون مقادیر مختلف پارامترها در یک شبکه از مقادیر از پیش تعیین شده.
3. جستجوی تصادفی (Random Search): نمونهبرداری تصادفی از فضای پارامترها که اغلب کارآمدتر است.
پیادهسازی عملی
مراحل اجرای مدلهای منظمسازی
1. آمادهسازی داده:
- استانداردسازی ویژگیها (بسیار مهم!)
- تقسیم داده به آموزش و آزمون
- بررسی همخطی با VIF
2. انتخاب روش مناسب:
- بررسی ماهیت دادهها
- تعیین اهداف (پیشبینی یا تفسیر)
- شناسایی چالشهای خاص (همخطی، ابعاد بالا)
3. تنظیم پارامترها:
- استفاده از CV برای یافتن λ بهینه
- در Elastic Net، تنظیم α نیز ضروری است
4. ارزیابی مدل:
- استفاده از معیارهای RMSE، MAE، R²
- بررسی پایداری ضرایب
- مقایسه عملکرد روی داده آزمون
کتابخانهها و ابزارها
Python:
- Scikit-learn: Ridge, Lasso, ElasticNet
- statsmodels: مدلهای آماری پیشرفته
- glmnet: پیادهسازی کارآمد
R:
- glmnet: استاندارد طلایی برای منظمسازی
- caret: فریمورک جامع یادگیری ماشین
- elasticnet: پیادهسازی تخصصی
کاربردهای واقعی
1. انتخاب ژنومی (Genomic Selection)
در ژنتیک، تعداد نشانگرهای DNA (SNPs) اغلب از تعداد نمونهها بیشتر است. مطالعات نشان دادهاند که:
- Elastic Net و Lasso دقت بهتری نسبت به Ridge دارند
- توانایی انتخاب نشانگرهای مؤثر اهمیت دارد
- Elastic Net در حضور نشانگرهای همبسته پایدارتر است
2. پیشبینی قیمت مسکن
با ویژگیهای متعدد و همبسته (مساحت، تعداد اتاق، موقعیت):
- Ridge برای نگه داشتن همه ویژگیها مناسب است
- Lasso برای شناسایی مهمترین عوامل
- Elastic Net برای تعادل بین دقت و سادگی
3. تحلیل مالی و اقتصادی
در پیشبینی بازارهای مالی با دادههای سری زمانی همبسته:
- Ridge برای مدیریت همخطی بین شاخصهای اقتصادی
- Elastic Net برای انتخاب متغیرهای کلان اقتصادی مؤثر
4. پردازش تصویر و بینایی ماشین
در تشخیص الگو با ویژگیهای پیکسلهای همبسته:
- Lasso برای کاهش ابعاد و انتخاب ویژگی
- Elastic Net برای حفظ ساختارهای مکانی مرتبط
بهترین شیوهها و توصیههای عملی
1. استانداردسازی دادهها
ضروری است: تمام روشهای منظمسازی نسبت به مقیاس ویژگیها حساس هستند. همیشه دادهها را قبل از اعمال Ridge، Lasso یا Elastic Net استاندارد کنید.
2. شروع با Elastic Net
در صورت عدم اطمینان، Elastic Net معمولاً انتخاب امنی است چون:
- انعطافپذیری بالا دارد
- میتواند رفتار Ridge یا Lasso را شبیهسازی کند
- در اکثر شرایط عملکرد خوبی دارد
3. استفاده از Cross-Validation
همیشه از اعتبارسنجی متقاطع برای:
- انتخاب پارامتر λ بهینه
- مقایسه عملکرد روشهای مختلف
- جلوگیری از بیشبرازش
4. تفسیر نتایج با احتیاط
- ضرایب منظمسازیشده نمایانگر “اهمیت” مستقیم متغیرها نیستند
- در Lasso، متغیرهای حذفشده لزوماً بیاهمیت نیستند
- همبستگی بین متغیرها را در نظر بگیرید
5. تشخیص همخطی
قبل از انتخاب روش، همخطی را بررسی کنید:
- محاسبه VIF (Variance Inflation Factor)
- بررسی ماتریس همبستگی
- VIF > 5-10: نشانه همخطی قوی
چالشها و محدودیتها
چالشهای مشترک
1. انتخاب پارامتر بهینه: پیدا کردن λ و α مناسب میتواند زمانبر باشد و نیازمند محاسبات سنگین است.
2. تفسیر در مدلهای پیچیده: وقتی تعداد متغیرهای زیادی وجود دارد، تفسیر ضرایب کوچکشده دشوار است.
3. فرض خطی بودن: همه این روشها فرض میکنند رابطه بین متغیرها خطی است که همیشه صادق نیست.
محدودیتهای خاص
Ridge:
- نمیتواند ویژگیهای غیرمهم را حذف کند
- تفسیر مشکل در حضور متغیرهای بسیار
Lasso:
- ناپایداری در انتخاب متغیرهای همبسته
- محدودیت در تعداد متغیرهای قابل انتخاب (حداکثر n)
Elastic Net:
- نیاز به تنظیم دو پارامتر
- پیچیدگی محاسباتی بیشتر
نتیجهگیری
تکنیکهای منظمسازی Ridge، Lasso و Elastic Net ابزارهای قدرتمندی برای بهبود مدلهای رگرسیون خطی هستند که هر یک مزایا و کاربردهای خاص خود را دارند:
Ridge Regression با استفاده از جریمه L2، بهترین گزینه برای مدیریت همخطی و کاهش واریانس است، اما متغیرها را حذف نمیکند.
Lasso Regression با جریمه L1، قابلیت انتخاب خودکار ویژگی را فراهم میکند و مدلهای خلوت و قابل تفسیر تولید میکند، اما در حضور متغیرهای بسیار همبسته ناپایدار است.
Elastic Net با ترکیب هوشمند هر دو جریمه L1 و L2، توازن بهینهای بین انتخاب ویژگی و مدیریت همخطی ایجاد میکند و در اکثر شرایط عملی عملکرد برتری دارد.
انتخاب روش مناسب
انتخاب بین این سه روش باید بر اساس ویژگیهای داده و اهداف مدلسازی باشد:
- اگر همه متغیرها احتمالاً مؤثر هستند و همخطی شدید وجود دارد → Ridge
- اگر بسیاری از متغیرها غیرمؤثر هستند و نیاز به مدل ساده دارید → Lasso
- اگر گروههای متغیرهای همبسته دارید یا مطمئن نیستید → Elastic Net
- برای بیشتر کاربردهای واقعی با دادههای پیچیده → Elastic Net
نکات کلیدی برای موفقیت
- همیشه دادهها را استانداردسازی کنید قبل از اعمال هر روش منظمسازی
- از Cross-Validation استفاده کنید برای تنظیم پارامترها
- چند روش را امتحان کنید و نتایج را مقایسه کنید
- ماهیت داده را بشناسید: همخطی، تعداد ویژگیها، نسبت p/n
- هدف را مشخص کنید: پیشبینی دقیق یا تفسیر ساده
چشمانداز آینده
تکنیکهای منظمسازی رگرسیون های خطی همچنان در حال تکامل هستند و روشهای جدیدی مانند Adaptive Lasso، Group Lasso، و Sparse Group Lasso برای کاربردهای تخصصیتر توسعه یافتهاند. با این حال، Ridge، Lasso و Elastic Net همچنان پایههای اساسی یادگیری ماشین مدرن باقی میمانند.
پیوست: فرمولهای ریاضی تکمیلی
معادلات کامل بهینهسازی
Ridge Regression – فرم ماتریسی:
β̂_ridge = (X'X + λI)⁻¹X'y
که در آن I ماتریس همانی است.
Lasso – مسئله بهینهسازی:
minimize: (1/2n)||y - Xβ||₂² + λ||β||₁
Elastic Net – فرم کامل:
minimize: (1/2n)||y - Xβ||₂² + λ₁||β||₁ + λ₂||β||₂²
تبدیل پارامترها
رابطه بین دو فرم نمایش Elastic Net:
λ₁ = λα
λ₂ = λ(1-α)
محاسبه VIF برای تشخیص همخطی
VIF_j = 1 / (1 - R²_j)
که R²_j ضریب تعیین رگرسیون متغیر j روی سایر متغیرها است.
تفسیر VIF:
- VIF = 1: بدون همبستگی
- 1 < VIF < 5: همبستگی متوسط (قابل قبول)
- VIF > 5-10: همبستگی قوی (نیاز به منظمسازی)
- VIF > 10: همخطی شدید (حتماً از Ridge یا Elastic Net استفاده کنید)
خلاصه مقایسه سریع
| معیار | Ridge | Lasso | Elastic Net |
|---|---|---|---|
| نوع جریمه | L2 (مربع) | L1 (قدرمطلق) | L1 + L2 |
| انتخاب ویژگی | ✗ | ✓ | ✓ |
| مدیریت همخطی | عالی | ضعیف | عالی |
| تفسیرپذیری | پایین | بالا | بالا |
| پایداری | بالا | متوسط | بالا |
| سرعت محاسبات | سریع | متوسط | کند |
| تعداد پارامترها | 1 (λ) | 1 (λ) | 2 (λ, α) |
| مناسب برای p >> n | بله | محدود | عالی |
| مناسب برای همخطی شدید | بله | خیر | بله |
| مدل خلوت (Sparse) | خیر | بله | بله |
سؤالات متداول (FAQ)
1. آیا باید همیشه از منظمسازی استفاده کنیم؟
خیر، اگر:
- تعداد نمونهها >> تعداد ویژگیها
- همخطی وجود ندارد
- بیشبرازش مشکل نیست
- مدل ساده کافی است
رگرسیون معمولی (OLS) کافی است.
2. چگونه میتوانم تشخیص دهم کدام روش بهتر است؟
بهترین راه:
- مدلهای مختلف را آموزش دهید
- با Cross-Validation مقایسه کنید
- معیارهای متعدد (RMSE, MAE, R²) را بررسی کنید
- روی دادههای آزمون ارزیابی کنید
3. آیا میتوانم از این روشها برای طبقهبندی استفاده کنم؟
بله، نسخههای رگرسیون لجستیک منظمشده وجود دارند:
- Logistic Ridge
- Logistic Lasso
- Logistic Elastic Net
با همان مفاهیم اما برای مسائل طبقهبندی.
4. چرا استانداردسازی ضروری است؟
جریمههای منظمسازی بر اساس بزرگی ضرایب عمل میکنند. اگر متغیرها مقیاسهای مختلف داشته باشند:
- متغیرهای بزرگمقیاس ضرایب کوچکتر دارند
- متغیرهای کوچکمقیاس ضرایب بزرگتر دارند
- منظمسازی ناعادلانه اعمال میشود
5. آیا میتوانم از این روشها با دادههای دستهای استفاده کنم؟
بله، اما باید:
- متغیرهای دستهای را One-Hot Encode کنید
- توجه داشته باشید که متغیرهای کدگذاریشده همبسته هستند
- Elastic Net معمولاً بهترین انتخاب است
نتیجهگیری نهایی
رگرسیونهای خطی منظمشده Ridge، Lasso و Elastic Net ابزارهای ضروری در جعبهابزار هر دانشمند داده و مهندس یادگیری ماشین هستند. درک عمیق تفاوتها، مزایا و محدودیتهای هر روش، کلید استفاده مؤثر از آنها در مسائل واقعی است.
این مقاله تلاش کرده است تا مبانی نظری، جنبههای عملی و راهنمایهای کاربردی را به صورت جامع ارائه دهد. با تسلط بر این تکنیکها، میتوانید مدلهای قویتر، پایدارتر و قابل تفسیرتری بسازید که در محیطهای تولیدی عملکرد بهتری دارند.