با پیشبینی رسیدن حجم دادههای جهانی به ۱۸۱ زتابایت تا سال ۲۰۲۵، سازمانها با چالش بزرگی در تضمین کیفیت دادهها روبرو هستند. بر اساس تحقیقات اخیر، ۹۵ درصد از کسبوکارها کیفیت داده را به عنوان عامل حیاتی در تحول دیجیتال خود میدانند. در این میان، هوش مصنوعی نه تنها به عنوان یک ابزار اختیاری، بلکه به عنوان ضرورتی حیاتی برای موفقیت سازمانی ظهور کرده است. حتی پیشرفتهترین الگوریتمهای هوش مصنوعی نیز در صورت استفاده از دادههای بیکیفیت، نتایج نامطلوبی تولید خواهند کرد.
بخش اول: اهمیت کیفیت داده در موفقیت مدلهای هوش مصنوعی
۱.۱ نقش حیاتی دادههای با کیفیت
کیفیت داده به طور مستقیم بر عملکرد، دقت و قابلیت اطمینان مدلهای هوش مصنوعی تأثیر میگذارد. همانطور که پروفسور اندرو انگ از دانشگاه استنفورد بیان میکند: «اگر ۸۰ درصد از کار ما آمادهسازی داده است، پس تضمین کیفیت داده مهمترین وظیفه برای تیم یادگیری ماشین است.»
۱.۲ ابعاد کلیدی کیفیت داده
بر اساس استانداردهای ISO 25000 و تحقیقات منتشر شده در سال ۲۰۲۵، ابعاد اصلی کیفیت داده عبارتند از:
دقت (Accuracy)
تطابق دادهها با واقعیت و صحت اطلاعات ثبت شده. خطاها در ورودی دادهها میتوانند منجر به تصمیمات نادرست یا بینشهای گمراهکننده شوند.
کامل بودن (Completeness)
اطمینان از وجود تمامی دادههای مورد نیاز بدون نقص یا گمشدگی. دادههای ناقص میتوانند عملکرد مدل را به شدت کاهش دهند.
سازگاری (Consistency)
پیروی دادهها از فرمت و ساختار استاندارد که پردازش و تحلیل کارآمد را تسهیل میکند.
بهروز بودن (Timeliness)
اطمینان از جدید بودن دادهها و مناسب بودن آنها برای تصمیمگیریهای فعلی.
یکتایی (Uniqueness)
شناسایی و حذف رکوردهای تکراری که میتوانند نتایج را مخدوش کنند.
۱.۳ چالشهای تضمین کیفیت داده
سازمانها در مسیر تضمین کیفیت داده با چالشهای متعددی مواجه هستند:
سیلوهای دادهای: جداسازی دادهها در بخشهای مختلف سازمان که مانع از دیدگاه یکپارچه میشود.
مالکیت نامشخص: عدم وضوح در مسئولیتپذیری برای کیفیت دادهها.
حجم و سرعت دادهها: مدیریت حجم عظیم دادههایی که با سرعت بالا تولید میشوند.
تنوع منابع داده: یکپارچهسازی دادهها از منابع مختلف با فرمتهای متفاوت.
بخش دوم: چارچوبهای ارزیابی کیفیت مدلهای هوش مصنوعی
۲.۱ چارچوب METRIC برای دادههای پزشکی
تحقیقات منتشر شده در مجله Nature در سال ۲۰۲۴ چارچوب METRIC را برای ارزیابی کیفیت دادههای آموزشی در حوزه پزشکی معرفی کرده است. این چارچوب شامل ابعاد زیر است:
- سازگاری منطقی: بررسی عدم وجود تناقضات در مجموعه داده
- سازگاری توزیع: ارزیابی ویژگیهای آماری زیرمجموعههای داده
- همگنی: بررسی شباهت یا تفاوت خصوصیات آماری در نقاط زمانی مختلف
۲.۲ معیارهای ارزیابی عملکرد مدل
معیارهای طبقهبندی (Classification Metrics)
ماتریس درهمریختگی (Confusion Matrix): ابزاری برای نمایش عملکرد مدل در پیشبینی کلاسهای مختلف.
دقت (Accuracy): نسبت پیشبینیهای صحیح به کل پیشبینیها.
حساسیت (Recall): توانایی مدل در شناسایی موارد مثبت واقعی.
صحت (Precision): دقت در پیشبینی موارد مثبت.
امتیاز F1: میانگین هارمونیک صحت و حساسیت.
معیارهای رگرسیون (Regression Metrics)
میانگین مربعات خطا (MSE): میانگین مربع تفاوت بین مقادیر پیشبینی شده و واقعی.
میانگین قدر مطلق خطا (MAE): میانگین قدر مطلق خطاها.
ضریب تعیین (R²): نسبت واریانس توضیح داده شده توسط مدل.
۲.۳ معیارهای مبتنی بر هوش مصنوعی
سیستمهای مدرن از معیارهای مبتنی بر هوش مصنوعی برای ارزیابی کیفیت استفاده میکنند:
معیارهای تطبیقی (Adaptive Rubrics): تولید خودکار معیارهای سنجش منحصر به فرد برای هر پرامپت.
ارزیابی کیفیت عمومی (GENERAL_QUALITY): پوشش جنبههای مختلف مانند پیروی از دستورالعملها، فرمتبندی، لحن و سبک.
بخش سوم: تکنیکهای پیشرفته مدیریت کیفیت خروجی
۳.۱ مهندسی پرامپت (Prompt Engineering)
مهندسی پرامپت به عنوان یکی از مهمترین مهارتهای مورد نیاز در سال ۲۰۲۵ شناخته شده است. این رشته نسبتاً جدید شامل طراحی و بهینهسازی دستورالعملهایی است که به مدلهای زبانی داده میشود.
اصول کلیدی مهندسی پرامپت
وضوح و دقت: تعریف واضح آنچه از مدل انتظار دارید. هرچه دقیقتر باشید، نتایج بهتری دریافت خواهید کرد.
ارائه زمینه (Context): فراهم کردن اطلاعات پسزمینه کافی برای درک بهتر درخواست.
استفاده از مثالها: ارائه نمونههای ورودی و خروجی مطلوب (Few-shot learning).
ساختاردهی مناسب: استفاده از فرمتهای ساختاریافته مانند JSON یا Markdown برای وضوح بیشتر.
تکنیکهای پیشرفته برای مدلهای مختلف
- ارائه زمینه جامع و محدودیتها در ابتدا
- درخواست استدلال گامبهگام
- تأکید بر تحلیل ساختاریافته
GPT-4:
- استفاده از دستورالعملهای مستقیم و واضح
- بهرهگیری از حافظه مداوم برای تعاملات طولانی
- تنظیم پارامترهای دما و نمونهبرداری
Gemini:
- مدیریت زمینه درونجلسهای برای ورودیهای طولانی
- استفاده از قابلیتهای چندوجهی (multimodal)
۳.۲ پیادهسازی محافظهای کیفیت (Quality Guardrails)
محافظهای کیفیت نقاط بازرسی حیاتی در خطوط لوله استقرار هوش مصنوعی هستند که مدلها باید قبل از پیشروی به مراحل بعدی، معیارهای کیفی خاصی را برآورده کنند.
انواع محافظهای کیفیت
محافظهای اعتبارسنجی داده:
- بررسی کیفیت دادههای ورودی
- تطابق با توزیعهای مورد انتظار
- شناسایی دادههای پرت و ناهنجاریها
عملکرد مدل:
- ارزیابی معیارهای دقت و صحت
- آزمونهای رگرسیون
- تستهای A/B
ایمنی و اخلاق:
- شناسایی محتوای مضر یا نامناسب
- بررسی تبعیض و سوگیری
- رعایت استانداردهای اخلاقی
۳.۳ سیستمهای خودترمیم (Self-Healing Systems)
یکی از نوآوریهای مهم در سال ۲۰۲۵، توسعه سیستمهای خودترمیم است که میتوانند:
- تغییرات در رابط کاربری را شناسایی و با آنها سازگار شوند
- اسکریپتهای تست را به صورت خودکار بهروزرسانی کنند
- مشکلات را قبل از تأثیر بر کاربران نهایی شناسایی کنند
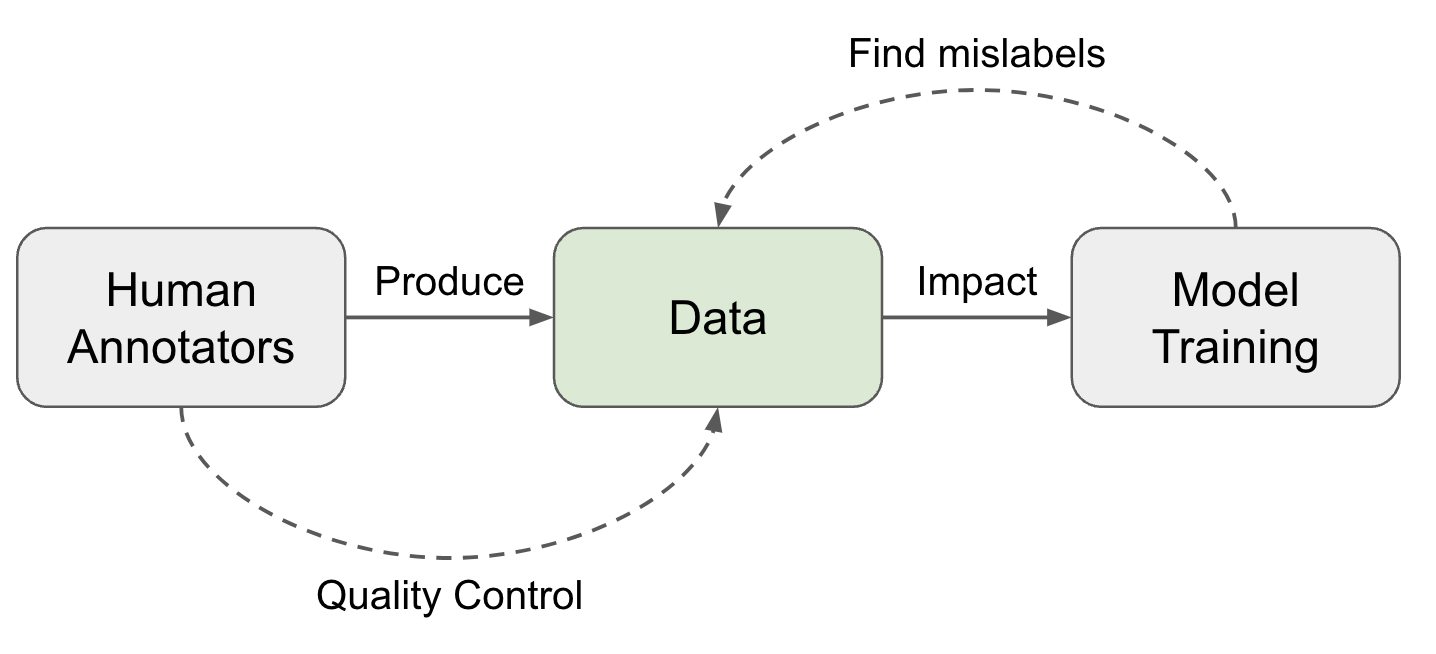
بخش چهارم: نقش انسان در حلقه (Human-in-the-Loop)
۴.۱ اهمیت نظارت انسانی
سیستمهای Human-in-the-Loop (HITL) با ترکیب هوش انسانی و قدرت پردازش ماشین، دقت و قابلیت اطمینان سیستمهای هوش مصنوعی را به طور قابل توجهی بهبود میبخشند.
مزایای کلیدی HITL
بهبود دقت: مطالعات نشان میدهند که سیستمهای HITL میتوانند نرخ دقت را به میزان قابل توجهی نسبت به سیستمهای کاملاً خودکار افزایش دهند.
کاهش سوگیری: انسانها میتوانند سوگیریهای موجود در دادههای آموزشی را شناسایی و اصلاح کنند.
مدیریت موارد استثنایی: انسانها در مواجهه با موارد پیچیده یا غیرمنتظره که در دادههای آموزشی وجود نداشتهاند، عملکرد بهتری دارند.
انطباق پذیری: ورودی انسانی امکان سازگاری سریع با شرایط جدید را فراهم میکند.
۴.۲ انواع پیکربندیهای HITL
HITL بلادرنگ (Real-time HITL): انسانها به طور فعال در فرآیند تصمیمگیری مشارکت دارند و سیستم در صورت عدم اطمینان، به اپراتور انسانی ارجاع میدهد.
دستهای (Batch HITL): انسانها تصمیمات هوش مصنوعی را پس از اتخاذ اما قبل از اجرا بررسی و تأیید میکنند.
حلقه بازخورد (Feedback Loop HITL): انسانها بازخورد مستمر برای بهبود مدل ارائه میدهند.
۴.۳ بهترین شیوههای پیادهسازی HITL
تعیین آستانههای اطمینان: مشخص کردن سطوح اطمینانی که در آنها مداخله انسانی ضروری است.
آموزش نیروی انسانی: اطمینان از آموزش مناسب افراد درگیر در فرآیند.
طراحی رابط کاربری کارآمد: ایجاد ابزارهایی که امکان بررسی و تصمیمگیری سریع را فراهم کنند.
مستندسازی تصمیمات: ثبت دلایل تصمیمات انسانی برای یادگیری آینده.
بخش پنجم: ابزارها و فناوریهای مدیریت کیفیت
۵.۱ پلتفرمهای تست خودکار مبتنی بر هوش مصنوعی
ابزارهای برتر سال ۲۰۲۵
ACCELQ:
- پلتفرم تست بدون کد مبتنی بر ابر
- قابلیتهای خودترمیمی با هوش مصنوعی
- کاهش ۷۲٪ در هزینههای نگهداری
Katalon TestOps:
- پلتفرم مدیریت کیفیت مدرن
- یکپارچهسازی با ابزارهای CI/CD
- تولید خودکار موارد تست با GPT
Applitools:
- تست بصری با هوش مصنوعی
- شناسایی تغییرات UI
- مقایسههای هوشمند تصاویر
Mabl:
- یادگیری ماشین برای بهینهسازی زمانبندی تست
- شناسایی خودکار مشکلات احتمالی
- تحلیل عملکرد تست
۵.۲ ابزارهای مدیریت کیفیت داده
Techment AI:
- ارزیابیهای امکانسنجی
- تنظیم دقیق مدلهای پیشآموزش دیده
- یکپارچهسازی با سیستمهای موجود
Alation:
- پلتفرم هوش داده مدرن
- نظارت و حاکمیت داده در مقیاس
- شناسایی خودکار مشکلات کیفیت
Acceldata:
- تشخیص ناهنجاریها در زمان واقعی
- شناسایی علت ریشهای مشکلات
- اقدامات اصلاحی خودکار
۵.۳ چارچوبهای ارزیابی مدل
Azure AI Foundry:
- معیارهای کیفیت با کمک هوش مصنوعی
- ارزیابی ریسک و ایمنی
- شبیهسازی حملات متخاصمانه
Google Vertex AI:
- معیارهای مبتنی بر rubric
- ارزیابیهای تطبیقی
- تستهای واحد برای مدلها
بخش ششم: استراتژیهای پیادهسازی موفق
۶.۱ ارزیابی نیازهای سازمانی
قبل از پیادهسازی سیستمهای مدیریت کیفیت، سازمانها باید:
شناسایی اهداف کیفیت: تعریف واضح معیارهای موفقیت و اهداف کیفی.
ممیزی وضعیت فعلی: بررسی وضعیت کنونی کیفیت دادهها و مدلها.
تحلیل شکاف: شناسایی فاصله بین وضعیت موجود و مطلوب.
اولویتبندی: تمرکز بر حوزههایی که بیشترین تأثیر را دارند.
۶.۲ ایجاد فرهنگ کیفیت
مسئولیتپذیری داده: همه افراد درگیر با داده باید مسئولیت امنیت و دقت را بر عهده بگیرند.
آموزش مستمر: برگزاری دورههای آموزشی منظم برای کارکنان.
تشویق بازخورد: ایجاد کانالهای ارتباطی برای گزارش مشکلات کیفی.
بهبود مستمر: پیادهسازی چرخه PDCA (برنامهریزی، اجرا، بررسی، اقدام).
۶.۳ معیارهای کلیدی عملکرد (KPIs)
برای ارزیابی موفقیت برنامههای مدیریت کیفیت، سازمانها باید KPIهای زیر را پایش کنند:
نرخ دقت مدل: درصد پیشبینیهای صحیح.
زمان پاسخ: مدت زمان لازم برای تولید خروجی.
نرخ خطا: تعداد خطاها در واحد زمان یا تعداد درخواست.
رضایت کاربر: نظرسنجی از کاربران نهایی.
بازگشت سرمایه (ROI): ارزیابی منافع مالی نسبت به هزینهها.
بخش هفتم: چالشها و راهحلهای آینده
۷.۱ چالشهای پیش رو
پیچیدگی فزاینده مدلها: با پیچیدهتر شدن مدلهای هوش مصنوعی، ارزیابی و تضمین کیفیت آنها دشوارتر میشود.
مقیاسپذیری: حفظ کیفیت در مقیاس بزرگ همچنان چالشبرانگیز است.
تغییرات مداوم: سازگاری با تغییرات سریع در فناوری و نیازهای کسبوکار.
نگرانیهای اخلاقی و حریم خصوصی: تعادل بین کیفیت و حفظ حریم خصوصی کاربران.
۷.۲ روندهای آینده
هوش مصنوعی قابل توضیح (Explainable AI): توسعه سیستمهایی که تصمیمات خود را به صورت شفاف توضیح میدهند.
یادگیری فدرال (Federated Learning): آموزش مدلها بدون به اشتراکگذاری دادههای خام.
عاملهای هوش مصنوعی خودمختار: سیستمهایی که میتوانند کیفیت خود را به صورت خودکار بهبود دهند.
استانداردسازی بینالمللی: توسعه استانداردهای جهانی برای کیفیت هوش مصنوعی.
۷.۳ توصیههای عملی
شروع با پایلوت: آغاز با پروژههای کوچک و گسترش تدریجی.
همکاری چندبخشی: درگیر کردن تیمهای مختلف از جمله IT، کیفیت، و واحدهای کسبوکار.
سرمایهگذاری در زیرساخت: ایجاد زیرساختهای مناسب برای پردازش و ذخیرهسازی داده.
پایش مستمر: نظارت دائمی بر عملکرد و کیفیت سیستمها.
بخش هشتم: مطالعات موردی موفق
۸.۱ شرکت جنرال الکتریک (GE)
جنرال الکتریک با پیادهسازی پلتفرم Predix و ابزارهای خودکار برای پاکسازی، اعتبارسنجی و نظارت مستمر دادهها، توانست:
- کیفیت دادههای تولید شده توسط تجهیزات صنعتی را تضمین کند
- نیاز به مداخله دستی را کاهش دهد
- بینشهای بلادرنگ مبتنی بر داده ارائه دهد
- دقت مدلهای پیشبینی خرابی را افزایش دهد
۸.۲ شرکت Airbnb
Airbnb با راهاندازی «دانشگاه داده» موفق شد:
- سواد دادهای کارکنان را افزایش دهد
- کاربران فعال هفتگی ابزارهای علم داده را از ۳۰٪ به ۴۵٪ برساند
- فرهنگ کیفیت داده را در سراسر سازمان ترویج دهد
- همسویی بین اهداف کسبوکار و مدیریت داده ایجاد کند
۸.۳ شرکتهای ایرانی پیشرو
در ایران نیز شرکتهای پیشرو در حوزه فناوری اطلاعات، اقدامات قابل توجهی در زمینه مدیریت کیفیت هوش مصنوعی انجام دادهاند:
بانکهای دیجیتال: استفاده از سیستمهای HITL برای تشخیص تقلب و ارزیابی ریسک اعتباری.
پلتفرمهای تجارت الکترونیک: پیادهسازی سیستمهای توصیهگر با نظارت انسانی برای بهبود تجربه کاربری.
استارتاپهای حوزه سلامت: استفاده از هوش مصنوعی با نظارت پزشکان برای تشخیص بیماریها.
بخش نهم: راهنمای عملی پیادهسازی
۹.۱ مرحله آمادهسازی (ماه ۱-۲)
هفته ۱-۲: ارزیابی وضعیت موجود
- ممیزی کیفیت دادههای فعلی
- شناسایی نقاط ضعف و قوت
- تعیین اهداف کیفی
۳-۴: تشکیل تیم کیفیت
- انتخاب اعضای تیم از بخشهای مختلف
- تعریف نقشها و مسئولیتها
- برگزاری جلسات هماهنگی
۵-۸: طراحی استراتژی
- تدوین چارچوب مدیریت کیفیت
- انتخاب ابزارها و فناوریها
- تعیین KPIها و معیارهای موفقیت
۹.۲ مرحله پایلوت (ماه ۳-۴)
انتخاب پروژه پایلوت:
- پروژهای با ریسک پایین اما تأثیر قابل اندازهگیری
- دسترسی به دادههای کافی
- پشتیبانی مدیریت
اجرای پایلوت:
- پیادهسازی ابزارهای انتخابی
- آموزش تیمهای درگیر
- جمعآوری بازخورد مستمر
ارزیابی نتایج:
- مقایسه با معیارهای تعیین شده
- شناسایی درسآموختهها
- اصلاح استراتژی بر اساس نتایج
۹.۳ مرحله گسترش (ماه ۵-۶)
مقیاسگذاری تدریجی:
- گسترش به پروژههای بیشتر
- افزایش تعداد کاربران
- پیادهسازی فرآیندهای خودکار
یکپارچهسازی سیستمها:
- اتصال به سیستمهای موجود
- ایجاد داشبوردهای نظارتی
- پیادهسازی APIها
۹.۴ مرحله بلوغ (ماه ۷ به بعد)
بهینهسازی مستمر:
- تحلیل عملکرد دورهای
- بهروزرسانی مدلها و الگوریتمها
- بهبود فرآیندها
نوآوری و توسعه:
- آزمایش تکنولوژیهای جدید
- توسعه قابلیتهای داخلی
- همکاری با مراکز تحقیقاتی
بخش دهم: ملاحظات اخلاقی و قانونی
۱۰.۱ اصول اخلاقی در مدیریت کیفیت هوش مصنوعی
شفافیت: توضیح واضح نحوه عملکرد سیستمها و تصمیمگیریها.
عدالت: اطمینان از عدم تبعیض و برابری در خروجیها.
پاسخگویی: مشخص بودن مسئولیتها در قبال تصمیمات سیستم.
حریم خصوصی: حفاظت از دادههای شخصی و رعایت حقوق کاربران.
۱۰.۲ الزامات قانونی
GDPR و قوانین حریم خصوصی: رعایت مقررات بینالمللی و ملی حفاظت از داده.
استانداردهای صنعتی: پیروی از استانداردهای ISO و IEEE در حوزه هوش مصنوعی.
مسئولیتهای حقوقی: درک و مدیریت مسئولیتهای ناشی از تصمیمات هوش مصنوعی.
۱۰.۳ چارچوب حاکمیت داده
سیاستهای داده:
- تعریف قوانین دسترسی و استفاده
- مشخص کردن دوره نگهداری
- تعیین فرآیندهای حذف داده
نقشها و مسئولیتها:
- مالک داده (Data Owner)
- متولی داده (Data Steward)
- مصرفکننده داده (Data Consumer)
فرآیندهای نظارتی:
- ممیزی دورهای
- گزارشدهی انحرافات
- اقدامات اصلاحی
بخش یازدهم: ابزارهای بومی و راهکارهای ایرانی
۱۱.۱ توسعه ابزارهای بومی
با توجه به تحریمها و محدودیتهای دسترسی به برخی سرویسهای بینالمللی، توسعه ابزارهای بومی اهمیت ویژهای دارد:
مزایای ابزارهای بومی:
- سازگاری با زبان فارسی
- رعایت قوانین و مقررات داخلی
- پشتیبانی محلی
- هزینه کمتر
چالشهای توسعه:
- نیاز به سرمایهگذاری اولیه
- کمبود نیروی متخصص
- رقابت با محصولات بینالمللی
۱۱.۲ همکاریهای دانشگاهی و صنعتی
مراکز تحقیقاتی فعال:
- آزمایشگاههای هوش مصنوعی دانشگاههای برتر
- مراکز نوآوری و شتابدهندهها
- پارکهای علم و فناوری
برنامههای حمایتی:
- معاونت علمی و فناوری ریاست جمهوری
- صندوق نوآوری و شکوفایی
- برنامههای حمایت از استارتاپها
۱۱.۳ استانداردهای ملی
تدوین استانداردهای بومی:
- همکاری با سازمان ملی استاندارد
- تطبیق با استانداردهای بینالمللی
- توجه به نیازهای خاص کشور
بخش دوازدهم: آیندهنگری و روندهای ۲۰۲۶
۱۲.۱ پیشبینیهای کوتاهمدت
سال ۲۰۲۵-۲۰۲۶:
- افزایش ۴۰٪ در استفاده از ابزارهای HITL
- توسعه مدلهای زبانی فارسی پیشرفته
- استانداردسازی فرآیندهای کیفیت هوش مصنوعی
۱۲.۲ چشمانداز بلندمدت
افق ۵ ساله:
- همگرایی هوش مصنوعی و اینترنت اشیا
- توسعه سیستمهای خودمختار با نظارت حداقلی
- ایجاد اکوسیستم یکپارچه مدیریت کیفیت
۱۲.۳ فرصتهای سرمایهگذاری
حوزههای پرپتانسیل:
- ابزارهای تست خودکار
- پلتفرمهای مدیریت داده
- سرویسهای مشاوره و آموزش
- راهکارهای امنیت هوش مصنوعی
نتیجهگیری
مدیریت کیفیت خروجی مدلهای هوش مصنوعی نه تنها یک ضرورت فنی، بلکه یک الزام استراتژیک برای موفقیت در عصر دیجیتال است. با ترکیب هوشمندانه فناوریهای پیشرفته، نظارت انسانی، و فرآیندهای ساختاریافته، سازمانها میتوانند از پتانسیل کامل هوش مصنوعی بهرهبرداری کنند.
کلیدهای موفقیت در این مسیر عبارتند از:
- تعهد مدیریت ارشد: پشتیبانی قوی از سوی رهبری سازمان
- سرمایهگذاری در زیرساخت: ایجاد بستر مناسب فنی و انسانی
- فرهنگسازی: ترویج فرهنگ کیفیت در تمام سطوح سازمان
- یادگیری مستمر: بهروزرسانی دانش و مهارتها
- همکاری و همافزایی: تعامل مؤثر بین تیمهای مختلف
با توجه به سرعت تحولات در حوزه هوش مصنوعی، سازمانهایی که امروز در مدیریت کیفیت سرمایهگذاری میکنند، رهبران فردای این صنعت خواهند بود. این سرمایهگذاری نه تنها باعث بهبود عملکرد فعلی میشود، بلکه بنیانی محکم برای نوآوریهای آینده فراهم میآورد.