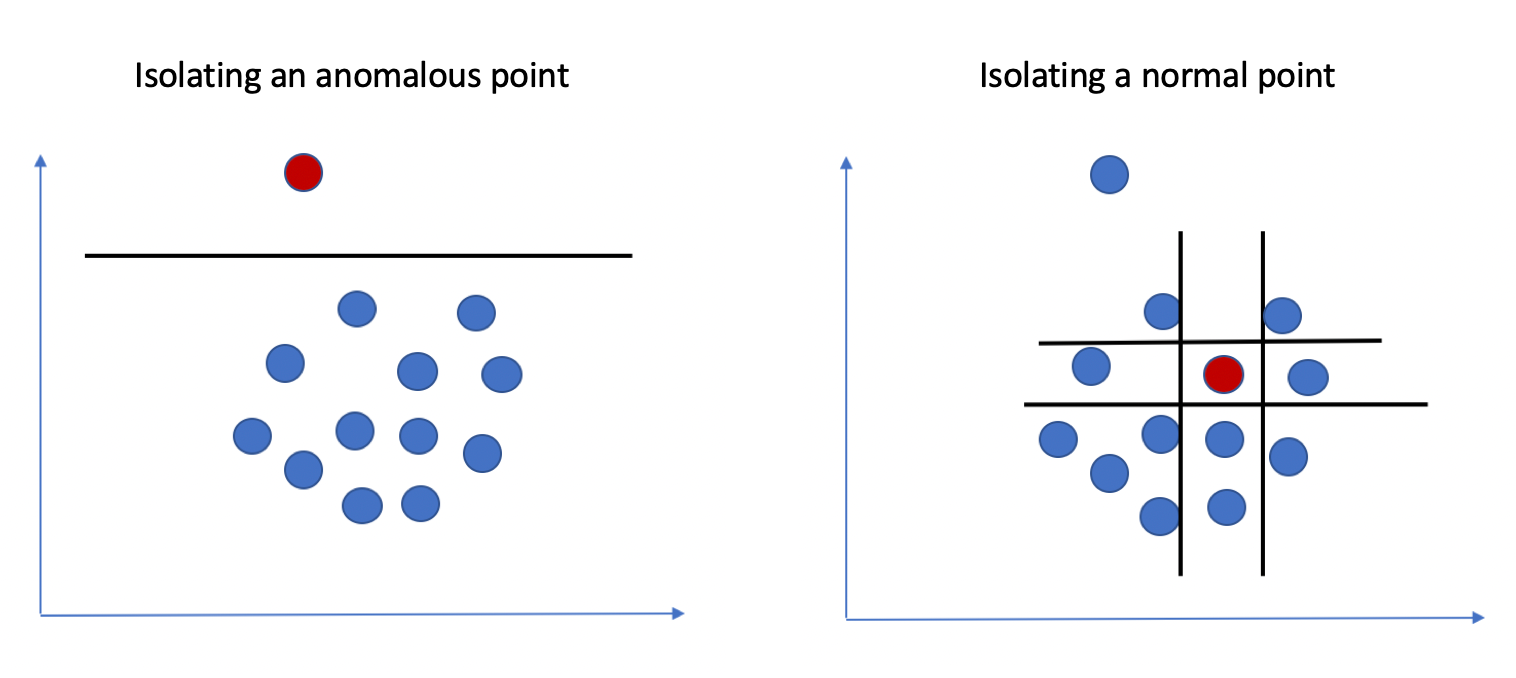
تشخیص ناهنجاری یکی از چالشهای مهم در تحلیل داده و یادگیری ماشین محسوب میشود که کاربردهای گستردهای در حوزههایی نظیر امنیت سایبری، تشخیص تقلب مالی، پایش سیستمهای صنعتی و تشخیص خرابی تجهیزات دارد. الگوریتم Isolation Forest که در سال ۲۰۰۸ توسط فی تونی لیو و همکارانش معرفی شد، یکی از موثرترین روشهای تشخیص ناهنجاری بدون نظارت محسوب میشود. این الگوریتم با رویکردی متفاوت نسبت به سایر روشها، به جای تعریف رفتار نرمال، مستقیماً ناهنجاریها را جداسازی میکند. مقاله حاضر به بررسی جامع مبانی نظری، پیادهسازی عملی و کاربردهای این الگوریتم میپردازد و نسخههای توسعهیافته آن را معرفی میکند.
۱. مقدمه
در عصر کلانداده، شناسایی الگوهای غیرعادی و نقاط پرت اهمیت روزافزونی یافته است. ناهنجاریها میتوانند نشاندهنده مشکلات امنیتی، فعالیتهای متقلبانه، خرابی تجهیزات یا حتی کشفهای علمی جدید باشند. روشهای سنتی تشخیص ناهنجاری عمدتاً بر پایه تعریف رفتار نرمال و سپس شناسایی انحراف از آن استوار هستند. این رویکرد چالشهایی نظیر نیاز به دادههای برچسبگذاری شده، پیچیدگی محاسباتی بالا و حساسیت به توزیع دادهها را به همراه دارد.
الگوریتم Isolation Forest بر این اصل استوار است که ناهنجاریها نادر و متفاوت هستند، بنابراین آسانتر از نقاط نرمال جداسازی میشوند. این الگوریتم در سال ۲۰۰۸ توسط فی تونی لیو، کای مینگ تینگ و ژیهوا ژو توسعه داده شد و به سرعت به یکی از محبوبترین روشهای تشخیص ناهنجاری تبدیل گردید.
۱.۱ اهمیت تشخیص ناهنجاری
تشخیص ناهنجاری در حوزههای مختلف کاربردهای حیاتی دارد:
- امنیت سایبری: شناسایی نفوذها و حملات سایبری
- بانکداری و مالی: تشخیص تراکنشهای مشکوک و تقلب
- صنعت: پیشبینی خرابی تجهیزات و نگهداری پیشگیرانه
- پزشکی: شناسایی بیماریهای نادر و موارد غیرعادی
- علم داده: پاکسازی داده و بهبود کیفیت مدلسازی
۲. مبانی نظری الگوریتم Isolation Forest
۲.۱ مفهوم جداسازی (Isolation)
الگوریتم Isolation Forest از ساختار درختهای باینری برای جداسازی نقاط داده استفاده میکند و پیچیدگی زمانی خطی دارد که آن را برای دادههای حجیم مناسب میسازد. ایده اصلی این است که ناهنجاریها به دلیل تفاوت ذاتیشان، با تعداد تقسیمبندی کمتری از بقیه دادهها جدا میشوند.
۲.۲ ساختار درخت ایزوله (Isolation Tree)
الگوریتم با انتخاب تصادفی یک ویژگی و سپس انتخاب تصادفی یک مقدار تقسیم بین حداقل و حداکثر مقادیر آن ویژگی، فضای داده را تقسیم میکند. این فرآیند به صورت بازگشتی ادامه مییابد تا هر نقطه داده در یک گره برگ جداگانه قرار گیرد.
فرآیند ساخت درخت ایزوله:
- انتخاب تصادفی یک ویژگی از مجموعه ویژگیها
- انتخاب تصادفی یک نقطه تقسیم در بازه مقادیر آن ویژگی
- تقسیم دادهها به دو زیرمجموعه بر اساس مقدار آستانه
- تکرار بازگشتی تا رسیدن به عمق مشخص یا جداسازی کامل
۲.۳ محاسبه امتیاز ناهنجاری
امتیاز ناهنجاری یک نمونه ورودی به صورت میانگین امتیاز ناهنجاری در همه درختهای جنگل محاسبه میشود، که معیار نرمال بودن یک مشاهده در یک درخت، عمق گره برگ حاوی آن مشاهده است.
فرمول محاسبه امتیاز ناهنجاری بر اساس طول مسیر متوسط است و هرچه این نسبت به صفر نزدیکتر باشد، امتیاز به ۱ نزدیکتر شده و احتمال ناهنجاری بیشتر است.
فرمول امتیاز ناهنجاری:
s(x) = 2^(-E[h(x)]/c(n))
که در آن:
s(x): امتیاز ناهنجاری نقطه xE[h(x)]: میانگین طول مسیر x در تمام درختهاc(n): میانگین طول مسیر در یک درخت جستجوی باینری با n نمونه
۲.۴ مزایای الگوریتم
Isolation Forest دارای پیچیدگی زمانی O(n*logn) است که آن را برای مجموعه دادههای بزرگ کارآمد میسازد. سایر مزایای کلیدی:
- عدم نیاز به دادههای برچسبدار: الگوریتم کاملاً بدون نظارت عمل میکند
- سرعت بالا: به دلیل نمونهبرداری تصادفی و عمق محدود درختها
- مقیاسپذیری: قابلیت اجرا بر روی دادههای با ابعاد بالا
- مقاومت در برابر نویز: حساسیت کم به نویز و نقاط پرت
۳. پیادهسازی الگوریتم در Python
۳.۱ کتابخانههای مورد نیاز
کتابخانه scikit-learn پیادهسازی استانداردی از IsolationForest ارائه میدهد که به طور گسترده توسط دانشمندان داده استفاده میشود.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.ensemble import IsolationForest
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix
۳.۲ آمادهسازی دادهها
# خواندن دادهها
data = pd.read_csv('data.csv')
# استانداردسازی ویژگیها
scaler = StandardScaler()
X_scaled = scaler.fit_transform(data)
# تقسیم دادهها
X_train, X_test = train_test_split(X_scaled, test_size=0.2, random_state=42)
۳.۳ ایجاد و آموزش مدل
پارامترهای کلیدی IsolationForest شامل n_estimators (تعداد درختها)، max_samples (تعداد نمونهها برای هر درخت) و contamination (نسبت ناهنجاریها) میباشد.
# تعریف مدل با پارامترهای بهینه
iso_forest = IsolationForest(
n_estimators=100, # تعداد درختهای ایزوله
max_samples='auto', # تعداد نمونه برای هر درخت
contamination=0.1, # درصد تخمینی ناهنجاریها
max_features=1.0, # تعداد ویژگیهای استفاده شده
bootstrap=False, # نمونهبرداری بدون جایگذاری
random_state=42 # برای تکرارپذیری نتایج
)
# آموزش مدل
iso_forest.fit(X_train)
# پیشبینی ناهنجاریها
predictions = iso_forest.predict(X_test)
# 1: نرمال، -1: ناهنجاری
# محاسبه امتیاز ناهنجاری
anomaly_scores = iso_forest.score_samples(X_test)
۳.۴ ارزیابی مدل
# تبدیل برچسبها برای ارزیابی
# فرض: y_true حاوی برچسبهای واقعی است (0: نرمال، 1: ناهنجاری)
y_pred = (predictions == -1).astype(int)
# محاسبه معیارهای ارزیابی
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
accuracy = accuracy_score(y_true, y_pred)
precision = precision_score(y_true, y_pred)
recall = recall_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)
print(f"دقت (Accuracy): {accuracy:.3f}")
print(f"صحت (Precision): {precision:.3f}")
print(f"بازخوانی (Recall): {recall:.3f}")
print(f"معیار F1: {f1:.3f}")
۴. تنظیم پارامترها (Hyperparameter Tuning)
۴.۱ پارامتر Contamination
پارامتر contamination آستانه تصمیمگیری را کنترل میکند و تعیین میکند که چه نسبتی از دادهها به عنوان ناهنجاری طبقهبندی شوند، که این پارامتر بین ۰ و ۰.۵ قابل تنظیم است.
# جستجوی بهترین مقدار contamination
contamination_values = [0.01, 0.05, 0.1, 0.15, 0.2]
scores = {}
for cont in contamination_values:
model = IsolationForest(contamination=cont, random_state=42)
model.fit(X_train)
pred = model.predict(X_test)
score = f1_score(y_true, (pred == -1).astype(int))
scores[cont] = score
best_contamination = max(scores, key=scores.get)
print(f"بهترین مقدار contamination: {best_contamination}")
۴.۲ تنظیم همزمان پارامترها
میتوان پارامترهای n_estimators و max_samples را به صورت همزمان با استفاده از روشهای جستجوی شبکهای یا تکنیکهای بهینهسازی تنظیم کرد.
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import make_scorer
# تعریف فضای جستجو
param_grid = {
'n_estimators': [50, 100, 200],
'max_samples': [0.5, 0.75, 1.0],
'max_features': [0.5, 0.75, 1.0],
'contamination': [0.05, 0.1, 0.15]
}
# جستجوی شبکهای
grid_search = GridSearchCV(
IsolationForest(random_state=42),
param_grid,
cv=3,
scoring=make_scorer(f1_score),
n_jobs=-1
)
grid_search.fit(X_train, y_train)
best_params = grid_search.best_params_
۵. الگوریتم Extended Isolation Forest
۵.۱ محدودیتهای Isolation Forest استاندارد
الگوریتم استاندارد Isolation Forest از برشهای موازی با محورها استفاده میکند که میتواند منجر به ایجاد آرتیفکت در نقشههای امتیاز ناهنجاری شود.
۵.۲ معرفی Extended Isolation Forest
Extended Isolation Forest (EIF) که توسط ساهند حریری و همکاران معرفی شد، با استفاده از ابرصفحههای با شیب تصادفی به جای برشهای موازی با محور، سازگاری و قابلیت اطمینان امتیاز ناهنجاری را بهبود میبخشد.
۵.۳ پیادهسازی EIF
# نصب کتابخانه eif
# pip install eif
import eif
# ایجاد مدل Extended Isolation Forest
eif_model = eif.iForest(
ntrees=100,
sample_size=256,
ExtensionLevel=len(features)-1 # حداکثر گسترش
)
# آموزش مدل
eif_model.fit(X_train)
# محاسبه امتیازات ناهنجاری
eif_scores = eif_model.compute_paths(X_test)
۵.۴ مقایسه IF و EIF
EIF در مقایسه با IF استاندارد، دقیقتر در ارزیابی امتیازات ناهنجاری عمل میکند و قادر به تشخیص ناهنجاریهایی است که نزدیک به دادههای نرمال قرار دارند.
# مقایسه عملکرد
def compare_models(X_train, X_test, y_test):
# Isolation Forest استاندارد
if_model = IsolationForest(contamination=0.1)
if_model.fit(X_train)
if_pred = if_model.predict(X_test)
if_f1 = f1_score(y_test, (if_pred == -1).astype(int))
# Extended Isolation Forest
eif_model = eif.iForest(ntrees=100, ExtensionLevel=X_train.shape[1]-1)
eif_model.fit(X_train)
eif_scores = eif_model.compute_paths(X_test)
threshold = np.percentile(eif_scores, 90)
eif_pred = (eif_scores > threshold).astype(int)
eif_f1 = f1_score(y_test, eif_pred)
print(f"F1-Score IF: {if_f1:.3f}")
print(f"F1-Score EIF: {eif_f1:.3f}")
۶. کاربردهای عملی
۶.۱ تشخیص تقلب در تراکنشهای مالی
در تشخیص تقلب کارت اعتباری، Isolation Forest میتواند با دقت بالا تراکنشهای مشکوک را شناسایی کند، هرچند چالشهایی نظیر عدم توازن شدید دادهها وجود دارد.
# مثال: تشخیص تقلب در کارت اعتباری
from sklearn.datasets import make_classification
# شبیهسازی داده تراکنش
X, y = make_classification(
n_samples=10000,
n_features=10,
n_informative=8,
n_redundant=2,
n_clusters_per_class=1,
weights=[0.99, 0.01], # 1% تقلب
flip_y=0.01,
random_state=42
)
# آموزش مدل
fraud_detector = IsolationForest(
contamination=0.01, # انتظار 1% تقلب
n_estimators=200,
random_state=42
)
fraud_detector.fit(X)
# شناسایی تراکنشهای مشکوک
suspicious = fraud_detector.predict(X)
print(f"تعداد تراکنشهای مشکوک: {sum(suspicious == -1)}")
۶.۲ تشخیص نفوذ در شبکه
# مثال: تشخیص ترافیک غیرعادی شبکه
def network_anomaly_detection(network_data):
# استخراج ویژگیها
features = ['packet_size', 'duration', 'byte_rate', 'packet_rate']
X = network_data[features]
# نرمالسازی
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# مدل تشخیص ناهنجاری
detector = IsolationForest(
contamination=0.001, # انتظار 0.1% حمله
n_estimators=150,
max_samples=512,
random_state=42
)
# آموزش و پیشبینی
detector.fit(X_scaled)
anomalies = detector.predict(X_scaled)
# گزارش نتایج
network_data['is_anomaly'] = anomalies == -1
return network_data[network_data['is_anomaly']]
۶.۳ پایش سلامت تجهیزات صنعتی
# مثال: تشخیص خرابی در سنسورهای صنعتی
def equipment_monitoring(sensor_data):
# پیشپردازش دادههای سری زمانی
from sklearn.preprocessing import RobustScaler
scaler = RobustScaler()
scaled_data = scaler.fit_transform(sensor_data)
# ایجاد ویژگیهای آماری
window_size = 100
features = []
for i in range(len(scaled_data) - window_size):
window = scaled_data[i:i+window_size]
feature_vector = [
np.mean(window),
np.std(window),
np.max(window) - np.min(window),
np.percentile(window, 75) - np.percentile(window, 25)
]
features.append(feature_vector)
# تشخیص ناهنجاری
detector = IsolationForest(
contamination='auto',
n_estimators=100,
random_state=42
)
anomalies = detector.fit_predict(features)
return anomalies
۷. بهینهسازی عملکرد
۷.۱ استفاده از پردازش موازی
پارامتر n_jobs را میتوان روی -1 تنظیم کرد تا از تمام منابع سیستم برای پردازش موازی استفاده شود.
# فعالسازی پردازش موازی
parallel_model = IsolationForest(
n_estimators=500,
n_jobs=-1, # استفاده از تمام هستههای پردازنده
random_state=42
)
# مقایسه زمان اجرا
import time
# مدل تکرشتهای
start = time.time()
single_model = IsolationForest(n_estimators=500, n_jobs=1)
single_model.fit(X_train)
single_time = time.time() - start
# مدل چندرشتهای
start = time.time()
parallel_model.fit(X_train)
parallel_time = time.time() - start
print(f"زمان اجرای تکرشته: {single_time:.2f} ثانیه")
print(f"زمان اجرای چندرشته: {parallel_time:.2f} ثانیه")
print(f"سرعت بهبود: {single_time/parallel_time:.2f}x")
۷.۲ بهینهسازی حافظه
# استفاده از نمونهبرداری برای دادههای بزرگ
def memory_efficient_isolation_forest(data, batch_size=10000):
n_samples = len(data)
n_batches = (n_samples + batch_size - 1) // batch_size
models = []
for i in range(n_batches):
start_idx = i * batch_size
end_idx = min((i + 1) * batch_size, n_samples)
batch = data[start_idx:end_idx]
model = IsolationForest(
n_estimators=50,
max_samples=min(256, len(batch)),
contamination=0.1
)
model.fit(batch)
models.append(model)
return models
# ترکیب نتایج از مدلهای مختلف
def ensemble_predict(models, X):
predictions = []
for model in models:
pred = model.score_samples(X)
predictions.append(pred)
# میانگین امتیازات
avg_scores = np.mean(predictions, axis=0)
threshold = np.percentile(avg_scores, 10)
return (avg_scores < threshold).astype(int)
۸. تجسم نتایج
۸.۱ نمایش توزیع امتیازات ناهنجاری
import matplotlib.pyplot as plt
import seaborn as sns
def visualize_anomaly_scores(model, X, y_true=None):
# محاسبه امتیازات
scores = model.score_samples(X)
predictions = model.predict(X)
# ایجاد نمودار
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# توزیع امتیازات
axes[0].hist(scores, bins=50, edgecolor='black', alpha=0.7)
axes[0].axvline(x=np.percentile(scores, 10),
color='red', linestyle='--',
label='آستانه ناهنجاری')
axes[0].set_xlabel('امتیاز ناهنجاری')
axes[0].set_ylabel('فراوانی')
axes[0].set_title('توزیع امتیازات ناهنجاری')
axes[0].legend()
# نمودار پراکندگی
if X.shape[1] >= 2:
colors = ['blue' if p == 1 else 'red' for p in predictions]
axes[1].scatter(X[:, 0], X[:, 1], c=colors, alpha=0.6)
axes[1].set_xlabel('ویژگی 1')
axes[1].set_ylabel('ویژگی 2')
axes[1].set_title('نقاط نرمال (آبی) و ناهنجار (قرمز)')
plt.tight_layout()
plt.show()
# نمایش ماتریس درهمریختگی
def plot_confusion_matrix(y_true, y_pred):
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_true, y_pred)
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel('برچسب پیشبینی شده')
plt.ylabel('برچسب واقعی')
plt.title('ماتریس درهمریختگی')
plt.show()
۸.۲ نمایش درختهای ایزوله
def visualize_isolation_path(model, sample_point):
"""
نمایش مسیر جداسازی یک نقطه در درختهای ایزوله
"""
# استخراج درختهای پایه
trees = model.estimators_
features = model.estimators_features_
path_lengths = []
for tree, feat_subset in zip(trees, features):
# محاسبه عمق برای نمونه
leaf_id = tree.apply(sample_point.reshape(1, -1)[:, feat_subset])[0]
path_length = tree.tree_.compute_node_depths()[leaf_id]
path_lengths.append(path_length)
# نمایش توزیع طول مسیرها
plt.figure(figsize=(10, 5))
plt.hist(path_lengths, bins=20, edgecolor='black')
plt.axvline(x=np.mean(path_lengths), color='red',
linestyle='--', label=f'میانگین: {np.mean(path_lengths):.2f}')
plt.xlabel('طول مسیر')
plt.ylabel('تعداد درختها')
plt.title('توزیع طول مسیر جداسازی در درختهای مختلف')
plt.legend()
plt.show()
۹. چالشها و محدودیتها
۹.۱ مشکل Swamping
زمانی که فاصله میان نقاط نرمال و نقاط ناهنجار بسیار کم باشد، تعداد درختهای موردنیاز برای جداسازی ناهنجاریها افزایش مییابد و پدیدهای به نام “غرق شدن” رخ میدهد که باعث میشود الگوریتم تفاوت میان نقاط ناهنجار و نرمال را به کندی و با اشتباه فراوان تشخیص دهد.
۹.۲ عملکرد در دادههای کوچک
یکی از محدودیتهای Isolation Forest این است که ممکن است با مجموعه دادههای کوچک عملکرد خوبی نداشته باشد، که این به دلیل فرآیند تصادفی ایجاد درختهای ایزوله است.
۹.۳ حساسیت به پارامترها
الگوریتم به تنظیم دقیق پارامترها حساس است، به ویژه نرخ آلودگی (contamination) و نمونهبرداری ویژگی که به شدت بر عملکرد مدل تأثیر میگذارند و نیاز به تنظیم گسترده دارند.
۹.۴ راهحلها و بهبودها
# استفاده از تکنیکهای ensemble برای بهبود عملکرد
class ImprovedIsolationForest:
def __init__(self, n_models=5):
self.models = []
self.n_models = n_models
def fit(self, X):
# آموزش چندین مدل با پارامترهای مختلف
contamination_values = np.linspace(0.05, 0.15, self.n_models)
for cont in contamination_values:
model = IsolationForest(
n_estimators=100,
contamination=cont,
max_samples=np.random.choice([128, 256, 512]),
random_state=np.random.randint(1000)
)
model.fit(X)
self.models.append(model)
return self
def predict(self, X):
# ترکیب پیشبینیها با رأیگیری
predictions = []
for model in self.models:
pred = model.predict(X)
predictions.append(pred)
# رأیگیری اکثریت
predictions = np.array(predictions)
final_pred = np.sign(np.sum(predictions, axis=0))
final_pred[final_pred == 0] = 1 # در صورت تساوی، نرمال در نظر بگیر
return final_pred
۱۰. مقایسه با سایر الگوریتمهای تشخیص ناهنجاری
۱۰.۱ مقایسه با Local Outlier Factor (LOF)
الگوریتم Local Outlier Factor (LOF) ابزار قدرتمندی برای تشخیص ناهنجاریها با ارزیابی چگالی نقاط نسبت به همسایههایشان است که برخلاف روشهای سنتی تشخیص ناهنجاری، نیازی به فرض توزیع خاص داده ندارد.
from sklearn.neighbors import LocalOutlierFactor
from sklearn.svm import OneClassSVM
from sklearn.covariance import EllipticEnvelope
def compare_anomaly_detectors(X, y_true):
"""
مقایسه الگوریتمهای مختلف تشخیص ناهنجاری
"""
results = {}
# Isolation Forest
if_model = IsolationForest(contamination=0.1, random_state=42)
if_model.fit(X)
if_pred = if_model.predict(X)
results['Isolation Forest'] = evaluate_model(y_true, if_pred)
# Local Outlier Factor
lof_model = LocalOutlierFactor(contamination=0.1, novelty=False)
lof_pred = lof_model.fit_predict(X)
results['LOF'] = evaluate_model(y_true, lof_pred)
# One-Class SVM
ocsvm_model = OneClassSVM(nu=0.1, gamma='auto')
ocsvm_model.fit(X)
ocsvm_pred = ocsvm_model.predict(X)
results['One-Class SVM'] = evaluate_model(y_true, ocsvm_pred)
# Elliptic Envelope
ee_model = EllipticEnvelope(contamination=0.1, random_state=42)
ee_model.fit(X)
ee_pred = ee_model.predict(X)
results['Elliptic Envelope'] = evaluate_model(y_true, ee_pred)
return results
def evaluate_model(y_true, y_pred):
"""
محاسبه معیارهای ارزیابی
"""
# تبدیل -1 به 1 برای ناهنجاریها
y_pred_binary = (y_pred == -1).astype(int)
return {
'accuracy': accuracy_score(y_true, y_pred_binary),
'precision': precision_score(y_true, y_pred_binary),
'recall': recall_score(y_true, y_pred_binary),
'f1': f1_score(y_true, y_pred_binary)
}
۱۰.۲ جدول مقایسه عملکرد
| الگوریتم | پیچیدگی زمانی | پیچیدگی حافظه | مقیاسپذیری | دقت در ابعاد بالا |
|---|---|---|---|---|
| Isolation Forest | O(n log n) | O(n) | عالی | خوب |
| LOF | O(n²) | O(n) | ضعیف | متوسط |
| One-Class SVM | O(n³) | O(n²) | ضعیف | خوب |
| DBSCAN | O(n log n) | O(n) | خوب | ضعیف |
۱۱. بهترین شیوهها (Best Practices)
۱۱.۱ آمادهسازی داده
- نرمالسازی: استفاده از StandardScaler یا RobustScaler برای نرمالسازی ویژگیها
- مدیریت دادههای گمشده: پر کردن یا حذف دادههای گمشده قبل از آموزش
- انتخاب ویژگی: حذف ویژگیهای نامربوط یا بسیار همبسته
۱۱.۲ تنظیم مدل
class OptimizedIsolationForest:
"""
کلاس بهینهسازی شده برای Isolation Forest
"""
def __init__(self):
self.model = None
self.scaler = StandardScaler()
self.best_params = None
def auto_tune(self, X, validation_method='cv'):
"""
تنظیم خودکار پارامترها
"""
from sklearn.model_selection import cross_val_score
param_combinations = [
{'n_estimators': 100, 'max_samples': 256, 'contamination': 0.05},
{'n_estimators': 150, 'max_samples': 512, 'contamination': 0.1},
{'n_estimators': 200, 'max_samples': 'auto', 'contamination': 0.15}
]
best_score = -np.inf
for params in param_combinations:
model = IsolationForest(**params, random_state=42)
if validation_method == 'cv':
scores = cross_val_score(model, X, cv=3,
scoring='neg_mean_squared_error')
score = np.mean(scores)
else:
# استفاده از روشهای دیگر
score = self._custom_validation(model, X)
if score > best_score:
best_score = score
self.best_params = params
print(f"بهترین پارامترها: {self.best_params}")
return self
def fit(self, X):
"""
آموزش مدل با پارامترهای بهینه
"""
X_scaled = self.scaler.fit_transform(X)
if self.best_params is None:
self.auto_tune(X_scaled)
self.model = IsolationForest(**self.best_params, random_state=42)
self.model.fit(X_scaled)
return self
def predict(self, X):
"""
پیشبینی با پیشپردازش
"""
X_scaled = self.scaler.transform(X)
return self.model.predict(X_scaled)
۱۱.۳ ارزیابی و اعتبارسنجی
def robust_evaluation(model, X, n_iterations=10):
"""
ارزیابی مقاوم با تکرار چندباره
"""
scores = []
for i in range(n_iterations):
# نمونهبرداری تصادفی
sample_idx = np.random.choice(len(X), size=len(X), replace=True)
X_sample = X[sample_idx]
# آموزش و ارزیابی
temp_model = IsolationForest(
n_estimators=model.n_estimators,
contamination=model.contamination,
random_state=i
)
temp_model.fit(X_sample)
# محاسبه امتیاز
score = temp_model.score_samples(X)
scores.append(score)
# محاسبه میانگین و انحراف معیار
mean_scores = np.mean(scores, axis=0)
std_scores = np.std(scores, axis=0)
return mean_scores, std_scores
۱۲. مطالعه موردی: تشخیص ناهنجاری در دادههای IoT
۱۲.۱ توصیف مسئله
در این مطالعه موردی، از Isolation Forest برای تشخیص رفتار غیرعادی در سنسورهای IoT استفاده میکنیم. دادهها شامل قرائتهای دما، رطوبت، فشار و مصرف انرژی از ۱۰۰۰ سنسور در یک کارخانه صنعتی هستند.
۱۲.۲ پیادهسازی کامل
import pandas as pd
import numpy as np
from datetime import datetime, timedelta
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import IsolationForest
import warnings
warnings.filterwarnings('ignore')
class IoTAnomalyDetector:
"""
سیستم تشخیص ناهنجاری برای دادههای IoT
"""
def __init__(self, window_size=100, contamination=0.01):
self.window_size = window_size
self.contamination = contamination
self.model = None
self.scaler = StandardScaler()
self.feature_columns = None
def extract_features(self, df):
"""
استخراج ویژگیهای آماری از پنجرههای زمانی
"""
features = []
for col in ['temperature', 'humidity', 'pressure', 'energy']:
if col in df.columns:
# ویژگیهای آماری پایه
features.append(df[col].mean())
features.append(df[col].std())
features.append(df[col].min())
features.append(df[col].max())
# ویژگیهای پیشرفته
features.append(df[col].quantile(0.25))
features.append(df[col].quantile(0.75))
features.append(df[col].skew())
features.append(df[col].kurtosis())
# تغییرات
if len(df) > 1:
features.append(df[col].diff().mean())
features.append(df[col].diff().std())
else:
features.extend([0, 0])
return np.array(features)
def prepare_data(self, raw_data):
"""
آمادهسازی دادهها برای آموزش
"""
feature_matrix = []
timestamps = []
# ایجاد پنجرههای لغزان
for i in range(len(raw_data) - self.window_size + 1):
window = raw_data.iloc[i:i+self.window_size]
features = self.extract_features(window)
feature_matrix.append(features)
timestamps.append(window.iloc[-1]['timestamp'])
return np.array(feature_matrix), timestamps
def train(self, training_data):
"""
آموزش مدل تشخیص ناهنجاری
"""
# آمادهسازی دادهها
X, _ = self.prepare_data(training_data)
# نرمالسازی
X_scaled = self.scaler.fit_transform(X)
# آموزش مدل
self.model = IsolationForest(
n_estimators=200,
max_samples=min(256, len(X)),
contamination=self.contamination,
max_features=1.0,
bootstrap=False,
n_jobs=-1,
random_state=42
)
self.model.fit(X_scaled)
print(f"مدل با {len(X)} نمونه آموزش داده شد")
return self
def detect_anomalies(self, test_data):
"""
تشخیص ناهنجاریها در دادههای جدید
"""
# آمادهسازی دادهها
X, timestamps = self.prepare_data(test_data)
# نرمالسازی
X_scaled = self.scaler.transform(X)
# پیشبینی
predictions = self.model.predict(X_scaled)
anomaly_scores = self.model.score_samples(X_scaled)
# ایجاد دیتافریم نتایج
results = pd.DataFrame({
'timestamp': timestamps,
'is_anomaly': predictions == -1,
'anomaly_score': anomaly_scores
})
return results
def generate_alert(self, anomalies_df):
"""
تولید هشدار برای ناهنجاریهای شناسایی شده
"""
alerts = []
for idx, row in anomalies_df[anomalies_df['is_anomaly']].iterrows():
alert = {
'timestamp': row['timestamp'],
'severity': self._calculate_severity(row['anomaly_score']),
'score': row['anomaly_score'],
'action_required': self._determine_action(row['anomaly_score'])
}
alerts.append(alert)
return pd.DataFrame(alerts)
def _calculate_severity(self, score):
"""
محاسبه شدت ناهنجاری
"""
if score < -0.5:
return 'بحرانی'
elif score < -0.3:
return 'بالا'
elif score < -0.1:
return 'متوسط'
else:
return 'پایین'
def _determine_action(self, score):
"""
تعیین اقدام مورد نیاز
"""
if score < -0.5:
return 'بررسی فوری و توقف احتمالی سیستم'
elif score < -0.3:
return 'بررسی در اسرع وقت'
elif score < -0.1:
return 'پایش دقیقتر'
else:
return 'ثبت در گزارش'
# شبیهسازی دادههای IoT
def generate_iot_data(n_samples=10000, anomaly_rate=0.01):
"""
تولید دادههای شبیهسازی شده IoT
"""
np.random.seed(42)
# دادههای نرمال
normal_samples = int(n_samples * (1 - anomaly_rate))
normal_data = {
'timestamp': pd.date_range(start='2024-01-01',
periods=normal_samples,
freq='1min'),
'temperature': np.random.normal(25, 2, normal_samples),
'humidity': np.random.normal(60, 5, normal_samples),
'pressure': np.random.normal(1013, 10, normal_samples),
'energy': np.random.normal(100, 15, normal_samples)
}
# دادههای ناهنجار
anomaly_samples = n_samples - normal_samples
anomaly_data = {
'timestamp': pd.date_range(start='2024-01-01',
periods=anomaly_samples,
freq='1min'),
'temperature': np.random.choice([
np.random.normal(40, 2, anomaly_samples//4), # دمای بالا
np.random.normal(10, 2, anomaly_samples//4), # دمای پایین
np.random.normal(25, 10, anomaly_samples//4), # نوسان زیاد
np.random.normal(25, 0.1, anomaly_samples//4) # نوسان کم
]).flatten()[:anomaly_samples],
'humidity': np.random.uniform(10, 95, anomaly_samples),
'pressure': np.random.choice([
np.random.normal(1050, 5, anomaly_samples//2),
np.random.normal(980, 5, anomaly_samples//2)
]).flatten()[:anomaly_samples],
'energy': np.random.exponential(200, anomaly_samples)
}
# ترکیب دادهها
df_normal = pd.DataFrame(normal_data)
df_normal['is_true_anomaly'] = 0
df_anomaly = pd.DataFrame(anomaly_data)
df_anomaly['is_true_anomaly'] = 1
# ترکیب و مخلوط کردن
df_combined = pd.concat([df_normal, df_anomaly]).sample(frac=1).reset_index(drop=True)
return df_combined
# اجرای مطالعه موردی
if __name__ == "__main__":
# تولید داده
print("تولید دادههای شبیهسازی شده IoT...")
iot_data = generate_iot_data(n_samples=10000, anomaly_rate=0.01)
# تقسیم داده به آموزش و آزمون
train_size = int(0.7 * len(iot_data))
train_data = iot_data[:train_size]
test_data = iot_data[train_size:]
# ایجاد و آموزش مدل
print("\nآموزش مدل تشخیص ناهنجاری...")
detector = IoTAnomalyDetector(window_size=100, contamination=0.01)
detector.train(train_data)
# تشخیص ناهنجاریها
print("\nتشخیص ناهنجاریها در دادههای آزمون...")
results = detector.detect_anomalies(test_data)
# تولید هشدارها
alerts = detector.generate_alert(results)
# نمایش نتایج
print(f"\nتعداد کل ناهنجاریهای شناسایی شده: {results['is_anomaly'].sum()}")
print(f"نرخ ناهنجاری: {results['is_anomaly'].mean():.2%}")
if len(alerts) > 0:
print("\nهشدارهای بحرانی:")
critical_alerts = alerts[alerts['severity'] == 'بحرانی']
print(critical_alerts.head())
# ارزیابی عملکرد
if 'is_true_anomaly' in test_data.columns:
# محاسبه معیارهای ارزیابی
window_size = detector.window_size
true_labels = test_data['is_true_anomaly'].iloc[window_size-1:].values
if len(true_labels) == len(results):
from sklearn.metrics import classification_report
print("\n" + "="*50)
print("گزارش ارزیابی مدل:")
print("="*50)
print(classification_report(
true_labels,
results['is_anomaly'].astype(int),
target_names=['نرمال', 'ناهنجاری']
))
۱۳. نتیجهگیری
الگوریتم Isolation Forest یکی از موثرترین و کارآمدترین روشهای تشخیص ناهنجاری بدون نظارت است که با پیچیدگی زمانی خطی O(n*logn) برای مجموعه دادههای بزرگ کارآمد بوده و ماهیت بدون نظارت آن، مدل را برای تشخیص ناهنجاری در حوزههای مختلف مناسب میسازد. این الگوریتم با رویکرد منحصر به فرد خود در جداسازی مستقیم ناهنجاریها، توانسته است در کاربردهای متنوعی از جمله تشخیص تقلب، امنیت سایبری، و پایش سیستمهای صنعتی نتایج قابل توجهی ارائه دهد.
نکات کلیدی:
- انتخاب پارامترها: تنظیم صحیح contamination برای اعتماد به پیشبینیهای الگوریتم تشخیص ناهنجاری چندمتغیره حیاتی است و معمولاً بر اساس انتظارات کسبوکار یا تحلیل آماری تعیین میشود.
- Extended Isolation Forest: نسخه توسعهیافته با استفاده از ابرصفحههای با شیب تصادفی، مشکلات تخصیص امتیاز ناهنجاری را حل کرده و آرتیفکتهای دیده شده در نقشههای امتیاز را برطرف میکند.
- کاربردهای عملی: الگوریتم در شناسایی انواع مختلف ناهنجاریها موفق عمل میکند، از ناهنجاریهای نقطهای گرفته تا ناهنجاریهای زمینهای و جمعی.
توصیههای عملی:
- برای دادههای با ابعاد بالا، استفاده از تعداد درخت بیشتر (n_estimators > 100)
- در صورت عدم اطلاع از نسبت ناهنجاری، شروع با contamination=’auto’
- استفاده از تکنیکهای ensemble برای بهبود پایداری نتایج
- پیشپردازش مناسب دادهها با نرمالسازی و مدیریت دادههای گمشده
با توجه به پیشرفتهای اخیر در حوزه یادگیری ماشین و افزایش حجم دادهها، الگوریتم Isolation Forest و نسخههای بهبودیافته آن همچنان به عنوان ابزارهای قدرتمند در جعبهابزار دانشمندان داده باقی خواهند ماند.
۱۴. منابع و مراجع
منابع اصلی:
- Liu, F. T., Ting, K. M., & Zhou, Z. H. (2008). الگوریتم Isolation Forest برای تشخیص ناهنجاریها در داده با استفاده از درختهای باینری توسعه داده شد و دارای پیچیدگی زمانی خطی و استفاده کم از حافظه است که برای دادههای حجیم مناسب میباشد.
- Liu, F. T., Ting, K. M., & Zhou, Z. H. (2012). تشخیص ناهنجاری مبتنی بر جداسازی. ACM Transactions on Knowledge Discovery from Data (TKDD), 6(1), 3.
- Hariri, S., Carrasco Kind, M., & Brunner, R. J. (2019). Extended Isolation Forest الگوریتمی که مشکلات تخصیص امتیاز ناهنجاری به نقاط داده را حل میکند و با استفاده از ابرصفحههای با شیب تصادفی، آرتیفکتهای ایجاد شده توسط عملیات شاخهبندی درخت باینری را برطرف مینماید.
تکمیلی:
- الگوریتم Isolation Forest به عنوان یک روش تشخیص ناهنجاری بدون نظارت، به ویژه برای دادههای با ابعاد بالا موثر است و بر این اصل عمل میکند که ناهنجاریها نادر و متمایز هستند، که آنها را آسانتر از بقیه دادهها برای جداسازی میکند.
- Isolation Forest میتواند با دادههای با ابعاد بالا کار کند و مزیت کلیدی دیگر این است که میتواند انواع مختلف ناهنجاری را پیدا کند، برخلاف روشهای سادهتر که فقط بر اساس فاصله از میانگین عمل میکنند.
- الگوریتم Isolation Forest که توسط Fei Tony Liu و Zhi-Hua Zhou در سال ۲۰۰۸ معرفی شد، از میان روشهای تشخیص ناهنجاری برجسته است و از درختهای تصمیم برای جداسازی کارآمد ناهنجاریها با انتخاب تصادفی ویژگیها و تقسیم دادهها بر اساس مقادیر آستانه استفاده میکند.
فارسی:
- در سال ۲۰۱۰ افزونهای از این الگوریتم به نام SCiforest با تمرکز بر بررسی مباحث ناهنجاریهای خوشهای و به کارگیری از اَبرصفحههای تصادفی به منظور افزایش توانایی تشخیص ناهنجاریهای موازی منتشر شد.
- الگوریتم جنگل ایزوله یک الگوریتم یادگیری بدون نظارت برای تشخیص ناهنجاری است که برای جداسازی نقاط پرت به کار میرود و براساس این الگوریتم، تشخیص موارد غیر عادی و ناهنجار در مجموعه داده انجام میشود که آسانتر از پیدا یا جداسازی دادههای نرمال است.
- الگوریتم اولین بار در سال 2008 توسط فی تونی لیو و ژی هوا ژو توسعه داده شد و دارای پیچیدگی زمانی از مرتبه خطی و نیاز به حافظه کم است که این الگوریتم را برای اجرا روی دادگان حجیم مناسب میسازد.
کتابخانهها و ابزارهای پیادهسازی:
- Scikit-learn: پیادهسازی IsolationForest در scikit-learn بر اساس مجموعهای از ExtraTreeRegressor است که حداکثر عمق هر درخت به ceil(log_2(n)) تنظیم میشود که n تعداد نمونههای استفاده شده برای ساخت درخت است.
- PyOD: کتابخانه Python Outlier Detection که شامل پیادهسازی بهینهشده Isolation Forest است
- H2O.ai: پیادهسازی Extended Isolation Forest در H2O که با تنظیم پارامتر extension_level میتواند از Isolation Forest استاندارد (مقدار 0) تا نسخه کاملاً توسعهیافته (مقدار P-1 که P تعداد ویژگیهاست) عمل کند.
پیوست: کد کامل پیادهسازی از ابتدا
برای درک عمیقتر الگوریتم، در اینجا پیادهسازی سادهای از Isolation Forest از ابتدا ارائه میشود:
import numpy as np
from typing import List, Tuple, Optional
class IsolationTree:
"""
پیادهسازی درخت ایزوله
"""
def __init__(self, max_depth: int = 10):
self.max_depth = max_depth
self.root = None
self.n_nodes = 0
class Node:
"""
گره درخت ایزوله
"""
def __init__(self, depth: int = 0):
self.depth = depth
self.left = None
self.right = None
self.split_feature = None
self.split_value = None
self.is_leaf = False
self.size = 0
def fit(self, X: np.ndarray) -> 'IsolationTree':
"""
ساخت درخت ایزوله
"""
self.root = self._build_tree(X, depth=0)
return self
def _build_tree(self, X: np.ndarray, depth: int) -> Node:
"""
ساخت بازگشتی درخت
"""
n_samples, n_features = X.shape
node = self.Node(depth=depth)
self.n_nodes += 1
# شرط توقف
if depth >= self.max_depth or n_samples <= 1:
node.is_leaf = True
node.size = n_samples
return node
# انتخاب تصادفی ویژگی و مقدار تقسیم
feature = np.random.randint(0, n_features)
min_val = X[:, feature].min()
max_val = X[:, feature].max()
if min_val == max_val:
node.is_leaf = True
node.size = n_samples
return node
split_value = np.random.uniform(min_val, max_val)
# تقسیم دادهها
left_mask = X[:, feature] < split_value
right_mask = ~left_mask
node.split_feature = feature
node.split_value = split_value
# ساخت زیردرختها
if np.any(left_mask):
node.left = self._build_tree(X[left_mask], depth + 1)
if np.any(right_mask):
node.right = self._build_tree(X[right_mask], depth + 1)
return node
def path_length(self, x: np.ndarray) -> float:
"""
محاسبه طول مسیر برای یک نمونه
"""
return self._path_length(x, self.root)
def _path_length(self, x: np.ndarray, node: Node) -> float:
"""
محاسبه بازگشتی طول مسیر
"""
if node.is_leaf:
# استفاده از تخمین برای گرههای برگ با بیش از یک نمونه
return node.depth + self._c(node.size)
if x[node.split_feature] < node.split_value:
if node.left is not None:
return self._path_length(x, node.left)
else:
return node.depth + 1
else:
if node.right is not None:
return self._path_length(x, node.right)
else:
return node.depth + 1
@staticmethod
def _c(n: int) -> float:
"""
محاسبه میانگین طول مسیر در BST
"""
if n <= 1:
return 0
if n == 2:
return 1
# فرمول تخمین
H = np.log(n - 1) + 0.5772156649 # ثابت اویلر
return 2 * H - (2 * (n - 1) / n)
class SimpleIsolationForest:
"""
پیادهسازی ساده Isolation Forest
"""
def __init__(self,
n_trees: int = 100,
sample_size: int = 256,
max_depth: Optional[int] = None):
self.n_trees = n_trees
self.sample_size = sample_size
self.max_depth = max_depth
self.trees: List[IsolationTree] = []
self.threshold = None
def fit(self, X: np.ndarray) -> 'SimpleIsolationForest':
"""
آموزش جنگل ایزوله
"""
n_samples = X.shape[0]
if self.max_depth is None:
self.max_depth = int(np.ceil(np.log2(self.sample_size)))
# ساخت درختها
for _ in range(self.n_trees):
# نمونهبرداری تصادفی
sample_idx = np.random.choice(
n_samples,
size=min(self.sample_size, n_samples),
replace=False
)
X_sample = X[sample_idx]
# ساخت و آموزش درخت
tree = IsolationTree(max_depth=self.max_depth)
tree.fit(X_sample)
self.trees.append(tree)
# محاسبه آستانه
scores = self.anomaly_score(X)
self.threshold = np.percentile(scores, 90) # 10% ناهنجاری
return self
def anomaly_score(self, X: np.ndarray) -> np.ndarray:
"""
محاسبه امتیاز ناهنجاری
"""
n_samples = X.shape[0]
scores = np.zeros(n_samples)
for i in range(n_samples):
path_lengths = []
for tree in self.trees:
path_length = tree.path_length(X[i])
path_lengths.append(path_length)
# محاسبه میانگین طول مسیر
avg_path_length = np.mean(path_lengths)
# محاسبه امتیاز ناهنجاری
c_n = IsolationTree._c(self.sample_size)
if c_n > 0:
scores[i] = 2 ** (-avg_path_length / c_n)
else:
scores[i] = 1
return scores
def predict(self, X: np.ndarray) -> np.ndarray:
"""
پیشبینی ناهنجاریها
"""
scores = self.anomaly_score(X)
predictions = np.ones(len(scores))
predictions[scores > self.threshold] = -1 # ناهنجاری
return predictions
def fit_predict(self, X: np.ndarray) -> np.ndarray:
"""
آموزش و پیشبینی همزمان
"""
self.fit(X)
return self.predict(X)
# تست پیادهسازی
if __name__ == "__main__":
# تولید دادههای تست
np.random.seed(42)
# دادههای نرمال
X_normal = np.random.randn(950, 2)
# دادههای ناهنجار
X_anomaly = np.random.randn(50, 2) + 5
# ترکیب دادهها
X = np.vstack([X_normal, X_anomaly])
y_true = np.hstack([np.zeros(950), np.ones(50)])
# آموزش مدل
model = SimpleIsolationForest(n_trees=100, sample_size=256)
model.fit(X)
# پیشبینی
predictions = model.predict(X)
anomaly_scores = model.anomaly_score(X)
# ارزیابی
from sklearn.metrics import accuracy_score, precision_score, recall_score
y_pred = (predictions == -1).astype(int)
print("نتایج پیادهسازی ساده Isolation Forest:")
print(f"دقت: {accuracy_score(y_true, y_pred):.3f}")
print(f"صحت: {precision_score(y_true, y_pred):.3f}")
print(f"بازخوانی: {recall_score(y_true, y_pred):.3f}")
# مقایسه با scikit-learn
from sklearn.ensemble import IsolationForest
sklearn_model = IsolationForest(
n_estimators=100,
max_samples=256,
contamination=0.05,
random_state=42
)
sklearn_model.fit(X)
sklearn_pred = (sklearn_model.predict(X) == -1).astype(int)
print("\nنتایج scikit-learn:")
print(f"دقت: {accuracy_score(y_true, sklearn_pred):.3f}")
print(f"صحت: {precision_score(y_true, sklearn_pred):.3f}")
print(f"بازخوانی: {recall_score(y_true, sklearn_pred):.3f}")
پیوست B: راهنمای عیبیابی
مشکلات رایج و راهحلها:
- دقت پایین در تشخیص ناهنجاری
- بررسی و تنظیم پارامتر contamination
- افزایش تعداد درختها (n_estimators)
- استفاده از Extended Isolation Forest
- زمان اجرای طولانی
- کاهش max_samples
- استفاده از n_jobs=-1 برای پردازش موازی
- کاهش n_estimators در صورت امکان
- حافظه ناکافی
- پیادهسازی پردازش دستهای (batch processing)
- کاهش تعداد ویژگیها با PCA
- استفاده از نمونهبرداری تصادفی
- نتایج ناپایدار
- تنظیم random_state برای تکرارپذیری
- افزایش تعداد درختها
- استفاده از تکنیکهای ensemble