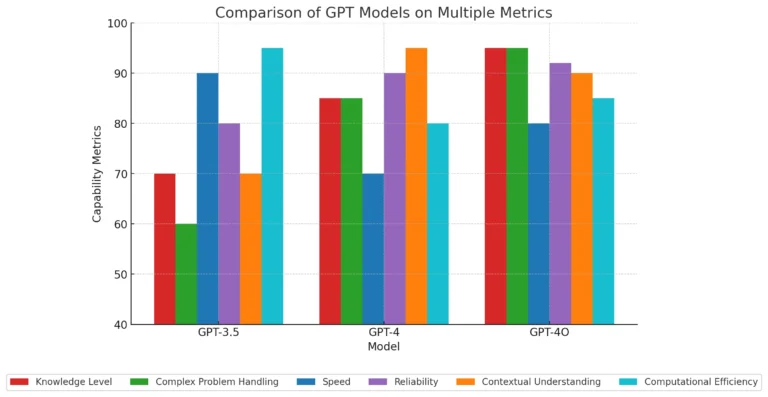
یادگیری تقویتی (Reinforcement Learning) بهعنوان یکی از پیشرفتهترین شاخههای یادگیری ماشین، در سالهای اخیر تحولی عمیق در صنایع مختلف ایجاد کرده است. این مقاله با رویکردی علمی و تحلیلی به بررسی آینده این فناوری در کاربردهای واقعی میپردازد. بر اساس آخرین تحقیقات منتشر شده در سال ۲۰۲۴ و ۲۰۲۵، ارزش بازار یادگیری تقویتی به بیش از ۱۲۲ میلیارد دلار رسیده و پیشبینی میشود تا سال ۲۰۲۹ به ۴۹.۴ میلیارد دلار با نرخ رشد سالانه ۳۴.۵ درصد برسد.
مقدمه
تعریف و مفاهیم بنیادی
یادگیری تقویتی نوعی یادگیری ماشین است که در آن یک عامل (Agent) از طریق تعامل با محیط خود، تصمیمگیری بهینه را میآموزد. برخلاف یادگیری نظارتشده که از دادههای برچسبدار استفاده میکند، یادگیری تقویتی بر اساس آزمون و خطا و دریافت پاداش یا جریمه عمل میکند.
فرآیند یادگیری تقویتی میتواند بهصورت یک فرآیند تصمیمگیری مارکوف (Markov Decision Process – MDP) مدلسازی شود که شامل اجزای زیر است:
- عامل (Agent): الگوریتم یا تابعی که وظیفه مورد نظر را انجام میدهد
- محیط (Environment): دنیایی که عامل در آن فعالیت میکند
- حالت (State): وضعیت فعلی عامل در محیط
- عمل (Action): حرکاتی که عامل برای کسب پاداش انجام میدهد
- پاداش (Reward): بازخوردی که عامل از محیط دریافت میکند
تاریخچه و تکامل
تاریخچه Reinforcement Learning را میتوان به مراحل زیر تقسیم کرد:
- دهه ۱۹۸۰: معرفی Q-learning توسط واتکینز و کارهای ساتون بر روی یادگیری تفاضل زمانی (Temporal Difference)
- دهه ۱۹۹۰-۲۰۰۰: کاربرد یادگیری تقویتی در رباتیک و بازیهای ساده؛ انتشار کتاب معروف «یادگیری تقویتی: مقدمهای» توسط ساتون و بارتو در سال ۱۹۹۸
- ۲۰۱۳-۲۰۱۶: پیشرفتهای انقلابی DeepMind با استفاده از شبکههای عصبی عمیق در بازیهای Atari و AlphaGo
- ۲۰۲۲ تا کنون: کاربرد گسترده در هوش مصنوعی مولد از طریق تکنیک RLHF (Reinforcement Learning from Human Feedback)
- ۲۰۲۴: اعطای جایزه تورینگ به ریچارد ساتون و اندرو بارتو برای کارهای بنیادین در یادگیری تقویتی
جایگاه فعلی در صنعت هوش مصنوعی
بر اساس تحقیقات سال ۲۰۲۵، تخمین زده میشود کمتر از ۵ درصد سیستمهای هوش مصنوعی مستقر در دنیا بر یادگیری تقویتی متکی هستند، درحالیکه اکثریت سیستمهای تجاری همچنان تحت سلطه یادگیری نظارتشده و بدون نظارت قرار دارند. با این حال، سهم یادگیری تقویتی در بخشهایی که نیازمند تصمیمگیری تطبیقی در زمان واقعی هستند، بهسرعت در حال رشد است.
کاربردهای فعلی و آینده در صنایع مختلف
۱. رباتیک و اتوماسیون صنعتی
یادگیری تقویتی ماشینها را قادر میسازد تا عملکرد خود را در محیطهای پویا بهینه کنند. تحقیقات و کاربردهای عملی در حوزههای مختلف رباتیکی گسترش یافتهاند:
کاربردهای فعلی:
- حرکت چهارپا (Quadruped Locomotion): شرکتهایی مانند Swiss-Mile بر روی توسعه رباتهای چهارپا با استفاده از یادگیری تقویتی تمرکز دارند
- ناوبری پهپادها (Drone Navigation): شرکتهایی مثل Shearwater AI و ANDRO Innovation Lab با استفاده از نرمافزارهای پیشرفته مبتنی بر یادگیری تقویتی به ناوبری پهپادها کمک میکنند
- دستکاری اشیاء (Object Manipulation): رباتها با استفاده از یادگیری تقویتی قادر به گرفتن و جابهجایی اشیاء با دقت بالا میشوند
- کارخانههای هوشمند: استفاده از یادگیری تقویتی برای نگهداری پیشبینانه، تشخیص خطا و بهینهسازی گردش کار
چشمانداز آینده:
- توسعه سیستمهای رباتیک چند منظوره که قادر به یادگیری وظایف مختلف بدون برنامهریزی مجدد باشند
- ادغام یادگیری تقویتی با الگوریتمهای تکاملی برای برنامهریزی مسیر در محیطهای پیچیده
- رباتهای جراحی که با استفاده از یادگیری تقویتی قادر به انجام عملیاتهای پیچیدهتر با دقت بالاتر خواهند بود
۲. خودروهای خودران و حملونقل
خودروهای خودران یکی از مهمترین کاربردهای یادگیری تقویتی در آینده نزدیک هستند.
وضعیت فعلی:
خودروهای خودران از یادگیری تقویتی برای یادگیری و بهبود استراتژیهای رانندگی استفاده میکنند. با شبیهسازی میلیونها مایل رانندگی مجازی، مدلهای یادگیری تقویتی به خودروها کمک میکنند تا پاسخ مناسب به شرایط متنوع جاده، رفتارهای ترافیکی و رویدادهای غیرمنتظره را یاد بگیرند. شرکتهایی مانند Waymo، Tesla و Uber برای عملکردهایی مثل نگهداشتن در خط، ترمزگیری و اجتناب از موانع به یادگیری تقویتی تکیه میکنند.
چالشها و محدودیتها:
یادگیری ناوبری (بهویژه اجتناب از برخورد) برای سیستمهای حیاتی مانند خودروهای خودران شهری و پهپادها به دلیل نیازهای سختگیرانه استحکام در ادراک و کنترل، چالشبرانگیز است. این حوزهها در نتیجه، موفقیتهای کمتری در دنیای واقعی داشتهاند.
آینده پیشرو:
- توسعه معماریهای مدولار که یادگیری تقویتی برای برنامهریزی محلی یا اکتشاف معنایی ادغام شود
- استدلال مشترک درباره ناوبری و حرکت که ناوبری چابک پا و هوایی را امکانپذیر میکند
- بهبود ایمنی و کارایی سیستمهای حملونقل با استفاده از الگوریتمهای یادگیری تقویتی پیشرفته
۳. مراقبتهای بهداشتی و پزشکی
یادگیری تقویتی پتانسیل انقلابی در حوزه سلامت دارد.
کاربردهای پزشکی:
- برنامههای درمانی شخصیسازی شده: ارائهدهندگان مراقبتهای بهداشتی بهطور فزایندهای به یادگیری تقویتی برای توسعه برنامههای درمانی شخصیسازی شده روی میآورند. یادگیری تقویتی میتواند دادههای گسترده بیماران را تحلیل کند تا دوزهای دارویی، فواصل درمان و پاسخهای درمانی را تنظیم کند، بهویژه در انکولوژی، مدیریت دیابت و سلامت روان
- رژیمهای درمانی پویا (DTR): یادگیری تقویتی در مراقبتهای بهداشتی توسعه رژیمهای درمانی پویا (DTR) برای بیماریهای مزمن را امکانپذیر میسازد که به ارائهدهندگان اجازه میدهد مداخلات تطبیقی و شخصیسازی شده ارائه دهند که نتایج بیمار را بهبود میبخشد
- کشف دارو: یادگیری تقویتی شناسایی ترکیبات مؤثر و پیشبینی پاسخ دارویی را تسریع میکند و در زمان و منابع صرفهجویی میکند
- رباتهای جراحی: استفاده از یادگیری تقویتی در جراحی به کمک ربات که سازگاری و کارایی را از طریق بینایی کامپیوتری و الگوریتمهای یادگیری تقویتی افزایش میدهد، بهویژه در خودکارسازی وظایف جراحی مانند گرهزدن
چالشهای موجود:
- انتقال عامل یادگیری تقویتی از محیط آموزشی یا شبیهسازیشده به دنیای واقعی
- نیاز به دادههای زیاد و با کیفیت برای آموزش مدلها
- ملاحظات اخلاقی و ایمنی در استفاده از سیستمهای یادگیری تقویتی در تصمیمات حیاتی پزشکی
آینده مراقبتهای بهداشتی:
- یادگیری تقویتی میتواند برنامههای درمانی را شخصیسازی کند، اما محققان باید چالشهایی مانند قابلیت مشاهده جزئی (مثلاً دادههای ناقص بیمار) و محدودیتهای اخلاقی را برطرف کنند
- توسعه چارچوب DTR-Bench که ارزیابی استاندارد در زمینههایی مانند دیابت، شیمیدرمانی سرطان و درمان سپسیس را فراهم میکند
۴. هوش مصنوعی مولد و مدلهای زبانی بزرگ
یکی از مهمترین پیشرفتهای اخیر در یادگیری تقویتی، کاربرد آن در بهبود مدلهای زبانی بزرگ (LLM) است.
تکنیک RLHF (Reinforcement Learning from Human Feedback):
RLHF یک روش نقطه عطف است که شکاف بین قابلیتهای خام مدل و پاسخهای همسو با انسان را پر میکند. این رویکرد به توسعهدهندگان اجازه میدهد تا LLMها را با گنجاندن بازخورد انسانی در فرآیند یادگیری تقویتی، تنظیم دقیق کنند.
مراحل RLHF:
- آموزش مقدماتی: استفاده از یک مدل زبانی که قبلاً با اهداف آموزشی کلاسیک پیشآموزش داده شده (مانند GPT-3، Gopher)
- تولید مجموعه داده ترجیحی: ارزیابان انسانی خروجیهای مدل را رتبهبندی میکنند و مجموعه داده ترجیحی ایجاد میشود
- آموزش مدل پاداش: یک مدل پاداش (Reward Model) با استفاده از یادگیری نظارتشده روی مجموعه داده ترجیحی آموزش داده میشود
- بهینهسازی با یادگیری تقویتی: استفاده از الگوریتمهایی مانند PPO (Proximal Policy Optimization) برای تنظیم دقیق مدل زبانی
دستاوردهای سال ۲۰۲۴:
در سال ۲۰۲۴، RLHF به تعداد زیادی از LLMها اعمال شد که مدلها را قادر ساخت تا بافت، تفاوتهای ظریف و ملاحظات اخلاقی را بهتر درک کنند. این منجر به بهبودهای قابل توجهی در هوش مصنوعی مکالمهای، تولید محتوا و سیستمهای تصمیمگیری شد.
تحقیقات برجسته:
- “مدلسازی پاداش تطبیقی برای بافتهای پویا”: روش جدیدی برای تنظیم پویای توابع پاداش بر اساس بافتهای در حال تکامل کاربران
- “RLHF کارآمد با بازخورد کم”: روشی برای کاهش وابستگی به حاشیهنویسیهای انسانی در مقیاس بزرگ
- “یادگیری تقویتی چند عامله برای سیستمهای هوش مصنوعی مشارکتی”: ادغام یادگیری تقویتی در سیستمهای چند عامله
مدلهای استدلال و RLVR:
از اواخر سال ۲۰۲۴، سری مدلهای پیشرفته LLM با استفاده از تکنیکهای یادگیری تقویتی در زمان تست یا پس از آموزش، پیشرفتهای قابل توجهی در وظایف استدلال پیچیده (مانند ریاضیات و برنامهنویسی) نشان دادند:
- OpenAI o1: سیستمی که استراتژیهای استدلال تقویتشده را در استنتاج ادغام میکند
- Anthropic Claude 3.7/4: مدلهای پیشرفته با قابلیتهای استدلال بهبودیافته
- DeepSeek R1: مدلی با عملکرد برجسته در معیارهای ریاضی مانند MATH-500 و AIME 2024
- Kimi K1.5 و Qwen 3: مدلهایی که از یادگیری تقویتی در مرحله استنتاج استفاده میکنند
پارادایم RLVR (Reinforcement Learning with Verifiable Rewards): نوآوری کلیدی که این پیشرفتهای اخیر را پشتیبانی میکند، پارادایم RLVR است که حلقه یادگیری تقویتی استاندارد را با سیگنالهای پاداش عینی و قابل تأیید خودکار تقویت میکند، مانند بررسیهای برنامهنویسی یا اثباتهای صحت در خروجی مدل.
آینده هوش مصنوعی مولد:
- ادغام عمیقتر یادگیری تقویتی با LLMها، رباتیک و پیشآموزش بدون نظارت
- توسعه عوامل عمومی (Generalist Agents) مانند Gato از DeepMind یا عوامل GPT با حافظه و ماژولهای تصمیمگیری
- استفاده گستردهتر از RLAIF (Reinforcement Learning from AI Feedback) بهجای RLHF برای کاهش هزینههای حاشیهنویسی انسانی
۵. امور مالی و تجارت
کاربردهای فعلی:
- پیشبینی بازار سهام و معاملات فرکانس بالا (HFT): اگرچه کارایی و محدودیتهای آن محل بحث است، اکثر راهحلهای فعلی مبتنی بر یادگیری تقویتی بر بهینهسازی معاملات کوتاهمدت تمرکز دارند نه سرمایهگذاری ارزش بلندمدت
- مدیریت پرتفوی و ارزیابی ریسک: شرکتهایی مانند AI Capital Management از یادگیری تقویتی برای HFT استفاده میکنند
- الگوریتمهای معاملاتی: Equilibre Technologies که توسط متخصصان سابق Google DeepMind تأسیس شده، یادگیری تقویتی را با نظریه بازی برای معاملات الگوریتمی ترکیب میکند
- بهینهسازی سرمایهگذاری خطرپذیر: تحقیقات اخیر یک عامل یادگیری تقویتی را معرفی کرده که برای پیشبینی مقادیر سرمایهگذاری در استارتاپها بر اساس عوامل خاص طراحی شده است
چشمانداز آینده:
- ظهور یادگیری تقویتی انسان-در-حلقه (Human-in-the-Loop RL – HRL)
- امنیت سایبری مبتنی بر یادگیری تقویتی با پاسخ پویا به تهدیدات
- همگرایی یادگیری ماشین کوانتومی و یادگیری تقویتی
۶. مدیریت شبکه هوشمند و انرژی
الگوریتمهای یادگیری تقویتی سیستمهای خودمختار را کنترل میکنند و توزیع انرژی را بهصورت پویا بهینه میکنند. آنها تقاضا، قیمتها و شرایط محیطی را در زمان واقعی نظارت میکنند و تولید، ذخیرهسازی و عرضه انرژی را بهصورت پویا تنظیم میکنند.
مزایای اکولوژیکی: مدیریت شبکه هوشمند صدیق با محیط زیست، شیوههای انرژی پایدارتر را امکانپذیر میکند و به مبارزه با تغییرات اقلیمی کمک میکند.
۷. دفاع و امنیت
یادگیری تقویتی بهطور فزایندهای در حوزه دفاع برای خودکارسازی وظایف حیاتی و پرخطر اعمال میشود که وابستگی به پرسنل را کاهش میدهد. بهعنوان مثال، Shield AI هدف توسعه سیستم “Hivemind” را دارد که وسایل نقلیه هوایی را قادر میسازد بدون GPS، ارتباطات یا خلبانان بهصورت خودمختار عمل کنند.
۸. تحقیق و توسعه هوش مصنوعی
در زمینه تحقیق و توسعه هوش مصنوعی، یادگیری تقویتی بهطور گسترده برای بهبود عملکرد نرمافزار در زمینههای مختلف استفاده میشود:
- مدل AIR (Automated Interpretable Reasoning): ترکیب یادگیری تقویتی، LLMها و مدلهای دنیا برای خودکارسازی و بهبود توسعه نمونه اولیه، بهویژه در سختافزار نیمههادی
- RLCEF (Reinforcement Learning from Code Execution Feedback): Poolside در حال توسعه مدلهای هوش مصنوعی پیشرفته برای مهندسی نرمافزار است که از رویکرد جدید RLCEF برای بهبود تولید کد و قابلیتهای استدلال استفاده میکند
چالشهای فعلی و موانع پیش رو
۱. کارایی نمونه و نیاز به داده
یکی از اصلیترین چالشها، نیاز به تعداد زیاد تعاملات با محیط برای یادگیری سیاستهای مؤثر است. این امر در حوزههایی که جمعآوری داده گران یا زمانبر است، مشکلات جدی ایجاد میکند.
راهحلهای پیشنهادی:
- یادگیری فرا (Meta-Learning): آموزش عوامل برای سازگاری سریع با وظایف جدید
- رویکردهای ترکیبی مبتنی بر مدل: ترکیب برنامهریزی مبتنی بر مدل با یادگیری تقویتی بدون مدل
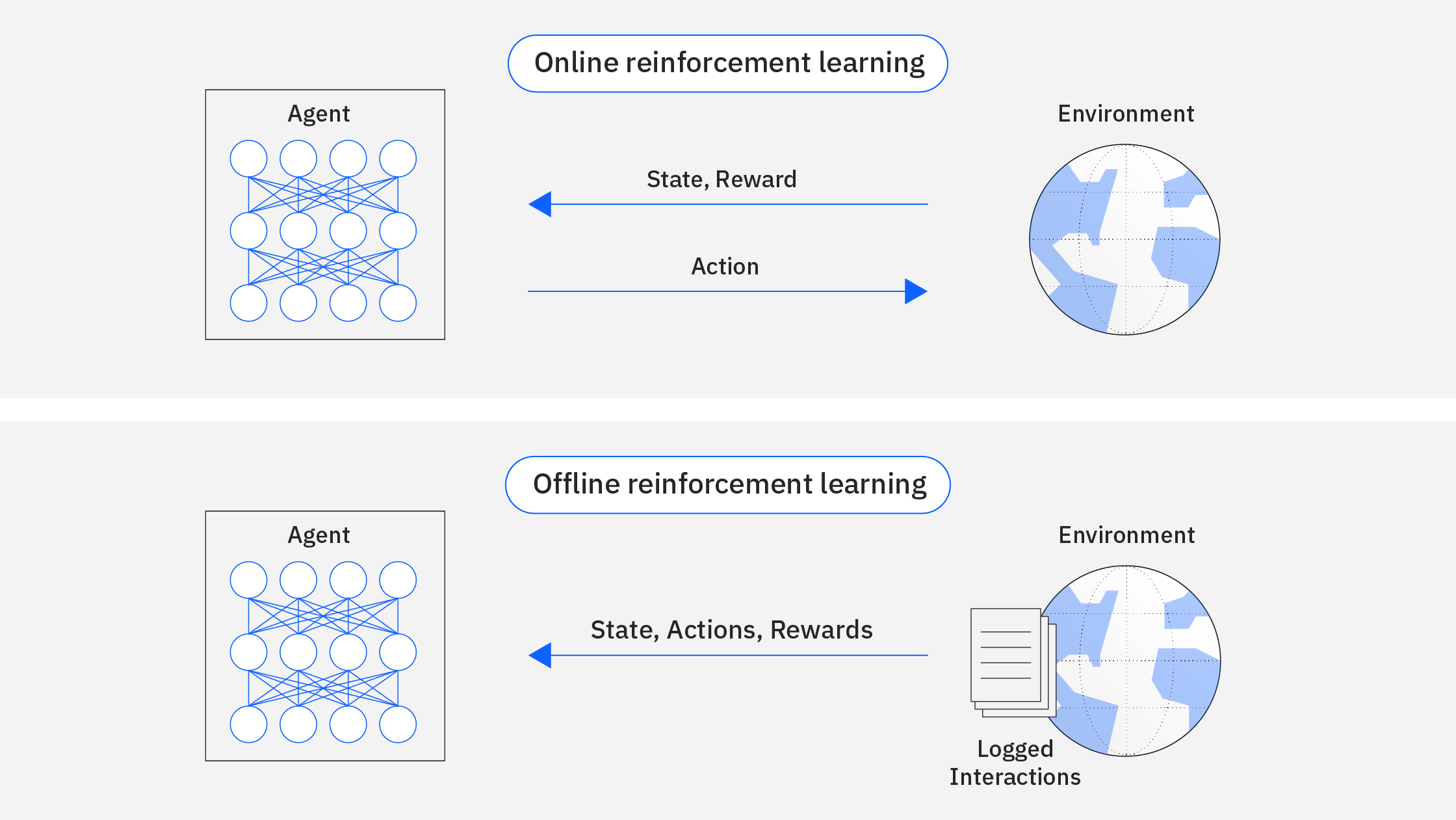
- یادگیری تقویتی آفلاین (Offline RL): عوامل از مجموعه دادههای از پیش جمعآوری شده بهجای تعاملات زنده یاد میگیرند
۲. طراحی تابع پاداش (Reward Shaping)
طراحی تابع پاداش مناسب یکی از پیچیدهترین جنبههای یادگیری تقویتی است. تابع پاداش ضعیف میتواند منجر به رفتار نامطلوب ربات یا تقلب در انجام وظیفه شود.
چالشهای مرتبط:
- اطمینان از اینکه پاداشها رفتارهای مطلوب را تشویق میکنند
- در نظر گرفتن عمیق اهداف و عوارض جانبی
- نیاز به بررسی مکرر و تنظیم پاداشها توسط متخصصان
۳. مصالحه بین اکتشاف و بهرهبرداری
یافتن تعادل مناسب بین تجزیه و تحلیل راههای جدید (اکتشاف) و استفاده از کانالهای شناختهشده (بهرهبرداری) یک چالش کلیدی است، بهویژه در برنامههای حیاتی-ایمنی.
۴. ایمنی و محدودیتهای دنیای واقعی
اطمینان از اینکه سیستمهای آموزشدیده خودمختار بهطور ایمن و اخلاقی رفتار میکنند، یک نگرانی قابل توجه برای یادگیری تقویتی است. ملاحظه دقیق خطرات بالقوه و سوگیریها ضروری است.
۵. قابلیت تفسیر و شفافیت
یکی از نگرانیهای اصلی در استفاده از یادگیری تقویتی در کاربردهای حیاتی، عدم شفافیت در فرآیند تصمیمگیری است. شبکههای عصبی عمیق که اغلب در یادگیری تقویتی مدرن استفاده میشوند، بهعنوان جعبههای سیاه عمل میکنند.
راهکارهای در حال توسعه:
- استفاده از روشهای توضیحپذیر هوش مصنوعی (XAI)
- توسعه معماریهای شفافتر مانند درختهای تصمیم
- ترکیب قوانین منطقی با یادگیری تقویتی
۶. عدم تعمیمپذیری
مدلهای یادگیری تقویتی اغلب در محیطهای جدید که با محیط آموزشی تفاوت دارند، عملکرد ضعیفی دارند. این مسئله بهویژه در رباتیک و خودروهای خودران چالشساز است.
رویکردهای پیشنهادی:
- آموزش در محیطهای شبیهسازی متنوع
- استفاده از تکنیکهای Domain Randomization
- یادگیری انتقالی (Transfer Learning)
۷. محاسبات و منابع
آموزش مدلهای یادگیری تقویتی پیشرفته نیازمند منابع محاسباتی عظیم است. این امر مانعی برای محققان و شرکتهای کوچک ایجاد میکند.
پیشرفتهای اخیر و فناوریهای نوظهور
۱. یادگیری تقویتی چند عامله (Multi-Agent RL)
یادگیری تقویتی چند عامله به سیستمهایی اشاره دارد که چندین عامل بهطور همزمان در یک محیط یاد میگیرند و تعامل دارند.
کاربردها:
- سیستمهای ترافیک هوشمند
- بازیهای استراتژیک
- کنترل شبکههای انرژی توزیعشده
- همکاری رباتیک
پیشرفتهای اخیر: شرکتهایی مانند Sakana AI و Lux AI در حال پیشبرد محدوده تحقیقاتی یادگیری تقویتی چند عامله هستند و فرآیندهای تحقیق و توسعه سیستماتیک را با هوش مصنوعی مولد ترکیب میکنند.
۲. یادگیری تقویتی سلسلهمراتبی (Hierarchical RL)
این رویکرد وظایف پیچیده را به زیروظایف کوچکتر تقسیم میکند و امکان یادگیری کارآمدتر و انتقال بهتر دانش را فراهم میآورد.
مزایا:
- کاهش پیچیدگی مسائل
- بهبود قابلیت تفسیر
- امکان یادگیری سریعتر
۳. یادگیری تقویتی ایمن (Safe RL)
با توجه به افزایش استفاده از Reinforcement Learning در سیستمهای حیاتی، تحقیقات گستردهای بر روی توسعه الگوریتمهای ایمن صورت میگیرد.
رویکردها:
- استفاده از محدودیتهای ایمنی در فرآیند یادگیری
- آموزش با راهنمای انسانی (Human-Guided Learning)
- استفاده از مدلهای ریسکگریز
۴. یادگیری تقویتی مبتنی بر مدل (Model-Based RL)
برخلاف روشهای بدون مدل که مستقیماً سیاست را یاد میگیرند، روشهای مبتنی بر مدل ابتدا یک مدل از محیط میسازند و سپس از آن برای برنامهریزی استفاده میکنند.
مزایا:
- کارایی نمونه بهتر
- امکان برنامهریزی بلندمدت
- قابلیت استفاده در محیطهای پیچیده
تحقیقات برجسته: الگوریتمهایی مانند MuZero از DeepMind که توانستهاند بدون دانستن قوانین بازی، در بازیهای پیچیده عملکرد فوقالعادهای داشته باشند.
۵. یادگیری تقویتی کوانتومی (Quantum RL)
یکی از جدیدترین حوزههای تحقیقاتی، ترکیب یادگیری تقویتی با محاسبات کوانتومی است که میتواند سرعت و کارایی یادگیری را بهطور چشمگیری افزایش دهد.
روندهای آینده و پیشبینیها
۱. همگرایی با سایر فناوریها
یادگیری تقویتی + اینترنت اشیا (IoT):
ادغام یادگیری تقویتی با IoT منجر به توسعه خانههای هوشمند، شهرهای هوشمند و سیستمهای صنعتی کاملاً خودکار خواهد شد.
یادگیری تقویتی + بلاکچین:
ترکیب این دو فناوری میتواند منجر به ایجاد سیستمهای تصمیمگیری غیرمتمرکز و شفاف شود.
یادگیری تقویتی + واقعیت افزوده/مجازی:
استفاده از یادگیری تقویتی در توسعه محیطهای آموزشی تعاملی و شبیهسازهای پیشرفته.
۲. استانداردسازی و قانونگذاری
با افزایش استفاده از Reinforcement Learning در کاربردهای حیاتی، نیاز به استانداردهای بینالمللی و چارچوبهای قانونی احساس میشود.
حوزههای نیازمند قانونگذاری:
- مسئولیت قانونی در تصمیمات خودکار
- حفظ حریم خصوصی و امنیت داده
- شفافیت و قابلیت حسابرسی الگوریتمها
- استانداردهای ایمنی در سیستمهای حیاتی
۳. دموکراتیزهشدن یادگیری تقویتی
پلتفرمهای ابری:
ارائهدهندگان خدمات ابری مانند AWS، Google Cloud و Microsoft Azure در حال توسعه خدمات یادگیری تقویتی بهصورت خدمات (RL-as-a-Service) هستند که دسترسی به این فناوری را برای شرکتهای کوچک و محققان فراهم میکند.
کتابخانهها و چارچوبهای متنباز:
توسعه فزاینده کتابخانههای متنباز مانند:
- Stable-Baselines3: پیادهسازی الگوریتمهای یادگیری تقویتی با کیفیت بالا
- Ray RLlib: پلتفرم مقیاسپذیر برای یادگیری تقویتی
- OpenAI Gym: محیط استاندارد برای توسعه و مقایسه الگوریتمها
- TensorFlow Agents و PyTorch RL: چارچوبهای یادگیری عمیق تقویتی
۴. یادگیری مادامالعمر (Lifelong Learning)
یکی از اهداف بلندمدت، توسعه عواملی است که بتوانند بهطور مداوم در طول زمان یاد بگیرند و به محیطهای در حال تغییر سازگار شوند، بدون اینکه دانش قبلی خود را از دست بدهند.
چالشها:
- فراموشی فاجعهبار (Catastrophic Forgetting)
- تعادل بین ثبات و انعطافپذیری
- مدیریت حافظه در سیستمهای بلندمدت
۵. عوامل عمومی (Generalist Agents)
هدف نهایی، توسعه عواملی است که بتوانند طیف گستردهای از وظایف را انجام دهند، نه فقط یک وظیفه خاص.
پروژههای پیشرو:
- Gato از DeepMind: عاملی که میتواند ۶۰۰ وظیفه مختلف را انجام دهد
- RT-2 (Robotic Transformer 2): ترکیب دادههای وب با تجربه رباتیک
- Agent Foundation Models: تلاش برای ساخت مدلهای پایه عاملی مشابه LLMها
۶. یادگیری تقویتی انرژی-کارآمد
با افزایش نگرانیهای زیستمحیطی، تحقیقات بر روی الگوریتمهای یادگیری تقویتی که نیاز محاسباتی کمتری دارند، در حال افزایش است.
رویکردها:
- استفاده از سختافزارهای تخصصی (TPU، NPU)
- الگوریتمهای کارآمد با نمونه کمتر
- یادگیری انتقالی برای کاهش نیاز به آموزش مجدد
ملاحظات اخلاقی و اجتماعی
۱. تأثیر بر اشتغال
با افزایش خودکارسازی از طریق یادگیری تقویتی، نگرانیهایی درباره جابهجایی شغلی وجود دارد.
نیازها:
- برنامههای بازآموزی نیروی کار
- ایجاد مشاغل جدید در حوزه هوش مصنوعی
- سیاستگذاری برای حمایت از کارگران متأثر
۲. سوگیری و عدالت
مدلهای یادگیری تقویتی میتوانند سوگیریهای موجود در دادهها یا توابع پاداش را تقویت کنند.
راهحلها:
- توسعه معیارهای عدالت برای سیستمهای یادگیری تقویتی
- ممیزی منظم الگوریتمها
- تنوع در تیمهای توسعه
۳. مسئولیتپذیری و شفافیت
در سیستمهای خودکار، تعیین مسئول تصمیمات اشتباه میتواند پیچیده باشد.
ملاحظات:
- توسعه مکانیسمهای ردیابی تصمیمات
- ایجاد چارچوبهای قانونی واضح
- الزام به مستندسازی کامل سیستمها
۴. استفاده مخرب
مانند هر فناوری قدرتمند، یادگیری تقویتی میتواند برای اهداف مخرب استفاده شود.
خطرات بالقوه:
- توسعه سلاحهای خودکار
- سیستمهای نظارتی پیشرفته
- دستکاری بازارهای مالی
نیازها:
- توسعه رهنمودهای اخلاقی
- همکاری بینالمللی برای کنترل
- آموزش و آگاهیبخشی محققان
فرصتهای تحقیقاتی و نوآوری
۱. حوزههای تحقیقاتی باز
چندین مسئله بنیادی در Reinforcement Learning همچنان حل نشده باقی ماندهاند:
- مسئله اعتبار (Credit Assignment): تعیین اینکه کدام اقدامات در گذشته منجر به نتایج فعلی شدهاند
- کشف خودکار ساختار: چگونه میتوان ساختارهای سلسلهمراتبی را بهطور خودکار کشف کرد
- یادگیری از دادههای آفلاین: بهبود الگوریتمهایی که فقط از دادههای ثبتشده یاد میگیرند
- تعمیم به محیطهای جدید: چگونه میتوان عوامل را آموزش داد که در محیطهای کاملاً جدید خوب عمل کنند
۲. فرصتهای کارآفرینی
استارتاپهای برجسته در حوزه Reinforcement Learning :
- Sakana AI: متمرکز بر روشهای تحقیق و توسعه مبتنی بر یادگیری تقویتی
- Poolside: توسعه مدلهای هوش مصنوعی پیشرفته برای مهندسی نرمافزار
- Swiss-Mile: رباتیک پیشرفته با استفاده از یادگیری تقویتی
- Shield AI: سیستمهای دفاعی خودمختار
- Lux AI: مسابقات و تحقیقات یادگیری تقویتی چند عامله
- Equilibre Technologies: ترکیب یادگیری تقویتی با نظریه بازی برای امور مالی
حوزههای با پتانسیل بالا برای استارتاپها:
- ابزارهای توسعه و آزمون یادگیری تقویتی
- پلتفرمهای شبیهسازی تخصصی
- خدمات مشاوره و پیادهسازی
- راهحلهای صنعت-محور
۳. همکاری بینرشتهای
موفقیت در توسعه کاربردهای یادگیری تقویتی نیازمند همکاری بین رشتههای مختلف است:
- علوم شناختی: درک بهتر از نحوه یادگیری انسانها
- روانشناسی: طراحی تعاملات انسان-ماشین بهتر
- فلسفه: بررسی مسائل اخلاقی و معرفتشناختی
- اقتصاد: تحلیل تأثیرات اقتصادی و اجتماعی
- حقوق: توسعه چارچوبهای قانونی مناسب
نقشه راه پیادهسازی برای سازمانها
مرحله ۱: ارزیابی و برنامهریزی (۳-۶ ماه)
فعالیتهای کلیدی:
- شناسایی موارد استفاده مناسب برای یادگیری تقویتی
- ارزیابی آمادگی دادهها و زیرساخت
- تشکیل تیم متخصص یا مشاوره با خبرگان
- تعیین معیارهای موفقیت و KPIها
سؤالات کلیدی:
- آیا مسئله شامل تصمیمگیری متوالی است؟
- آیا امکان تعریف تابع پاداش واضح وجود دارد؟
- آیا شبیهسازی محیط امکانپذیر است؟
- آیا هزینه اشتباه قابل تحمل است؟
مرحله ۲: پایلوت و اثبات مفهوم (۶-۱۲ ماه)
رویکرد پیشنهادی:
- شروع با مسئلهای ساده و محدود
- استفاده از کتابخانههای متنباز برای کاهش هزینه
- آموزش در محیط شبیهسازی قبل از محیط واقعی
- جمعآوری بازخورد مداوم از ذینفعان
معیارهای موفقیت:
- دستیابی به عملکرد حداقلی قابل قبول
- اثبات مقیاسپذیری راهحل
- تأیید بازگشت سرمایه احتمالی
مرحله ۳: توسعه و استقرار (۱-۲ سال)
ملاحظات فنی:
- توسعه زیرساخت مانیتورینگ و logging
- پیادهسازی مکانیسمهای ایمنی و fallback
- آموزش کارکنان برای کار با سیستم جدید
- مستندسازی کامل سیستم
نکات مهم:
- نظارت مداوم بر عملکرد سیستم
- آماده بودن برای تنظیمات و بهبودهای تکراری
- حفظ تعادل بین خودکارسازی و نظارت انسانی
مرحله ۴: بهینهسازی و مقیاسدهی (مداوم)
فعالیتهای کلیدی:
- جمعآوری و تحلیل دادههای عملکرد
- بازآموزی مدلها با دادههای جدید
- گسترش به موارد استفاده جدید
- بهروزرسانی بر اساس پیشرفتهای تحقیقاتی
منابع آموزشی و راهنماها
کتابهای پیشنهادی
۱. “Reinforcement Learning: An Introduction” توسط ریچارد ساتون و اندرو بارتو – مرجع کلاسیک و جامع ۲. “Deep Reinforcement Learning Hands-On” توسط ماکسیم لاپان – رویکرد عملی با پایتون ۳. “Algorithms for Reinforcement Learning” توسط چابا سزپسواری – مروری مختصر بر الگوریتمهای اصلی
دورههای آنلاین
۱. CS285 (UC Berkeley): Deep Reinforcement Learning توسط سرگئی لوین ۲. Coursera: Specialization در یادگیری تقویتی از دانشگاه آلبرتا ۳. DeepMind x UCL: سری سخنرانیهای یادگیری تقویتی
پلتفرمهای عملی
۱. OpenAI Gym: مجموعه محیطهای استاندارد ۲. Unity ML-Agents: یادگیری تقویتی در محیط یونیتی ۳. Google Colab: محیط رایگان برای آزمایش الگوریتمها
نتیجهگیری و چشمانداز
Reinforcement Learning در آستانه تحولی بزرگ قرار دارد. با پیشرفتهای اخیر در زمینه هوش مصنوعی مولد، رباتیک و محاسبات کوانتومی، انتظار میرود این فناوری در دهه آینده نقش محوری در تحول دیجیتال صنایع ایفا کند.
پیشبینیهای کلیدی برای ۵ سال آینده (۲۰۲۵-۲۰۳۰):
۱. رشد بازار: ارزش بازار جهانی یادگیری تقویتی از ۱۲.۲ میلیارد دلار در سال ۲۰۲۴ به بیش از ۵۰ میلیارد دلار در سال ۲۰۳۰ خواهد رسید
۲. کاربردهای بالینی: استفاده گسترده از یادگیری تقویتی در تشخیص و درمان بیماریهای پیچیده، با تأیید نهادهای نظارتی بینالمللی
۳. خودروهای خودران: عملیاتیشدن کامل خودروهای خودران سطح ۴ و ۵ در شهرهای بزرگ، با یادگیری تقویتی بهعنوان هسته اصلی سیستم تصمیمگیری
۴. رباتیک خانگی: ورود رباتهای چندمنظوره خانگی به بازار انبوه که با استفاده از یادگیری تقویتی قادر به انجام طیف وسیعی از وظایف هستند
۵. هوش مصنوعی مولد: ادغام کامل یادگیری تقویتی در مدلهای زبانی و تصویری، منجر به تواناییهای استدلال و برنامهریزی پیچیدهتر
۶. استانداردسازی: ایجاد استانداردهای بینالمللی برای ایمنی، شفافیت و اخلاق در سیستمهای یادگیری تقویتی