یادگیری تقویتی (Reinforcement Learning) یکی از شاخههای مهم و پرکاربرد یادگیری ماشین است که در سالهای اخیر توجه بسیاری از محققان و مهندسان را به خود جلب کرده است. این روش یادگیری به عاملها (Agents) اجازه میدهد تا با تعامل با محیط و دریافت پاداشها و تنبیهها، رفتارهای بهینه را یاد بگیرند. در این مقاله، به بررسی مفاهیم پایه، الگوریتمهای مختلف و کاربردهای یادگیری تقویتی خواهیم پرداخت.
الگوریتمهای یادگیری تقویتی
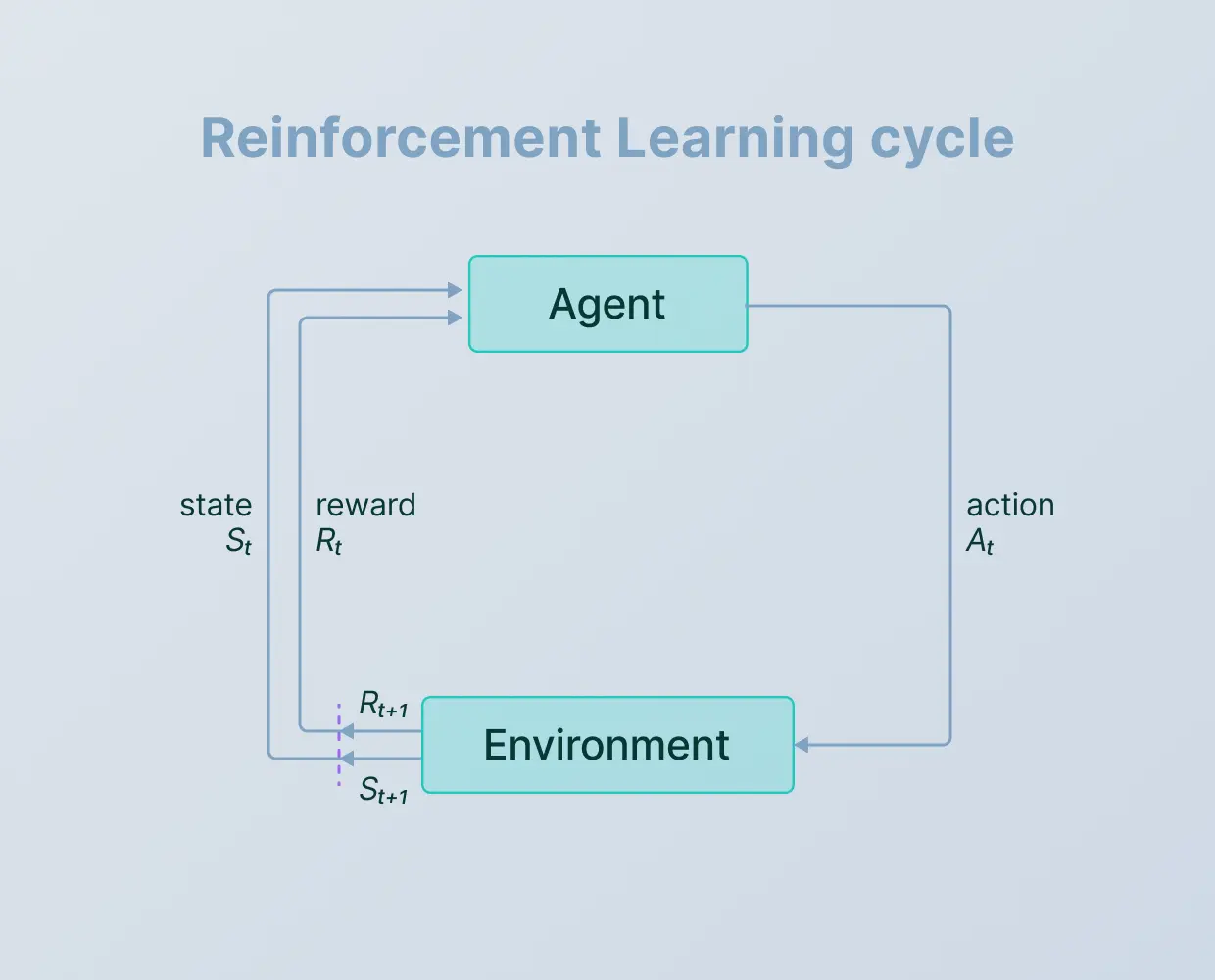
عامل (Agent) چیست ؟
عامل یا عامل هوشمند، موجودیتی است که در محیط فعالیت میکند و تصمیمگیری مینماید. این عامل میتواند یک ربات، یک نرمافزار یا حتی یک انسان باشد. هدف عامل، به حداکثر رساندن پاداش کل در طول زمان است.
محیط (Environment)
محیط، فضایی است که عامل در آن فعالیت میکند و با آن تعامل دارد و میتواند شامل هر چیزی باشد که عامل با آن مواجه میشود، از جمله موانع، منابع و سایر عوامل.
حالت (State)
حالت، نمایانگر وضعیت فعلی محیط است که عامل در آن قرار دارد. حالتها میتوانند به صورت گسسته یا پیوسته باشند و اطلاعاتی راجع به محیط به عامل ارائه میدهند.
عمل (Action)
عمل، تصمیمی است که عامل در هر حالت میگیرد. این تصمیم میتواند حرکت به یک جهت خاص، انتخاب یک گزینه یا هر اقدام دیگری باشد که بر محیط تأثیر میگذارد.
پاداش (Reward)
پاداش، بازخوردی است که عامل پس از انجام یک عمل در یک حالت خاص دریافت میکند و میتواند مثبت یا منفی باشد و هدف عامل، به حداکثر رساندن مجموع پاداشهای دریافتی است.
سیاست (Policy)
تابعی است که به عامل میگوید در هر حالت چه عملی را انجام دهد. سیاست میتواند به صورت قطعی یا احتمالی باشد.
تابع ارزش (Value Function)
تابع ارزش، مقدار پاداش مورد انتظار را برای هر حالت یا حالت-عمل جفتی محاسبه میکند. این تابع به عامل کمک میکند تا تصمیمات بهتری بگیرد.
الگوریتمهای یادگیری تقویتی
الگوریتمهای مبتنی بر سیاست (Policy-Based Methods)
این الگوریتمها مستقیماً سیاست بهینه را یاد میگیرند. این الگوریتمها به جای تخمین تابع ارزش، سیاست را بهبود میبخشند. یکی از معروفترین الگوریتمهای مبتنی بر سیاست، الگوریتم گرادیان سیاست (Policy Gradient) است.
این الگوریتم، سیاست یا قوانین را به صورت پارامتری مدل میکند و با استفاده از گرادیان تابع پاداش، پارامترهای سیاست را بهروزرسانی میکند. این الگوریتم به ویژه در محیطهای پیوسته و با فضای عمل بزرگ مفید است.
الگوریتمهای مبتنی بر ارزش (Value-Based Methods)
الگوریتمهای مبتنی بر ارزش، تابع ارزش را تخمین میزنند و از آن برای استخراج سیاست بهینه استفاده میکنند. یکی از معروفترین الگوریتمهای مبتنی بر ارزش، الگوریتم Q-Learning است.
الگوریتم Q-Learning
الگوریتم Q-Learning، یک روش یادگیری تقویتی بدون مدل است که تابع Q را تخمین میزند. تابع Q، ارزش مورد انتظار یک عمل در یک حالت خاص را نشان میدهد. این الگوریتم با استفاده از معادله بلمن (Bellman Equation) بهروزرسانی میشود و به تدریج به سیاست بهینه نزدیک میشود.
الگوریتمهای مبتنی بر مدل (Model-Based Methods)
الگوریتمهای مبتنی بر مدل، ابتدا مدلی از محیط را یاد میگیرند و سپس از این مدل برای برنامهریزی و تصمیمگیری استفاده میکنند. این الگوریتمها معمولاً در محیطهایی که مدل محیط قابل یادگیری است، کاربرد دارند.
الگوریتم Dyna-Q
الگوریتم Dyna-Q، ترکیبی از الگوریتمهای مبتنی بر مدل و بدون مدل است. این الگوریتم همزمان با یادگیری مدل محیط، از تجربیات واقعی و شبیهسازی شده برای بهروزرسانی تابع ارزش استفاده میکند.
الگوریتمهای ترکیبی (Hybrid Methods)
الگوریتمهای ترکیبی، از ترکیب الگوریتمهای مبتنی بر سیاست و مبتنی بر ارزش استفاده میکنند. یکی از معروفترین الگوریتمهای ترکیبی، الگوریتم Actor-Critic است.
الگوریتم Actor-Critic
الگوریتم Actor-Critic، از دو بخش Actor و Critic تشکیل شده است. Actor سیاست را بهروزرسانی میکند و Critic تابع ارزش را تخمین میزند. این الگوریتم از مزایای هر دو روش بهره میبرد و بهبود عملکرد را تسهیل میکند.
کاربردهای یادگیری تقویتی
بازیهای رایانهای
یکی از معروفترین کاربردهای یادگیری تقویتی، در بازیهای رایانهای است. الگوریتمهای یادگیری تقویتی میتوانند بازیهای پیچیدهای مانند شطرنج، گو و بازیهای ویدیویی را با عملکردی بسیار بالا انجام دهند. به عنوان مثال، الگوریتم AlphaGo که توسط DeepMind توسعه یافته است، توانست قهرمان جهان در بازی گو راادگیری تقویتی در رباتیک نیز کاربردهای فراوانی دارد. رباتها میتوانند با استفاده از این الگوریتمها، وظایف پیچیدهای مانند حرکت در محیطهای ناشناخته، تعامل با اشیاء و انجام کارهای دقیق را یاد بگیرند.
سیستمهای توصیهگر
سیستمهای توصیهگر، مانند آنچه در سایتهای خرید آنلاین و پلتفرمهای پخش ویدیو استفاده میشود، میتوانند با استفاده از یادگیری تقویتی، پیشنهادات بهتری به کاربران ارائه دهند. این سیستمها با تحلیل رفتار کاربران و دریافت بازخورد، به تدریج بهبود مییابند.
بهینهسازی منابع
یادگیری تقویتی میتواند در بهینهسازی منابع در سیستمهای مختلف، از جمله شبکههای کامپیوتری، مدیریت انرژی و حمل و نقل استفاده شود. این الگوریتمها میتوانند با یادگیری از تجربیات گذشته، تخصیص منابع را بهینه کنند و کارایی سیستمها را افزایش دهند.
امور مالی
در امور مالی، یادگیری تقویتی میتواند برای مدیریت پورتفولیو، پیشبینی بازار و انجام معاملات خودکار استفاده شود. این الگوریتمها با تحلیل دادههای مالی و یادگیری از تغییرات بازار، میتوانند تصمیمات بهتری بگیرند و سودآوری را افزایش دهند.
چالشها و آینده یادگیری تقویتی
چالشها
یادگیری تقویتی با چالشهای متعددی مواجه است. یکی از مهمترین چالشها، مسئله مقیاسپذیری است. بسیاری از الگوریتمهای یادگیری تقویتی در محیطهای بزرگ و پیچیده به خوبی عمل نمیکنند و نیاز به بهبود دارند. همچنین، مسئله پایداری و همگرایی نیز از دیگر چالشهای مهم است که باید مورد توجه قرار گیرد.
آینده
با پیشرفتهای اخیر در زمینه هوش مصنوعی و یادگیری ماشین، انتظار میرود که یادگیری تقویتی نیز بهبود یابد و کاربردهای بیشتری پیدا کند. توسعه الگوریتمهای جدید، افزایش قدرت محاسباتی و دسترسی به دادههای بیشتر، میتواند به پیشرفت این حوزه کمک کند. همچنین، ترکیب یادگیری تقویتی با سایر روشهای یادگیری ماشین، مانند یادگیری عمیق، میتواند به نتایج بهتری منجر شود.
نتیجهگیری
یادگیری تقویتی یکی از مهمترین و پرکاربردترین شاخههای یادگیری ماشین است که با استفاده از تعامل با محیط و دریافت بازخورد، به عاملها اجازه میدهد تا رفتارهای بهینه را یاد بگیرند. در این مقاله، به بررسی مفاهیم پایه، الگوریتمهای مختلف و کاربردهای یادگیری تقویتی پرداختیم. با توجه به پیشرفتهای اخیر و چالشهای موجود، آینده این حوزه بسیار روشن به نظر میرسد و انتظار میرود که در سالهای آینده شاهد کاربردهای بیشتری از یادگیری تقویتی در زمینههای مختلف باشیم.