تکنولوژی تولید تقویتشده بازیابی (RAG) یکی از پیشرفتهترین روشهای ترکیب مدلهای زبانی بزرگ با پایگاههای دانش خارجی محسوب میشود. این مقاله به بررسی جامع مبانی نظری، معماری، اجزای کلیدی و کاربردهای عملی RAG میپردازد و چالشها و فرصتهای پیش روی این تکنولوژی نوظهور را تحلیل میکند.
در عصر هوش مصنوعی، مدلهای زبانی بزرگ (LLM) تواناییهای فوقالعادهای در تولید متن و پاسخ به سوالات نشان دادهاند. اما این مدلها با محدودیتهایی مواجه هستند که مهمترین آنها عدم دسترسی به اطلاعات بهروز و دانش تخصصی خاص است. تکنیک RAG برای بهبود دقت و قابلیت اعتماد مدلهای تولیدی هوش مصنوعی با استفاده از حقایق استخراجشده از منابع خارجی طراحی شده است.
تعریف و مفهوم RAG
تولید تقویتشده بازیابی (RAG) یک چارچوب نوآورانه است که قابلیتهای مدلهای زبانی بزرگ را با سیستمهای بازیابی اطلاعات ترکیب میکند. محققان Meta AI روشی به نام تولید تقویتشده بازیابی (RAG) را برای پرداختن به وظایف دانش-محور معرفی کردند. این تکنولوژی به سه مرحله اصلی تقسیم میشود: بازیابی (Retrieve)، تقویت (Augment) و تولید (Generate).
RAG نحوه استفاده کسبوکارها از هوش مصنوعی RAG را تبیین میکند و راه حلی برای غلبه بر محدودیتهای اساسی مدلهای زبانی ارائه میدهد.
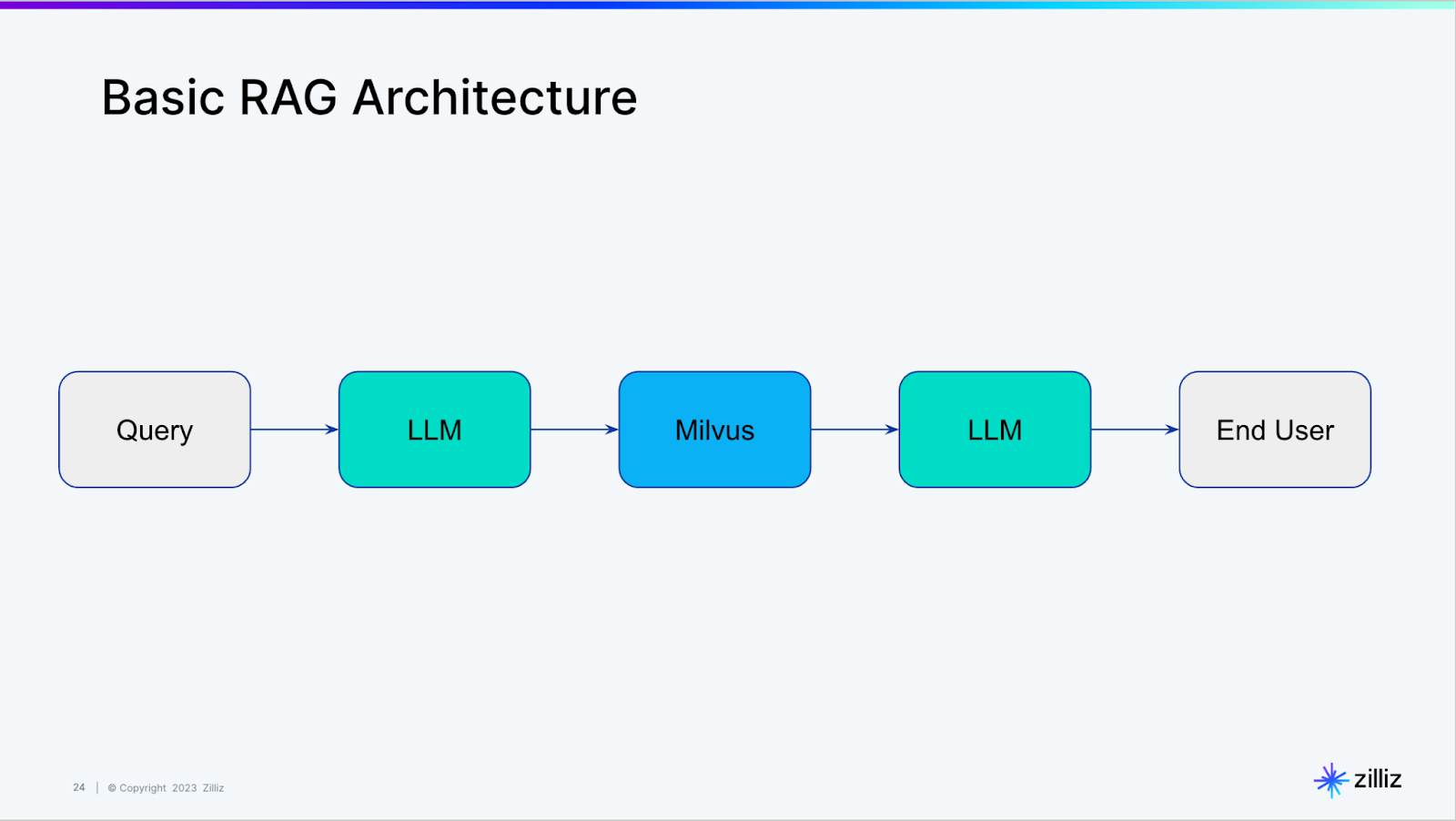
معماری و اجزای کلیدی RAG
ساختار کلی
معماری RAG از چندین جزء اساسی تشکیل شده است که هر یک نقش مهمی در فرآیند تولید پاسخ ایفا میکند:
1. پایگاه دانش (Knowledge Base) اولین جزء اساسی، مجموعه اسناد و اطلاعاتی است که به عنوان منبع دانش خارجی عمل میکند. اسناد به عنوان پایگاه دانش، مدل تعمیمدهنده که اسناد را به بردارها تبدیل میکند و پایگاه بردار که پایگاه داده تخصصی برای ذخیره بردارها محسوب میشود.
2. مدل تعمیمدهنده (Embedding Model) این مدل وظیفه تبدیل متون به بردارهای عددی را بر عهده دارد. مدل تعمیمدهنده: سوال ورودی ابتدا با استفاده از مدل تعمیمدهنده به بردارهای تعمیم تبدیل میشود.
3. پایگاه داده بردار (Vector Database) پایگاههای داده بردار به طور مؤثر بردارهای چندبعدی بزرگ مانند تعمیمهای شبکه عصبی را ذخیره و بازیابی میکنند و امکان جستجوی شباهتمحور را فراهم میآورند.
4. سیستم بازیابی (Retrieval System) وقتی سوالی از بازیابنده میپرسید، از جستجوی شباهت برای اسکن پایگاه دانش گسترده بردارهای تعمیم استفاده میکند و مرتبطترین اطلاعات را شناسایی میکند.
5. مولد پاسخ (Generator – LLM) آخرین جزء که اطلاعات را برای تولید پاسخ ترکیب میکند و خروجی نهایی را ارائه میدهد.
فرآیند کارکرد
فرآیند کار RAG در قالب مراحل زیر انجام میشود:
- پردازش سوال: سوال کاربر به بردار تبدیل میشود
- جستجوی شباهت: سیستم مرتبطترین اسناد را شناسایی میکند
- بازیابی زمینه: اطلاعات مرتبط استخراج میشود
- تقویت سوال: سوال اصلی با اطلاعات بازیابیشده غنی میشود
- تولید پاسخ: مدل زبانی پاسخ نهایی را تولید میکند
مزایای کلیدی RAG
بهبود دقت اطلاعات
RAG یک رویکرد معماری است که دادههای شما را به عنوان زمینه برای مدلهای زبانی بزرگ جهت بهبود ارتباط استخراج میکند. این امر باعث کاهش قابل توجه پدیده “هذیان” (Hallucination) در مدلهای زبانی میشود.
بهروزرسانی مداوم دانش
برخلاف مدلهای سنتی که دانش آنها در زمان آموزش ثابت میماند، RAG امکان دسترسی به اطلاعات جدید را بدون نیاز به آموزش مجدد فراهم میکند.
انطباقپذیری بالا
مدلهای RAG راهحلهایی تولید میکنند که میتوانند چالشهای مدلهای زبانی بزرگ را حل کنند و برای حوزههای تخصصی مختلف قابل تنظیم هستند.
مقیاسپذیری
سیستمهای RAG قابلیت پردازش حجم عظیمی از اطلاعات را دارند و با افزایش دادهها عملکرد بهتری ارائه میدهند.
کاربردهای عملی RAG
پشتیبانی مشتریان هوشمند
RAG در بهبود پشتیبانی مشتریان تا تحلیل بازارهای مالی کاربردهای متنوعی دارد. سیستمهای خودکار پاسخدهی میتوانند با دسترسی به پایگاه دانش محصولات، پاسخهای دقیقتری ارائه دهند.
تحلیل اسناد و مدارک
در حوزه حقوقی و پزشکی، RAG امکان تحلیل سریع اسناد پیچیده و ارائه خلاصههای جامع را فراهم میکند.
آموزش شخصیسازیشده
سیستمهای آموزشی مبتنی بر RAG قادر به ارائه محتوای آموزشی متناسب با نیاز و سطح دانش هر فرد هستند.
تحقیق و توسعه
مدلهای RAG در حال پیشرفت هستند و این مدلها پردازش زبان طبیعی را با بازیابی اطلاعات ترکیب میکنند، که برای محققان ابزاری قدرتمند محسوب میشود.
چالشهای فنی و عملیاتی
پیچیدگی معماری
طراحی و پیادهسازی سیستمهای RAG نیازمند تخصص بالا در زمینههای مختلف از جمله یادگیری ماشین، پایگاههای داده و مهندسی نرمافزار است.
مدیریت کیفیت داده
کیفیت خروجی RAG مستقیماً به کیفیت دادههای ورودی وابسته است. نیاز به پاکسازی، سازماندهی و بهروزرسانی مداوم اطلاعات از چالشهای اصلی محسوب میشود.
هزینه محاسباتی
این معماری سیستم جستجوی معنایی بسیار مقیاسپذیر و کمتأخیر برای قدرتدهی به مدلهای RAG نسل بعد فراهم میکند، اما نیازمند منابع محاسباتی قابل توجهی است.
حفظ حریم خصوصی
استفاده از دادههای حساس در سیستمهای RAG مسائل امنیتی و حریم خصوصی را مطرح میکند که نیاز به راهحلهای پیچیده دارد.
تکنولوژیهای پیشرفته در RAG
RAG عاملی (Agentic RAG)
چارچوبهای RAG عاملی و کتابخانهها، تفاوتهای کلیدی با RAG استاندارد، مزایا و چالشها برای باز کردن پتانسیل کامل آنها نسل جدیدی از سیستمهای هوشمند را معرفی میکند.
ادغام با تکنولوژیهای نوظهور
RAG با تکنولوژیهای دیگر مانند پردازش تصویر، تشخیص صدا و اینترنت اشیا (IoT) ترکیب میشود تا راهحلهای جامعتری ارائه دهد.
آینده و روندهای توسعه
RAG به عنوان سرویس
RAG به عنوان سرویس: مزایا، موارد استفاده و چالشها نشاندهنده تمایل بازار به ارائه راهحلهای آماده و قابل دسترس است.
استانداردسازی
وضعیت RAG در سال 2025: پل زدن بین دانش و هوش مصنوعی تولیدی حکایت از رشد سریع و استانداردسازی این تکنولوژی دارد.
توسعه ابزارها و چارچوبها
بهترین ابزارهای RAG: چارچوبها و کتابخانهها در سال 2025 نشان میدهد که اکوسیستم ابزارهای RAG در حال گسترش سریع است.
نتیجهگیری
تکنولوژی RAG به عنوان یکی از مهمترین نوآوریهای حوزه هوش مصنوعی، توانسته محدودیتهای اساسی مدلهای زبانی بزرگ را برطرف کند. ترکیب قدرت تولید متن با دسترسی به اطلاعات بهروز و دقیق، فرصتهای بینظیری برای توسعه کاربردهای هوشمند فراهم کرده است.
علیرغم چالشهای موجود در زمینه پیچیدگی فنی و هزینه پیادهسازی، مزایای قابل توجه RAG از جمله بهبود دقت، انطباقپذیری بالا و امکان بهروزرسانی مداوم دانش، آن را به انتخابی جذاب برای سازمانها و توسعهدهندگان تبدیل کرده است.
با توجه به روند رو به رشد تقاضا برای سیستمهای هوشمند و پیشرفتهای مداوم در زمینه ابزارها و چارچوبهای توسعه، انتظار میرود که RAG نقش محوری در شکلگیری آینده هوش مصنوعی ایفا کند. سرمایهگذاری در تحقیق و توسعه این تکنولوژی، علاوه بر ایجاد مزیت رقابتی، زمینه را برای نوآوریهای بیشتر در این حوزه فراهم خواهد کرد.